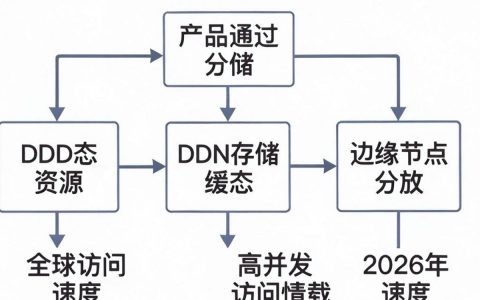
大模型并发的核心在于算力资源的极致压榨与显存瓶颈的系统性突破,我认为,实现高效并发并非单纯堆砌硬件,而是通过模型并行、流水线调度及显存优化三大技术支柱,构建起一套严密的资源调度体系。关于大模型是如何并发,我的看法是这样的:它本质上是一场在有限硬件条件下,通过空间换时间与时间换空间的复杂博弈,旨在解决单卡显存不足与计算等待过长两大核心矛盾。

突破显存墙:模型并行技术的空间拆解
当模型参数量突破千亿级别,单张显卡的显存容量成为首要瓶颈。模型并行是解决这一物理限制的根本方案。
-
张量并行
这是最细粒度的切分方式,它将矩阵乘法运算拆解到多个GPU上并行执行,一个巨大的权重矩阵被按列或按行切分,每张卡只存储部分权重并计算部分结果,最后通过通信汇总,这种方式通信极其频繁,适合在单机内部使用,能最大程度保证计算密度,是目前训练超大模型的基础操作。 -
流水线并行
面对跨机通信延迟高的问题,流水线并行提供了宏观解决方案,它将模型按层切分,不同的GPU负责不同层的计算,数据像流水线一样依次通过各卡。这种方式显著降低了通信量,但容易产生“气泡”,即下游显卡在等待上游数据时的空转,专业的解决方案通常采用GPipe或1F1B调度策略,通过微批次拆分,填满流水线空隙,极大提升了硬件利用率。
提升吞吐量:高效推理服务的关键策略
在模型部署与推理阶段,并发的目标从“算得动”转变为“算得快”。显存优化与请求调度是提升并发吞吐量的核心驱动力。
-
显存优化技术
KV Cache是推理并发的关键技术,在Transformer架构中,通过缓存注意力机制中的Key和Value矩阵,避免重复计算。但这会占用大量显存,PagedAttention技术应运而生,它借鉴操作系统虚拟内存管理思想,将KV Cache分页存储,解决了显存碎片化问题,使得显存利用率接近100%,单卡并发请求数成倍增加。 -
动态批处理
用户请求通常是离散且大小不一的。传统的静态批处理效率低下,动态批处理策略能在服务端将多个请求动态打包,在一次前向传播中并行处理多个序列,配合Continuous Batching技术,系统可以做到“早退机制”,即处理完的请求立即释放资源插入新请求,显著降低了平均响应延迟。
混合精度与通信优化:算力释放的加速器
除了架构层面的拆分,底层的计算与通信优化同样决定并发的上限。
-
混合精度训练
利用FP16或BF16格式进行计算,不仅减少了一半的显存占用,还适配了现代GPU的Tensor Core加速单元,虽然低精度可能带来数值稳定性问题,但通过损失缩放等技术,已能完美平衡精度与速度。 -
通信与计算重叠
在分布式训练中,通信往往是瓶颈。优秀的并发系统必须实现通信与计算的重叠,通过优化器状态并行和梯度分桶传输,在GPU进行前向或反向计算的同时,利用网络带宽传输数据,将通信开销隐藏在计算时间中,实现全速运转。
独立见解:并发设计的权衡艺术
关于大模型是如何并发,我的看法是这样的:这不仅是技术堆叠,更是一种资源权衡的艺术。
-
计算强度与通信开销的博弈
张量并行计算效率高但通信重,适合机内;流水线并行通信轻但存在气泡,适合机间。没有万能的并行策略,必须根据集群拓扑结构和模型特性,寻找最优的“三维混合并行”配比。 -
显存与计算的置换
检查点技术通过释放中间激活值来换取显存,代价是反向传播时的重计算。这是一种典型的以时间换空间策略,在显存极度紧张时,这是必须的选择;但在显存充裕时,应保留更多激活值以减少计算量。
大模型并发技术是一套精密的系统工程,从底层的张量切分到上层的请求调度,每一层都需要精细打磨。只有深刻理解硬件特性与算法原理,才能构建出真正高效、稳定的大模型并发系统。
相关问答
问:在显存受限的情况下,如何最大化推理并发量?
答:首先应采用模型量化技术(如INT8/INT4),大幅压缩模型权重体积,必须引入PagedAttention等显存管理技术,消除内存碎片,使用Continuous Batching策略,确保在任何时刻GPU都在满负荷运转,避免资源闲置。
问:流水线并行中的“气泡”现象如何解决?
答:主要依靠微批次划分与调度优化,通过增加微批次数量,让流水线各阶段始终有数据待处理,采用1F1B(One Forward One Backward)调度策略,交替执行前向与反向传播,最大程度减少设备空闲等待时间,提升整体流水线效率。
您在实践大模型并发过程中遇到过哪些具体的瓶颈?欢迎在评论区分享您的解决方案。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/118147.html