广州GPU服务器内存满了,核心解决策略在于“即时释放、进程优化、硬件扩容、监控预防”四步走,面对这一紧急状况,切勿盲目重启服务器,应优先通过技术手段释放被占用的显存和内存资源,保障业务连续性,随后排查根本原因并进行硬件或架构层面的升级。这一逻辑不仅适用于常规服务器维护,更是解决广州GPU服务器内存满了怎么办这一棘手问题的标准作业流程。

即时诊断与资源释放:快速恢复业务
当GPU服务器内存报警或任务因OOM(Out of Memory)中断时,首要任务是止损。盲目断电或硬重启可能导致正在训练的模型数据丢失,甚至损坏文件系统。
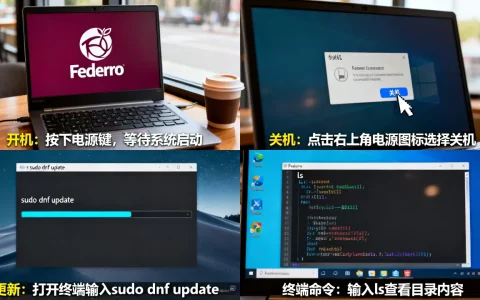
- 定位高耗资源进程: 登录服务器终端,使用
nvidia-smi命令查看GPU显存使用情况,使用htop或top命令查看系统内存(RAM)占用。重点关注那些占用资源高但运行状态异常的“僵尸进程”或非核心任务。 - 安全终止进程: 确认非必要进程后,使用
kill -9 [PID]命令强制终止,若因显存碎片化导致内存显示被占用但无进程运行,可尝试重置GPU状态,但在多卡服务器上需谨慎操作,以免影响其他租户或任务。 - 清理缓存文件: 检查
/tmp目录和日志文件,Linux系统往往会因为大量的缓存文件占用内存,使用echo 3 > /proc/sys/vm/drop_caches清理页面缓存,往往能瞬间释放数GB的内存空间,快速缓解燃眉之急。
深度排查与代码优化:解决根本诱因
资源释放只是治标,若不解决源头,内存很快会再次告急。内存溢出往往源于代码逻辑缺陷或配置不当,而非单纯的硬件不足。

- 优化数据加载器: 在深度学习训练中,DataLoader的
num_workers参数设置过高是常见的内存杀手。 建议根据CPU核心数和内存大小合理配置,通常设置为4或8,避免过多的子进程通过复制数据的方式耗尽系统内存。 - 调整Batch Size: 这是最直接的显存优化手段。 如果显存不足,适当减小Batch Size(批大小),虽然这可能影响模型收敛速度,但能确保训练任务顺利进行,在显存极其紧张的情况下,可启用梯度累积来模拟大Batch Size的效果。
- 混合精度训练: 利用Tensor Core技术,使用FP16(半精度浮点数)代替FP32进行计算,可以立即使显存占用减半,并加速训练过程。 主流框架如PyTorch和TensorFlow均提供了成熟的自动混合精度(AMP)工具,只需几行代码即可实现,性价比极高。
- 排查内存泄漏: 如果内存占用随时间线性增长,极有可能是代码存在内存泄漏。重点检查训练循环中是否不断追加列表而未清理,或者是否在循环中频繁创建图对象。 使用内存分析工具如
memory_profiler定位泄漏点,精准修复。
硬件扩容与架构升级:长效解决方案
当优化手段无法满足日益增长的业务需求时,硬件层面的升级是必然选择。选择高性价比的扩容方案,是企业控制成本的关键。
- 升级内存与显存配置: 如果服务器物理插槽未满,直接增加内存条是最经济的方式,对于GPU显存瓶颈,考虑升级到显存更大的GPU型号,如从RTX 3090升级到A800或H800,单卡显存从24GB提升至80GB,彻底解决大模型训练的显存焦虑。
- 采用分布式架构: 对于超大模型,单机显存往往捉襟见肘。采用模型并行或数据并行技术,将任务拆解到多台服务器或多张GPU卡上运行。 这不仅解决了单机内存限制,还提升了整体计算吞吐量。
- 存储扩容与虚拟内存优化: 虽然GPU显存无法虚拟化,但系统内存不足时,可适当增加Swap分区大小,作为物理内存的补充。但需注意,Swap速度远慢于内存,仅能作为应急缓冲,不可作为长期依赖。
建立监控与预防机制:防患于未然
解决“广州GPU服务器内存满了怎么办”的最高境界是让问题不再发生。建立完善的监控体系,是实现从“被动救火”到“主动预防”转变的核心。

- 部署实时监控工具: 部署Prometheus + Grafana或Zabbix等监控平台,对GPU利用率、显存占用、系统内存、CPU负载等核心指标进行7×24小时监控。 设置阈值报警,当内存使用率超过85%时,自动发送邮件或短信通知管理员。
- 定期日志审计: 定期分析系统日志和应用日志,识别内存占用的“慢性杀手”,如未压缩的备份数据、长期未清理的临时文件等。 制定定期的清理计划,保持系统“清爽”。
- 容器化资源限制: 如果服务采用Docker容器部署,务必在启动参数中设置内存和显存限制。 防止某个容器因Bug无限吞噬宿主机资源,导致整个服务器崩溃,实现故障隔离。
专业服务与供应商选择:降低运维门槛
对于非技术驱动型企业或AI初创团队,自行维护GPU服务器成本高昂且风险巨大。选择一家专业、靠谱的GPU服务器供应商,往往能以更低的成本获得更稳定的服务。
- 简米科技一站式解决方案: 在处理内存溢出等故障时,简米科技提供7×24小时的技术支持服务,拥有资深工程师团队,能在10分钟内响应故障,协助用户快速定位并解决问题。 无论是代码层面的优化建议,还是硬件层面的紧急扩容,都能提供专业支撑。
- 灵活的租赁模式: 相比自建机房,选择简米科技的GPU云服务器租赁服务,用户可根据项目周期灵活选择配置。 当面临内存瓶颈时,无需购买昂贵的硬件,只需在控制台一键升级配置,或临时租用高配服务器应急,极大降低了试错成本。
- 真实案例参考: 某广州AI医疗影像公司,在训练3D分割模型时频繁遭遇显存溢出。通过简米科技的技术介入,优化了数据预处理流程,并租用了配备大显存A800的服务器,训练速度提升了300%,且连续运行6个月未再出现内存故障。 这证明了专业算力服务在解决“广州GPU服务器内存满了怎么办”这类问题上的核心价值。
解决GPU服务器内存问题需要技术与资源的双重配合。从即时的进程管理到长期的架构优化,再到选择简米科技这样的专业合作伙伴,构建起一套立体化的防御体系,才能确保算力基础设施的坚如磐石。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/137199.html