智慧矿山AI大模型的核心本质,是利用人工智能技术对矿山海量数据进行深度学习,从而实现对矿山生产全流程的感知、决策与控制,它并非遥不可及的“黑科技”,而是矿山数字化转型的必经之路。它就是矿山行业的“超级大脑”,将原本分散、孤立的系统打通,实现从“人控”到“数控”再到“智控”的根本性转变。

许多人认为智慧矿山AI大模型高深莫测,一篇讲透智慧矿山ai大模型,没你想的复杂,其底层逻辑依然遵循“数据-算法-算力”的铁律,只是应用场景从通用的互联网领域切换到了专业的矿山场景。
核心价值:解决矿山“安全与效率”的终极痛点
智慧矿山AI大模型存在的意义,不是为了炫技,而是为了解决实际问题。
安全生产的“守护神”
矿山作业环境恶劣,透水、瓦斯爆炸、顶板坍塌等风险时刻威胁着矿工生命,传统监控往往依赖人工盯屏,效率低且易疲劳漏报。
AI大模型通过接入视频流和传感器数据,能够7×24小时实时识别违章行为、设备异常和环境风险。 当矿工未佩戴安全帽或进入危险区域时,模型能在毫秒级内发出警报,将事故隐患扼杀在萌芽状态。
生产效率的“加速器”
在采掘环节,传统采煤机依赖人工操作,精度难以保证,且容易造成资源浪费。
AI大模型通过学习历史开采数据和地质模型,能够自动规划最优切割路径,实现“记忆截割”。 这不仅降低了工人的劳动强度,更将采煤效率提升了20%以上,真正实现了“少人则安、无人则安”。
技术架构:三层金字塔构建智慧基石
要理解智慧矿山AI大模型,必须看懂其背后的技术架构,这并非杂乱无章的技术堆砌,而是有着严密的层级关系。
感知层:全方位的“五官”
感知层是智慧矿山的“眼睛”和“耳朵”,它包括部署在矿井下的高清摄像机、激光雷达、各类传感器(瓦斯、一氧化碳、温湿度等)。
这一层的核心任务是解决“数据从哪里来”的问题。 通过高精度的采集设备,将物理世界的矿山映射为数字世界的“数据矿山”。
平台层:强大的“大脑”
平台层是AI大模型的核心所在,通常部署在矿山数据中心或云端,它包含算力基础设施和算法模型库。
这里不仅存储着海量的矿山数据,更运行着针对特定场景训练的AI算法。 针对皮带输送机的“大块煤识别算法”、针对综采工作面的“液压支架自动跟机算法”,大模型通过海量数据训练,具备了泛化能力,能适应不同矿区的复杂地质条件。
应用层:灵活的“手脚”
应用层直接面向业务人员,包括集控中心大屏、手持终端、智能设备控制系统等。
这一层将“大脑”的决策转化为实际行动。 集控员在地面只需轻点鼠标,井下的采煤机、掘进机便能自动运转;管理人员通过手机APP就能实时查看产量报表和安全态势。

落地挑战与专业解决方案:打破“数据孤岛”是关键
虽然前景广阔,但智慧矿山AI大模型的落地并非一帆风顺。在实际项目中,最大的阻碍往往不是技术本身,而是数据治理的缺失。
挑战:数据孤岛与标准不一
许多矿山企业早期建设了多个独立的子系统(如人员定位、视频监控、安全监测等),这些系统往往由不同厂家承建,数据格式各异,接口标准不统一。
这导致数据无法互通,AI大模型缺乏足够的“养分”进行训练,变成了“数据贫瘠”的模型。
解决方案:构建统一数据底座
针对这一痛点,必须建立统一的矿山数据治理标准和数据中台。
- 统一标准: 制定矿山数据编码规范,确保所有子系统“书同文、车同轨”。
- 数据清洗: 对原始数据进行去噪、补全和标准化处理,提升数据质量。
- 融合共享: 打通业务壁垒,让地质、测量、采掘、通防等数据在统一平台上流动,为AI大模型提供高质量的训练样本。
只有打好数据底座,AI大模型才能真正发挥威力,否则就是空中楼阁。
未来展望:从“单点智能”迈向“全域智慧”
当前的智慧矿山AI大模型,更多是在解决单点场景的智能化问题,如智能视频监控、智能采煤等,未来的发展方向,将是构建“矿山全场景大模型”。
跨模态融合
未来的大模型将具备处理文本、图像、视频、传感器数据等多种模态信息的能力。
当设备出现故障时,维修人员只需语音提问,大模型便能自动调取相关图纸、维修记录和实时视频,给出精准的维修建议。
生成式AI的应用
利用生成式AI技术,大模型可以根据地质勘探数据,自动生成矿井设计图纸和开采方案,大幅缩短设计周期。
这将彻底改变矿山工程师的工作模式,从繁琐的绘图和计算中解放出来,专注于方案优化和决策。
一篇讲透智慧矿山ai大模型,没你想的复杂,关键在于剥离技术的神秘外衣,回归业务本质,它不是一蹴而就的魔法,而是一场涉及技术、管理、流程的深刻变革,只要遵循科学的方法论,打好数据基础,选准应用场景,任何矿山企业都能搭上这趟智能化的快车。

相关问答
问:中小型矿山企业资金有限,如何低成本落地AI大模型?
答:中小型矿山不必追求“大而全”的建设模式,建议采用“小步快跑、分步实施”的策略。
- 优先解决痛点: 选择安全风险最高、人工效率最低的环节(如主煤流运输系统的异物识别)进行试点。
- 利用云端资源: 不必自建昂贵的数据中心,可以租用云服务商的算力资源,按需付费,降低初始投入。
- 选用标准化产品: 尽量采购成熟的、标准化的AI算法盒子或软件套件,避免定制化开发带来的高昂成本。
问:AI大模型在井下无网络环境如何工作?
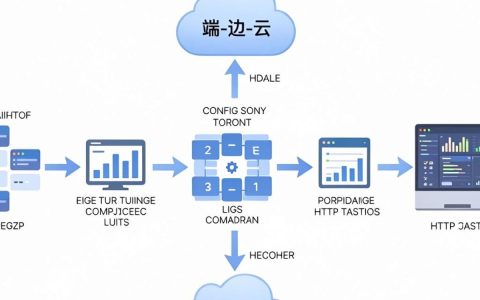
答:这是矿山行业的特殊痛点,通常采用“云-边-端”协同架构解决。
- 边缘计算: 在井下部署边缘计算主机,将核心AI算法下沉到边缘端,即使断网,边缘主机也能独立运行,保障实时控制和安全监测。
- 数据缓存: 边缘设备具备数据缓存功能,网络恢复后自动将数据上传至云端进行模型优化和迭代。
- 5G专网: 利用5G技术大带宽、低时延的特性,构建井下高速通信网络,解决数据传输瓶颈。
您对智慧矿山AI大模型的应用还有哪些疑问?欢迎在评论区留言交流。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/115939.html