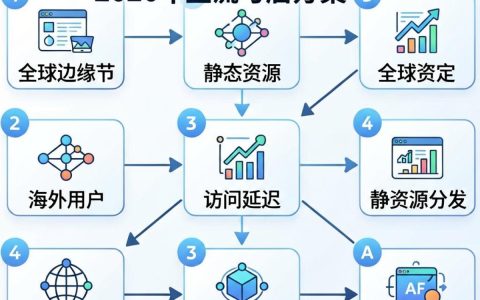
搭建开源AI大模型,真正的门槛从来不是下载模型代码,而是算力成本、数据工程与持续运维的“深坑”。核心结论非常直接:对于绝大多数企业和个人开发者而言,盲目本地化部署开源大模型往往是“入不敷出”的伪需求,真正的破局点在于“场景化微调”与“算力成本控制”的极致平衡。 只有在数据隐私极度敏感、或拥有垂直领域独家数据的场景下,自建开源大模型才具备真正的ROI(投资回报率)。

算力成本:不仅要看“入场券”,更要看“水电费”
很多人对搭建开源AI大模型存在严重的认知误区,认为只要有一张高端显卡就能跑起来。
- 显存是硬通货。 运行一个参数量7B的模型,推理至少需要6GB-8GB显存,但这仅仅是能“跑通”的门槛,一旦并发请求增加,显存消耗呈线性增长,若要微调,显存需求更是推理的数倍。
- 推理成本高昂。 搭建开源AI大模型并非一劳永逸,以LLaMA-3-70B为例,要达到流畅的商用推理效果,通常需要双卡A800或H800。硬件采购成本动辄数十万,这还没算上每年几万元的电费与机房运维成本。
- 量化不是万能药。 虽然INT4、INT8量化技术能降低显存占用,但会显著牺牲模型智商,在复杂的逻辑推理任务中,量化后的开源模型往往会出现严重的“降智”现象,难以满足专业场景需求。
数据工程:决定模型上限的“隐形壁垒”
模型架构可以开源,但喂给模型的数据无法开源。关于搭建开源ai大模型,说点大实话,90%的失败案例都死于“垃圾进,垃圾出”。
- 数据清洗极其繁琐。 开源模型底座通用性强,但缺乏行业Know-how,想要让模型懂业务,必须投入大量人力进行数据清洗、去重和格式化,这比写代码要昂贵得多。
- 微调技术的陷阱。 全量微调成本极高,LoRA等高效微调技术虽然降低了门槛,但容易导致模型“遗忘”通用能力,如何在保留通用智商的同时注入专业知识,是目前技术攻关的难点。
- 数据隐私悖论。 很多企业选择自建是为了隐私,但在数据预处理阶段,往往缺乏严格的脱敏流程。如果数据治理不规范,自建模型反而可能成为内部数据泄露的源头。
技术架构与运维:从Demo到生产的鸿沟

跑通一个Gradio Demo只需半小时,但将其转化为高可用的生产级服务,需要跨越数道难关。
- 推理框架的选择。 直接使用HuggingFace Transformers加载模型效率极低,生产环境必须掌握vLLM、TGI或TensorRT-LLM等高性能推理框架。这些框架配置复杂,版本依赖严重,对工程师的底层技术要求极高。
- 并发与调度。 当多个用户同时访问时,如何进行请求批处理?如何管理KV Cache?如何实现多卡负载均衡?这些问题不解决,模型服务在高峰期会直接崩溃。
- 模型更新迭代。 开源社区迭代速度极快,LLaMA、Qwen、Mistral等模型月月更新。自建系统意味着要不断进行模型迁移、权重转换和效果评测,这是一场没有终点的长跑。
务实的解决方案:构建高性价比的AI落地路径
基于上述痛点,建议采取更务实的策略,避免陷入技术自嗨。
- 优先使用API,其次才自建。 在验证业务场景阶段,直接调用GPT-4或Claude API,只有当日均调用量巨大导致API成本不可控,且数据确需本地化时,才考虑开源方案。
- 采用“小模型+RAG”架构。 不要迷信千亿参数大模型,对于垂直领域,一个经过精调的7B-13B模型,配合检索增强生成(RAG)技术,效果往往优于通用大模型,且成本降低一个数量级。
- 云原生部署策略。 不要盲目购买物理服务器,利用云厂商的GPU按需租赁服务进行微调训练,利用Spot实例进行推理,能将初期投入成本降低70%以上。
搭建开源AI大模型是一场涉及算力、算法、数据和工程的系统工程。不要为了“拥有”而搭建,要为了“解决问题”而搭建。 只有在算力成本可控、数据资产独有、技术架构稳健的前提下,开源大模型才能真正转化为生产力,而非企业的成本黑洞。
相关问答

问:企业没有GPU服务器,如何低成本开始搭建开源大模型?
答:建议采用“云端微调+本地/云端推理”的混合模式,利用云平台的按量付费GPU资源进行模型微调,训练完成后导出权重,推理阶段可根据数据敏感性,选择租用高性能云GPU实例或采购消费级显卡工作站,避免一次性重资产投入。
问:开源大模型在垂直行业应用中,效果不如GPT-4怎么办?
答:这是正常现象,开源模型通用逻辑能力弱于GPT-4,但在垂直领域有反超机会,核心策略是:第一,构建高质量的行业指令微调数据集;第二,引入RAG技术,让模型外挂行业知识库;第三,优化Prompt工程,引导模型聚焦特定任务,通过这三步,小参数的开源模型在特定任务上完全可以超越通用闭源大模型。
如果您在搭建开源大模型过程中有独特的经验或踩过更深的坑,欢迎在评论区留言交流。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/113801.html