全球AI大模型测试的整体表现呈现出“技术天花板不断抬升,但落地应用体验参差不齐”的核心态势。目前的测试结果表明,头部大模型在逻辑推理、代码生成等硬核指标上已接近甚至超越人类平均水平,但在情感交互、个性化服务及特定垂直领域的准确性上,仍存在明显的短板。 消费者真实评价从最初的“猎奇尝鲜”逐渐转向“实用主义”,用户不再仅仅满足于AI能写一首诗,而是更关注它能否精准解决工作流中的实际问题。对于普通用户而言,选择大模型不应盲目迷信跑分榜单,而应结合具体应用场景进行实测,重点关注其稳定性与容错率。

权威测试数据透视:技术指标与实战能力的“剪刀差”
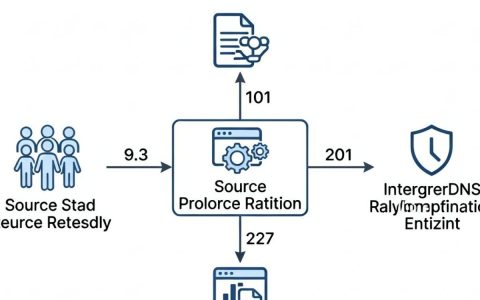
全球范围内,针对AI大模型的测试体系主要分为学术基准测试与真实场景评测两大类。
-
学术基准测试的“含金量”与局限
在MMLU(大规模多任务语言理解)、GSM8K(数学推理)等权威榜单上,GPT-4、Claude 3以及国内的文心一言、通义千问等头部模型频频刷新纪录。
数据显示,顶级大模型在MMLU上的得分已突破80分大关,这意味着在通识知识领域,AI已具备极高的理论储备。
学术测试存在“应试教育”嫌疑,部分模型针对特定榜单进行了过拟合训练,导致榜单成绩优异,但在处理用户复杂、模糊的真实指令时,表现却大打折扣。 -
多模态能力的实战考验
当前的全球AI大模型测试已不再局限于文本,图像生成与理解能力成为新的竞技场。
测试发现,虽然AI生成的图像逼真度极高,但在处理图文混合文档、复杂图表数据提取时,错误率依然较高。
消费者真实评价中,图片理解张冠李戴”或“图表数据提取不准”的反馈频次较高,这表明多模态技术虽已落地,但尚未达到完全可靠的商用标准。
消费者真实评价画像:从“惊艳”到“挑刺”的转变
通过分析社交媒体、科技论坛及应用商店的数万条评论,可以清晰地勾勒出消费者对AI大模型的认知变化曲线。
-
生产力场景:效率提升与“幻觉”隐忧并存
程序员、文字工作者是AI大模型的核心用户群。
绝大多数正面评价集中在“代码补全效率提升50%以上”以及“文案大纲快速生成”等功能上。
但与此同时,“一本正经地胡说八道”(AI幻觉)仍是用户最大的痛点。 在医疗、法律等专业领域,消费者对AI生成内容的信任度普遍较低,真实评价显示,用户往往需要花费大量时间去核实AI输出的准确性,这在一定程度上抵消了效率红利。 -
情感与创意场景:缺乏“人味”是硬伤
在角色扮演、心理咨询陪聊等场景中,消费者对AI的评价呈现出两极分化。
一部分用户认为AI提供了极佳的情绪价值,随时随地响应;另一部分深度用户则指出,AI的回复往往过于程式化、套路化,缺乏真正的共情能力。
在创意写作方面,虽然AI能快速产出内容,但被多次批评为“辞藻堆砌,逻辑空洞”,难以替代人类的深度思考。 -
本土化体验:中文语境下的独特优势
值得注意的是,在全球ai大模型测试怎么样?消费者真实评价这一议题中,国产大模型在中文语境下的表现获得了较高认可。
用户反馈表明,国产头部模型在理解中国传统文化梗、公文写作规范及本地化生活服务指令上,往往比海外模型更接地气,这种“本地化红利”成为国产模型争夺用户的关键筹码。
深度解析:影响用户体验的核心痛点
为什么技术指标不断提升,用户体验却仍有落差?这背后存在三个核心矛盾。
-
算力成本与响应速度的博弈
为了追求更高的智商,模型参数量级不断膨胀,导致推理成本激增。
消费者真实评价中,生成速度慢”、“高峰期排队”的抱怨屡见不鲜。
许多厂商在速度与质量之间被迫做取舍,导致用户在高峰期体验到的往往是“降智版”模型。 -
上下文窗口的“遗忘”难题
虽然各大厂商宣称支持超长上下文(如100万token),但在实际测试中,随着对话轮次增加,AI极易“遗忘”之前的设定。
这种“长文本处理能力的虚标”现象,严重影响了用户进行长篇文档分析和连续创作的体验。 -
数据安全与隐私顾虑
在企业级应用中,消费者对数据泄露的担忧始终存在。
真实评价显示,不少企业员工被禁止将敏感数据投喂给公共大模型,这直接限制了AI在核心业务流程中的渗透率。
专业解决方案:如何科学选择与使用AI大模型
面对纷繁复杂的模型版本和测试数据,用户应建立一套科学的评估体系。
-
建立“场景化测试集”
不要轻信通用的跑分数据。建议用户根据自身高频需求,构建专属的测试集。
HR可准备几份真实简历让AI分析;程序员可提交一段复杂代码让AI找Bug,通过对比不同模型在特定任务上的输出质量、速度和稳定性,筛选出最适合自己的工具。 -
掌握提示词工程技巧
同一个大模型,不同的提问方式会得到截然不同的结果。
消费者应学习“结构化提示词”写法,通过明确角色、背景、任务目标和约束条件,引导AI输出高质量内容。 这不仅是工具的使用技巧,更是未来人机协作时代的基本素养。
-
善用RAG(检索增强生成)技术
针对AI幻觉问题,用户应优先选择支持联网搜索或文档上传功能的模型。
通过引入外部知识库辅助AI生成答案,可大幅降低“胡编乱造”的概率,提升回答的可信度。
未来展望:从“大模型”到“智能体”
全球AI大模型测试的下一阶段,将聚焦于Agent(智能体)能力。
未来的AI将不再仅仅是回答问题的“百科全书”,而是能够自主规划、调用工具、执行复杂任务的“行动派”。
消费者评价的焦点也将从“回答得对不对”转向“事情办得漂不漂亮”。 这一转变将彻底重塑人机交互模式,推动AI真正融入社会生产生活的毛细血管。
相关问答模块
全球AI大模型测试结果是否能代表实际使用体验?
答:不完全代表,测试结果多基于标准化的学术数据集,侧重于模型的知识储备和逻辑推理上限,而实际使用体验受网络环境、提示词质量、具体应用场景及模型推理速度等多种因素影响。建议将测试结果作为参考基准,重点结合自身需求进行小范围实测。
面对众多AI大模型,普通消费者应如何选择?
答:遵循“按需选择”原则,如果是处理中文公文、了解国内资讯,国产头部模型更具优势;如果是进行复杂的代码开发或英文科研辅助,海外顶级模型目前仍略胜一筹。关注各模型的免费额度、响应速度及隐私政策,选择综合性价比最高的产品。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/107846.html