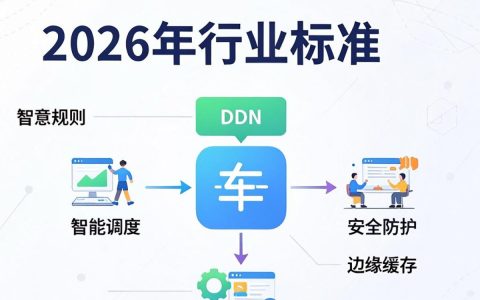
经过长达半年的深度体验与高频测试,针对市面上主流的国产大模型,我的核心结论非常明确:国产大模型已经度过了“能用”的门槛,正式迈入了“好用”的阶段,但在复杂逻辑推理与垂直领域深度上仍存在明显梯队差异。对于普通用户和初级开发者而言,国产大模型完全足以替代国外同类产品满足日常需求;但对于需要极高精准度和复杂任务处理的专业人士,仍需甄别选择。“好用”的定义不再仅仅是生成通顺的中文,更在于是否具备长文本处理能力、逻辑推理稳定性以及生态工具的集成度。

综合能力评测:梯队分明,头部效应显著
在这半年的测试周期内,我重点体验了文心一言、通义千问、讯飞星火、Kimi以及智谱清言等主流模型,从整体表现来看,国产大模型呈现出明显的梯队分化。
-
第一梯队:逻辑与长文本的双重突破
头部模型(如文心一言4.0、通义千问Max、Kimi)在语义理解上已经达到了极高水准。最直观的感受是,它们不再“听不懂人话”。在面对复杂的Prompt(提示词)时,第一梯队模型能够准确拆解指令,不仅理解字面意思,还能通过上下文推断用户意图,特别是Kimi和通义千问在长文本处理上的表现令人印象深刻,支持20万字以上的上下文输入,这在处理长篇小说总结、法律合同审查时,具有极高的实用价值。 -
第二梯队:日常助手,够用但不出彩
部分中小厂商或非科技巨头旗下的模型,在日常对话、简单的文案生成上表现尚可,但在面对多轮对话、逻辑陷阱题时,容易出现“幻觉”或遗忘前文的情况,这类模型适合作为简单的聊天机器人使用,但难以胜任生产力工具的角色。
核心维度深度解析:从参数到体验
要回答“国产大模型对比评测好用吗?用了半年说说感受”这个问题,不能仅看表面生成速度,必须深入到逻辑推理、代码能力、多模态处理三个核心维度。
逻辑推理:从“一本正经胡说八道”到“有理有据”
半年前,很多国产模型在回答数学逻辑题时经常出错,甚至出现“9.11大于9.9”的低级错误,而现在,情况有了质的改观。
- 数学与逻辑题: 文心一言4.0和通义千问在处理复杂的数学应用题时,准确率大幅提升,它们能够展示清晰的推理步骤,而非直接给出一个错误的答案。
- 思维链能力: 我曾尝试让模型扮演“苏格拉底”进行多轮辩驳,头部模型能够很好地维持人设,逻辑自洽,不会在对话中途“出戏”,这表明其底层逻辑架构已经具备了较强的思维链引导能力。
代码能力:程序员的辅助利器
作为一名经常接触代码的用户,我重点测试了代码生成与Debug能力。

- 代码生成: 在Python和JavaScript的脚本生成上,通义千问和智谱清言表现优异,生成的代码规范度高,注释清晰,基本可以直接运行。
- Bug修复: 将报错日志直接丢给模型,头部国产大模型能够快速定位问题并给出修改建议。虽然偶尔也会给出过时的库函数建议,但整体可用率在80%以上。相比之下,部分第二梯队模型生成的代码往往存在语法错误或逻辑漏洞,需要人工大量修正。
多模态与文档处理:本土化的杀手锏
这是国产大模型相比国外模型最大的优势所在对中文语境和本土办公场景的深度适配。
- 文档解析: 很多国产大模型支持直接上传PDF、Word、Excel文件,在测试中,我上传了一份几十页的财报,要求提取关键数据,Kimi和文心一言不仅提取准确,还能生成结构化的表格,这在实际办公场景中极大地提升了效率。
- 图片理解: 讯飞星火和通义千问在图片理解上进步神速,不仅能识别图片中的文字,还能理解图片的幽默点或图表含义,这种多模态能力的融合,让“好用”的定义更加立体。
实际应用场景中的痛点与不足
虽然进步巨大,但在半年的使用中,我也发现了一些不容忽视的短板,这些是决定用户是否觉得“真好用”的关键因素。
-
幻觉问题依然存在
在撰写严肃的学术文章或查找具体的历史数据时,模型仍会产生“幻觉”,即编造不存在的事实或文献。这要求用户必须具备极强的鉴别能力,不能盲目信任模型输出的所有事实性内容。 -
上下文窗口的“遗忘”
尽管宣称支持超长上下文,但在极长对话的后期,部分模型会出现“注意力涣散”的情况,遗忘几轮对话前的设定,这在进行长篇小说创作或大型项目规划时,会打断工作流。 -
个性化定制门槛较高
虽然很多平台推出了“智能体”功能,允许用户定制模型,但对于普通用户来说,如何写出高质量的提示词、如何配置知识库,依然存在一定的学习成本。
专业解决方案:如何让国产大模型更好用?
基于半年的经验,我认为要让国产大模型真正成为生产力工具,需要遵循以下策略:
-
组合拳策略:不要迷信单一模型
不同的模型有不同的特长,建议建立一套“工具箱”:用Kimi或通义千问处理长文档和资料搜集;用文心一言进行中文创意写作;用智谱清言辅助代码编写。术业有专攻,组合使用效率最高。
-
掌握结构化提示词技巧
不要只给简单的指令,学会使用“角色设定+任务背景+输出要求+示例”的结构化提示词,不要只说“写个方案”,而要说“你是一位资深的产品经理(角色),请针对XX用户痛点(背景),写一份产品迭代方案,要求包含功能列表、优先级排序和预期收益(输出要求)”。 -
利用RAG(检索增强生成)技术
对于企业用户或专业领域用户,尽量使用支持知识库上传的平台,通过上传本地私有数据,让模型基于已知知识回答,可以极大降低幻觉,提升回答的专业度和准确性。
回顾这半年的使用历程,国产大模型的迭代速度令人惊叹,从最初的“玩具”属性,进化到如今能够切实提升工作效率的“工具”属性,虽然在顶尖逻辑推理和极致准确性上与GPT-4仍有差距,但在中文语境理解、本土办公场景适配以及性价比上,国产大模型已经展现出了强大的竞争力,对于大多数国内用户而言,国产大模型对比评测好用吗?用了半年说说感受,答案是肯定的:只要选对工具、掌握方法,它们不仅好用,而且能打。
相关问答
国产大模型在处理英文内容和翻译方面表现如何?
答:经过测试,头部国产大模型(如文心一言、通义千问)在英译中方面表现极佳,不仅准确,而且译文更符合中文表达习惯,优于部分国外模型的“翻译腔”,在中译英方面,对于日常商务邮件、普通文档的翻译完全够用,但在极度专业的学术英语或文学翻译上,词汇的丰富度和地道程度仍有提升空间,建议在处理重要英文文档时,采用“翻译+润色”两步走的策略。
免费版和付费版的大模型差距大吗?是否有必要付费?
答:差距非常明显,免费版通常使用的是参数量较小的模型,逻辑推理能力和长文本处理能力较弱,且容易出现排队或限流情况,付费版(如文心一言4.0、通义千问Plus)接入了最强模型,响应速度快,逻辑更严密,且支持更长的上下文,如果你只是偶尔闲聊或简单查询,免费版足够;但如果你是将其作为生产力工具用于写作、编程或数据分析,付费版的高效和稳定绝对物超所值。
您在日常生活中使用过哪些国产大模型?欢迎在评论区分享您的真实体验和使用技巧。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/127577.html