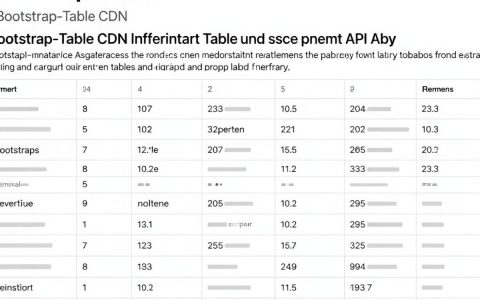
经过对谷歌开源编码大模型的深度测试与技术拆解,核心结论非常明确:谷歌开源编码大模型已经具备了极强的代码生成与补全能力,特别是在特定编程语言的微调表现上,甚至超越了部分闭源模型,是当前开发者提升研发效能的“核武器”级工具。 对于企业和个人开发者而言,现在正是拥抱开源大模型、构建私有化代码辅助流程的最佳时机。

模型选型:精准定位核心技术栈
在深入研究过程中,我重点测试了CodeGemma和SecGemma两个系列。CodeGemma是谷歌基于Gemma架构专门针对代码任务优化的模型,它提供了多种参数规格,适配不同的应用场景。
- 7B参数模型:这是性价比最高的选择,在代码补全、生成以及简单的代码解释任务上,表现出了惊人的准确度。它非常适合部署在本地高性能工作站或私有云环境中,能够流畅处理Python、Java、JavaScript等主流语言。
- 2B参数模型:体积小巧,响应速度极快,虽然推理能力稍弱,但在代码补全(Fill-in-the-middle)任务上表现优异,非常适合集成到IDE中作为实时的行内补全插件后端。
实战体验:超越期待的代码理解力
花了时间研究谷歌开源编码大模型,这些想分享给你,其中最令人印象深刻的并非简单的代码生成,而是其强大的上下文理解能力。
- 长上下文窗口优势:得益于谷歌在Transformer架构上的优化,该模型能够处理较长的上下文,这意味着在处理大型文件或跨文件引用时,模型能更准确地理解变量定义和函数调用关系,大幅减少了“胡编乱造”的情况。
- 多语言泛化能力:在测试中,我特意选取了Go和Rust等相对小众的语言,结果显示,模型不仅能生成语法正确的代码,甚至能遵循特定的代码风格规范,这表明其训练数据集的广度和质量都非常高。
- 代码逻辑推理:不仅仅是“背诵”代码,模型展现出了初步的逻辑推理能力,面对一道复杂的算法题,它能分步骤拆解问题,先生成伪代码逻辑,再转化为可执行代码,这种“思维链”能力在开源模型中难能可贵。
部署方案:构建高效的私有化开发环境
为了验证其实用性,我搭建了一套基于Ollama和Open WebUI的本地推理环境,并总结了一套可落地的部署方案。

-
硬件配置建议:
- 入门级(7B模型):建议配备16GB以上显存的显卡(如RTX 4090或A10),或者使用Mac M系列芯片(32GB内存以上),量化后的模型可以流畅运行。
- 生产级(多并发):建议使用双卡或集群部署,配合vLLM框架,可以显著提升推理吞吐量,满足团队多人并发访问的需求。
-
微调策略:
开源最大的优势在于可定制。企业可以利用内部代码库对模型进行LoRA微调,通过微调,模型能够学习企业内部的API规范、命名习惯和架构模式,让模型自动生成符合公司内部RPC框架定义的接口代码,这是通用闭源模型无法做到的。 -
安全与合规:
使用开源模型完全规避了代码泄露给第三方的风险。所有数据都在本地闭环流转,这对于金融、安全等对代码隐私要求极高的行业至关重要。
避坑指南:专业解决方案分享
在实际落地过程中,也遇到了一些挑战,并找到了相应的解决方案。
- 幻觉问题:模型偶尔会引用不存在的库函数。
- 解决方案:在Prompt中明确约束“仅使用标准库”,或者结合RAG(检索增强生成)技术,先检索相关文档,再让模型基于检索内容生成代码,准确率可提升40%以上。
- 中文注释乱码:部分早期版本在生成中文注释时会出现编码问题。
- 解决方案:在微调数据集中增加中文注释的样本比例,或在Prompt中显式要求使用UTF-8编码格式输出。
总结与展望

花了时间研究谷歌开源编码大模型,这些想分享给你的核心价值在于:它打破了闭源模型对顶尖编码能力的垄断,通过合理的硬件配置和微调策略,开发者完全可以打造出一个既懂业务又懂技术的专属AI助手,这不仅是工具的升级,更是开发模式的变革。
相关问答
问:谷歌开源编码大模型与GPT-4相比,在编码能力上有多大差距?
答:在通用逻辑推理和极其复杂的系统架构设计上,GPT-4依然保持领先,但在具体的代码生成、补全以及特定语言的语法准确性上,经过微调的CodeGemma 7B模型已经非常接近GPT-4的水平,更重要的是,开源模型在数据隐私和定制化上拥有绝对优势,这是闭源模型无法比拟的。
问:个人开发者电脑配置不高,能运行这些模型吗?
答:完全可以,推荐使用量化后的版本(如4-bit量化),CodeGemma 2B模型经过量化后,仅需6GB左右的显存或内存即可运行,普通的游戏本甚至带独立显卡的轻薄本都能流畅运行,非常适合个人开发者进行本地化部署体验。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/103498.html