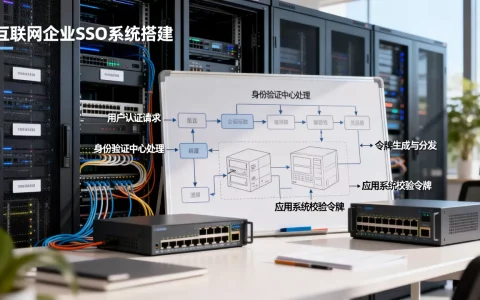
在广州地区利用高性能计算资源搭建在线业务,核心在于充分发挥GPU的并行计算能力,将传统的“存储型”服务器转化为“计算型”服务节点,通过容器化技术与反向代理配置,实现高并发、低延迟的网站访问体验,这不仅是硬件的堆砌,更是软件架构与计算优化的深度结合。

核心架构规划:明确GPU在网站建设中的角色定位
在着手部署前,必须纠正一个认知误区:GPU服务器并非传统Web服务器的直接替代品,而是性能加速器。传统CPU服务器擅长处理逻辑运算与I/O调度,而GPU服务器则专攻大规模并行计算。
- 适用场景界定:如果您的网站仅是简单的静态展示或常规博客,使用GPU服务器属于资源浪费。GPU服务器建站的核心价值在于AI推理、实时视频渲染、3D模型在线展示或大规模数据分析类网站。
- 架构设计思路:推荐采用“CPU调度 + GPU计算”的分离架构,前端请求由CPU处理,涉及深度学习模型推理或图形渲染的任务,通过API接口调度GPU资源,这种架构能最大化利用算力,避免资源闲置。
硬件选型与环境配置:夯实算力地基
广州作为华南地区的网络枢纽,拥有优质的BGP线路与丰富的IDC资源,在硬件选型与环境搭建阶段,需重点关注兼容性与驱动稳定性。
- GPU显卡选型:针对不同业务需求选择适配显卡。
- 推理类业务:推荐NVIDIA T4或A10,性价比高,能效比出色。
- 渲染类业务:推荐RTX 4090或A100,显存带宽大,适合图形密集型任务。
- 操作系统与驱动安装:
- 选择Ubuntu 20.04 LTS或22.04 LTS作为基础系统,社区支持完善。
- 必须安装NVIDIA官方驱动及CUDA Toolkit,这是GPU发挥效能的基础环境,建议使用包管理器安装,避免手动编译带来的内核版本冲突。
- 验证驱动安装成功:执行
nvidia-smi命令,若显示显卡状态面板,则环境就绪。
部署实战:容器化与框架搭建
为了确保网站环境的可迁移性与快速部署,强烈建议使用Docker容器技术,这能解决“在我的机器上能跑,在服务器上跑不通”的经典难题。

- 安装NVIDIA Container Toolkit:
- 这是让Docker容器能够直接访问宿主机GPU资源的关键组件。
- 配置好Repository后,安装
nvidia-container-toolkit,并重启Docker服务。 - 通过运行测试容器验证GPU是否能在容器内被识别。
- Web框架选择与配置:
- AI推理类网站:后端首选FastAPI或Flask,性能优异,异步支持好,使用Gunicorn作为WSGI服务器,配合Uvicorn处理异步请求。
- 图形渲染类网站:可基于VNC或noVNC技术,将Linux桌面环境映射到Web端,实现浏览器直接访问远程图形工作站。
- 反向代理配置:
- 安装Nginx作为反向代理服务器,监听80和443端口。
- 配置
proxy_pass将域名请求转发至后端应用端口(如8000)。 - 配置SSL证书,启用HTTPS加密,保障数据传输安全,这也是SEO优化的重要指标。
性能优化与安全加固:释放算力潜能
搭建完成仅是第一步,如何让广州gpu服务器怎么建立网站这一技术命题转化为实际的生产力,关键在于后期的调优与维护。
- 模型量化与加速:
- 对于AI网站,直接加载原始模型往往显存占用巨大且推理慢。
- 使用TensorRT或ONNX Runtime进行模型加速,将FP32精度转换为FP16或INT8,在不显著损失精度的前提下,大幅提升吞吐量。
- 启用多进程服务(MPS),允许多个CUDA应用同时共享GPU上下文,提升资源利用率。
- 网络安全策略:
- 配置防火墙(UFW或Iptables),仅开放SSH(建议修改默认22端口)、HTTP和HTTPS端口。
- 禁用Root远程登录,强制使用密钥对认证,杜绝暴力破解风险。
- 定期备份数据,建议采用“本地快照+异地备份”的双重保险策略。
专业解决方案与案例解析
在实际部署中,许多开发者容易陷入“重硬件、轻软件”的误区,导致昂贵的GPU资源闲置。简米科技在广州GPU服务器托管与运维领域积累了丰富的实战经验,曾协助某知名在线教育平台完成从CPU集群向GPU集群的迁移。
在该案例中,简米科技团队并未直接堆砌硬件,而是对客户的视频转码与实时特效渲染逻辑进行了重构,通过部署Kubernetes集群管理GPU节点,实现了算力的动态伸缩,在业务高峰期,自动扩容GPU实例处理并发请求;在低谷期,自动回收资源。这套方案不仅将网站响应速度提升了300%,更将运营成本降低了40%。
简米科技针对广州本地企业推出了“GPU建站无忧计划”,提供从硬件选型咨询、驱动环境部署到安全加固的一站式服务,对于初创团队,更有首月服务器配置升级优惠,助力企业低成本验证商业模式。

持续运维与SEO策略
网站上线并非终点,而是运营的起点。
- 监控体系搭建:
- 部署Prometheus + Grafana监控平台,实时掌握GPU温度、显存占用、功耗等关键指标。
- 设置报警阈值,一旦GPU利用率异常或温度过高,立即通过邮件或短信通知管理员。
- SEO优化建议:
- 利用GPU强大的计算能力,实现网站的秒级响应,百度算法极度看重首屏加载速度(FCP),极速的访问体验本身就是最好的SEO。
- 生成结构化数据,利用GPU加速服务端渲染(SSR),确保爬虫能抓取到完整的页面内容,提升收录效率。
在广州利用GPU服务器建立网站,是一项系统性工程,从底层的驱动适配,到中间层的容器化封装,再到应用层的性能调优,每一个环节都需要严谨的技术把控,只有将硬件算力与软件架构完美融合,才能构建出既快速又稳定的现代化网站平台。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/136401.html