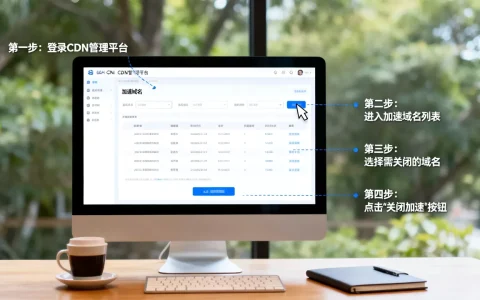
教育垂直领域大模型的价值核心在于“精准适配”与“深度交互”,而非单纯的知识库扩容,经过对当前主流技术路线与落地应用的深度复盘,我们得出一个核心结论:教育大模型成功的关键,在于将通用大模型的“广博”转化为教育场景下的“专业”,通过精细化的微调与检索增强技术,解决“幻觉”问题,实现千人千面的个性化教学。 这不仅是技术的升级,更是教育生产力的重构。

技术底座:从通用到垂直的跨越
通用大模型在教育场景下往往面临“懂知识但不懂教学”的困境。
- 领域知识注入: 教育垂直领域大模型通过注入教育学、心理学及各学科专业知识,构建了坚实的领域知识图谱,这使得模型不仅能够解答题目,更能理解知识点之间的逻辑关联。
- 指令微调优化: 针对教育特有的场景,如作文批改、口语对话、解题引导,模型进行了专门的指令微调,这确保了模型输出的内容符合教学大纲要求,语言风格贴近师生习惯。
- 幻觉抑制机制: 教育容错率极低,通过检索增强生成(RAG)技术,模型在生成答案前会检索权威教材与题库,从源头减少胡编乱造,确保知识点的准确无误。
场景落地:三大核心应用价值
深度了解教育垂直领域大模型后,这些总结很实用,主要体现在以下三个高频应用场景的质变上。
- 智能辅导的质变: 传统的搜题软件只给答案,容易养成学生依赖心理,垂直大模型能够扮演“AI导师”角色,运用苏格拉底教学法,通过提问引导学生思考,逐步推导答案,这种启发式教学,真正实现了从“授人以鱼”到“授人以渔”的转变。
- 作业批改的深度进化: 现在的模型已不再局限于选择题批改,对于主观题,如作文或英语口语,模型能从逻辑、修辞、发音等多个维度进行评分,并提供具体的修改建议,这极大地减轻了教师重复性工作的负担。
- 个性化学习的终极实现: 基于学生的学习数据,模型能构建动态学生画像,它能精准识别学生的薄弱知识点,并据此推送定制化的学习路径和练习题,真正落实“因材施教”的教育理想。
实施策略:教育机构如何正确拥抱大模型
对于教育机构而言,盲目跟风部署大模型并不可取。

- 明确业务痛点: 部署前需明确是解决师资不足、内容生产效率低,还是个性化服务缺失的问题。需求导向是技术落地的第一原则。
- 数据安全与隐私合规: 教育数据涉及未成年人隐私,敏感度极高,机构必须建立严格的数据脱敏与加密机制,确保模型在训练和推理过程中符合《数据安全法》等相关法规。
- 人机协同模式构建: 大模型不是要取代教师,而是成为教师的超级助手,机构应重新设计教学流程,让教师专注于情感关怀与价值观引导,让模型承担知识传授与作业批改工作。
行业洞察:挑战与未来展望
虽然技术进步显著,但挑战依然存在。
- 情感交互的短板: 目前的大模型在处理学生情绪、进行心理疏导方面仍显生硬。情感计算将是未来教育大模型重点突破的方向。
- 算力成本与响应速度: 高质量的模型推理需要昂贵的算力支持,如何在保证效果的前提下,通过模型蒸馏等技术降低成本、提升边缘端响应速度,是商业化普及的关键。
- 评价体系的重构: 随着AI工具的普及,传统的以结果为导向的评价体系面临挑战,未来的教育评价将更多关注思维过程与创新能力。
深度了解教育垂直领域大模型后,这些总结很实用,它们不仅指出了技术演进的方向,更为教育从业者提供了一套可落地的行动指南,教育大模型的本质,是用技术的确定性去应对教育过程的不确定性,最终实现教育公平与效率的双重提升。
相关问答
教育垂直领域大模型与通用大模型(如ChatGPT)在解题能力上有什么本质区别?
通用大模型侧重于生成流畅的文本和广泛的常识,但在解决特定学科题目时,容易出现逻辑错误或知识点偏差(幻觉),教育垂直领域大模型则经过了海量高质量教育数据的“预训练+微调”,并外挂了权威知识库,它不仅能给出准确答案,更能按照教学标准展示解题步骤,理解题目背后的考点,甚至能识别学生的错误思路并进行针对性纠正,其专业度和可信度远高于通用模型。

学校或教育机构引入大模型技术,最大的难点在哪里?
最大的难点在于“场景融合”与“数据治理”,许多机构误以为接入API就是智能化,如果无法将模型能力深度嵌入到备课、授课、作业、辅导的全流程中,技术就只是摆设,高质量教学数据的缺失和碎片化也是巨大障碍,没有结构化、标注良好的私有数据,大模型就无法“懂”学校的具体教学风格和学生学情,难以发挥个性化教学的威力。
您认为在未来的教育中,大模型会完全取代教师的角色吗?欢迎在评论区分享您的观点。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/124641.html