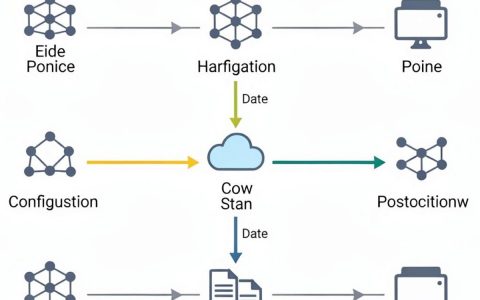
领域大模型的核心本质,并非简单的“通用大模型+行业数据”的物理堆砌,而是一场从“通才”向“专才”跨越的化学反应。真正的领域大模型,必须具备在特定垂直场景下解决实际问题的深度能力,其判断标准不在于参数规模的庞大,而在于对行业Know-how(知识诀窍)的理解精度与业务流程的嵌入深度。 它不是用来炫技的玩具,而是降本增效的生产力工具,其价值在于用最少的算力、最精准的输出,解决最棘手的行业痛点。

拒绝概念炒作:领域大模型的“真实面目”
市面上充斥着大量伪领域模型,本质只是通用模型穿了件“行业马甲”。
- 数据维度的“伪定制”: 许多号称领域大模型的产品,仅仅是在通用语料基础上,微调了少量的行业公开数据,这种做法如同给小学生塞了几本医学教材,看似懂术语,实则无医术。真正的领域大模型,其训练数据必须包含高质量、多模态的行业核心数据,包括非结构化的专家经验、操作手册、故障日志等私有数据。
- 能力维度的“幻觉陷阱”: 通用模型在开放域问答中表现优异,但在垂直领域往往面临严重的“幻觉”问题,例如在法律领域,通用模型可能编造不存在的法条。领域大模型的硬指标是“可控性”,必须能够精准调用行业知识库,拒绝回答非领域问题,确保输出的合规性与准确性。
- 成本维度的“算力博弈”: 并非参数越大越好,在工业质检、金融风控等场景,千亿参数模型不仅部署成本高昂,推理速度也难以满足实时性要求。优秀的领域大模型,往往通过剪枝、量化等技术,将模型压缩至百亿甚至更小参数,在边缘端即可高效运行。
技术硬核拆解:如何炼成“行业专家”
构建一个合格的领域大模型,是一项系统工程,而非简单的微调任务。
- 数据清洗是第一道门槛: 行业数据往往脏乱差,充满了噪声。数据清洗的质量直接决定了模型的上限。 需要建立严格的数据治理流水线,剔除低质量数据,保留高价值密度信息,例如在医疗领域,病例数据的脱敏、标准化处理,往往占据项目60%以上的时间。
- 增量预训练与指令微调: 仅靠RAG(检索增强生成)无法解决所有问题。必须进行增量预训练,将行业知识注入模型底座,再通过高质量指令微调(SFT),让模型学会行业思维逻辑。 这就像不仅要让模型背下医书,还要通过临床案例教会它如何看病。
- 评测体系的建立: 通用榜单(如C-Eval)无法衡量领域模型的真实水平。企业必须构建私有评测集,引入业务专家进行人工评测。 只有在特定任务上(如合同审查、代码生成、故障诊断)达到专家级水平,才算合格的领域大模型。
关于什么叫领域大模型,说点大实话,它本质上是一个“知识工程”问题,而非单纯的算法问题。 技术栈的选择、基座模型的挑选,都服务于“如何高效沉淀并复用行业知识”这一核心目标,如果忽视了知识工程的建设,再先进的算法也只是空中楼阁。
落地实战:避开“伪需求”的深坑

领域大模型的价值落地,必须遵循“场景为王”的原则,拒绝为了AI而AI。
- 识别高价值场景: 并非所有场景都适合大模型。高价值场景通常具备三个特征:知识密集、流程复杂、容错率低。 智能客服属于知识密集型,但容错率相对较高;而新药研发则三者兼备,价值巨大,企业应优先选择痛点明显、数据基础好的场景切入。
- 人机协作的Copilot模式: 不要幻想模型能完全替代人。当前最成熟的落地形态是Copilot(副驾驶)模式。 模型负责信息检索、初稿生成、异常检测,人类专家负责审核、决策,这种模式既能提升效率,又能控制风险。
- 安全与隐私的红线: 数据安全是领域大模型落地的“生死线”。企业必须掌握数据主权,采用私有化部署或行业云方案,防止核心资产泄露。 模型输出内容需经过敏感词过滤、合规审查,避免法律风险。
行业变革:从“工具”到“基础设施”
领域大模型的终局,将成为行业数字化转型的核心基础设施。
- 重构知识管理体系: 传统知识管理依赖文档库、知识库,检索效率低。领域大模型将非结构化数据转化为可计算、可推理的知识图谱,实现了知识的动态调用与生成。 这意味着企业的隐性经验得以显性化、资产化。
- 重塑业务流程: 以金融投研为例,传统流程是分析师阅读研报、撰写笔记、搭建模型。引入领域大模型后,信息抽取、观点生成、数据清洗均可自动化,分析师只需专注于核心逻辑判断。 业务流程从“人力驱动”转变为“人机协同驱动”。
- 催生新商业模式: 垂直行业将涌现出大量MaaS(模型即服务)提供商。拥有独特数据资产的企业,将通过领域大模型开放API能力,构建行业生态。 律所可以基于自有案例库训练模型,向中小机构提供智能法律咨询服务。
相关问答
中小企业数据量有限,是否适合构建自己的领域大模型?
中小企业直接训练基座模型既不现实也无必要,最佳策略是利用开源基座模型,结合RAG(检索增强生成)技术,通过构建高质量的企业知识库来实现智能化。核心在于沉淀企业内部的独有文档和业务流程数据,而非追求模型参数的规模。 这种方式成本低、见效快,且数据完全可控。

领域大模型与通用大模型在应用效果上最大的区别是什么?
最大的区别在于“专业深度”与“落地成本”,通用大模型像是一个博学的通才,什么都知道一点,但在专业问题上容易一本正经地胡说八道。领域大模型则是经过特训的专才,在特定任务上的准确率、响应速度远超通用模型,且幻觉率大幅降低。 在实际业务中,领域大模型的可用性、可靠性是通用模型无法比拟的。
您所在的行业是否已经感受到了领域大模型带来的冲击?欢迎在评论区分享您的看法。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/116226.html