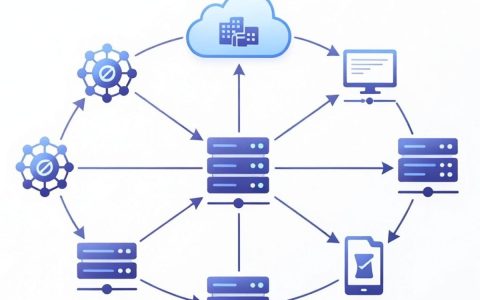
车载语音大模型的技术实现核心,在于彻底重构了传统车载语音交互的底层逻辑,即从“基于指令匹配的机械执行”转向“基于语义理解的智能生成”,传统车载语音系统受限于固定词槽和语法规则,无法处理复杂长句和模糊意图,而大模型技术通过海量参数训练,实现了对上下文、多轮对话及模糊指令的深度理解,让车载语音助手真正具备了“拟人化”的交互能力。这一技术变革的实现路径,主要依赖于端云协同架构设计、多模态感知融合、以及车控API的语义对齐三大关键环节。

底层架构革新:端云协同的算力博弈
车载场景对实时性和稳定性有着极高的要求,这决定了车载语音大模型不能完全依赖云端部署。
- 云端大模型负责“大脑”:云端部署千亿级参数的超大模型,负责处理极其复杂的逻辑推理、知识问答以及非结构化的生成式任务,当用户询问“找一家评分高且有充电桩的餐厅”时,云端大模型需要结合地图数据、用户历史偏好和互联网信息进行综合推理。
- 车端小模型负责“反射”:为了解决网络延迟和断网场景下的可用性问题,车端通常部署轻量化的小模型(如7B或13B参数量级)。车端模型主要处理低延迟的离线指令,如“打开车窗”、“调节空调”等高频控制指令,确保在隧道、地下车库等弱网环境下,语音交互依然秒级响应。
- 端云无缝切换机制:技术实现的难点在于如何判断何时上云、何时本地处理,系统通过意图分类器对用户指令进行初步分流,简单指令本地闭环,复杂指令云端处理,并通过流式传输技术,让用户在云端结果返回前就能听到首字响应,消除等待感。
核心技术链路:从信号输入到意图执行
要真正实现一文读懂车载语音大模型原理的技术实现,必须深入剖析其信号处理与决策链条,这一过程并非简单的“语音转文字”,而是一个包含多模态感知的复杂系统。
- 前端信号处理(AEC与降噪):车内环境嘈杂,胎噪、风噪、音乐声严重干扰语音识别,技术实现上,首先通过多麦克风阵列进行声源定位,利用AEC(声学回声消除)算法剔除音响播放的音乐,再通过深度学习降噪模型提取纯净的人声信号。
- ASR与多模态融合:自动语音识别(ASR)将声音转为文本,但大模型时代的车载语音不再仅依赖文本。视觉大模型会同步捕捉驾驶员的眼神注视方向和唇部动作,当驾驶员看向副驾屏幕并说“关闭这个”,系统会结合视线锁定目标屏幕;若驾驶员嘴型未动但系统收到“打开天窗”的语音,则会被判定为误触发或第三方干扰,极大提升了抗干扰能力。
- 大模型语义理解与推理:这是大模型区别于传统NLP(自然语言处理)的核心,传统NLP遇到“我有点冷”可能无法匹配到具体指令,而大模型能基于常识推理出需要“调高空调温度”,技术实现上,利用Prompt Engineering(提示词工程)将车辆状态、控制接口文档注入大模型上下文,使其具备车辆控制的知识背景。
车控落地的关键:Function Call与API映射

大模型生成的是自然语言文本,车辆控制器只能识别标准的API调用指令,如何打通两者,是技术实现的最后一公里。
- API函数调用:将车辆能力(如空调、车窗、座椅)封装成标准化的API函数描述,作为工具包提供给大模型,当用户发出指令时,大模型并不直接操作硬件,而是输出结构化的函数调用指令(如
{"action": "set_temperature", "value": 26}),再由中间件层解析并下发给车身域控制器。 - 模糊指令纠错与确认:针对“车窗开大一点”这种模糊指令,传统系统往往无法执行,大模型则会结合当前车窗开度(如开度30%),推理出合理的执行参数(如调整至60%),或者主动发起澄清:“车窗目前开度较小,为您开到一半可以吗?”
- 安全围栏机制:为了防止大模型“幻觉”导致危险操作(如行驶中误解锁车门),技术实现上必须设置硬编码的安全规则。所有涉及行车安全的API调用,必须在中间件层进行二次校验,一旦触发安全红线(如行车中打开后备箱),大模型的指令将被拦截,确保系统安全可控。
持续进化的闭环:RAG与个性化记忆
车载语音大模型并非一成不变,它具备持续学习和个性化适配能力。
- 检索增强生成(RAG):车辆说明书、保养手册等私有数据无法全部训练进模型,通过RAG技术,系统可以实时检索车辆知识库,准确回答“仪表盘黄色感叹号是什么意思”等具体车辆问题,解决了大模型知识滞后和胡编乱造的问题。
- 用户画像与长期记忆:大模型能够建立用户画像,记住用户的偏好,用户习惯在周五晚上去健身房,当周五晚上用户说“导航去老地方”,系统能基于历史记忆准确推荐健身房,而非机械地询问“请问老地方是哪里”。
车载语音大模型的技术实现,是一场涉及算力架构、算法模型、硬件控制与安全策略的系统性工程,它不仅需要大模型强大的语义理解能力,更需要精细的工程化手段来适配汽车这一特殊场景,最终实现从“听懂指令”到“读懂用户”的跨越。
相关问答

问:车载语音大模型在断网情况下还能正常使用吗?
答:可以,但功能会有所限制,基于端云协同架构,高频使用的车辆控制功能(如空调、车窗、灯光控制)和部分本地音乐播放,通常由车端部署的轻量化模型处理,在断网时依然可用,但涉及互联网搜索、复杂知识问答等需要云端算力的功能,在断网时将无法响应。
问:大模型上车会不会导致车辆被黑客攻击的风险增加?
答:安全风险确实存在,但技术上也做了多重防护,除了常规的数据加密传输,车载大模型在执行关键动作时采用了“沙箱隔离”和“权限分级”策略,特别是涉及车辆控制的指令,并非由大模型直接驱动硬件,而是通过中间件的安全校验层进行转发,任何不符合安全逻辑的指令都会被底层拦截,从而保障车辆控制权的安全。
如果您对车载语音大模型的技术细节有更多见解,欢迎在评论区留言讨论。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/101589.html