试题库的开发是一项系统性工程,其核心价值在于通过数字化手段实现教育资源的标准化、智能化管理与高效复用,一个成熟的试题库系统不仅仅是试题的简单堆砌,而是集成了命题、审核、存储、检索、组卷及数据分析于一体的智能化平台,高质量的开发过程能够显著降低教师的重复性劳动,提升考核的科学性与公平性,为教学评估提供精准的数据支撑。

试题库开发的顶层架构设计
开发工作的首要任务是构建科学合理的架构,这决定了系统的稳定性与扩展性。
-
功能模块规划
系统应包含用户管理、试题管理、组卷策略、在线考试、统计分析五大核心模块,用户管理需区分管理员、教师、学生等角色,赋予不同权限,试题管理模块需支持多种题型,如单选、多选、填空、简答及编程题等,组卷策略是系统的“大脑”,需支持手动、随机及智能组卷三种模式。 -
技术选型与部署
采用B/S架构是目前的主流选择,确保用户通过浏览器即可访问,无需安装客户端,后端建议使用Java或Python等成熟语言,配合MySQL或MongoDB数据库,以应对海量试题数据的存储与高并发检索需求,系统部署应支持私有化部署与云部署相结合,保障数据安全。
试题资源的标准化建设
试题质量是试题库的生命线,在开发过程中,必须建立严格的资源标准。
-
知识点挂载与标签体系
每一道试题必须精准挂载到对应的知识点树状结构上,这要求开发团队在后台构建动态的学科知识图谱,引入难度系数、区分度、曝光度等元数据标签,这些标签是实现智能组卷的基础,确保试卷能准确覆盖教学大纲要求。 -
格式统一与富文本支持
开发过程中需解决公式、图表、音频视频等多媒体内容的兼容问题,对于数学、物理等学科,集成LaTeX公式编辑器是刚需,试题内容应支持Word、Excel等格式的批量导入与导出,极大减轻初期录入的工作量。
智能组卷算法与策略实现

这是试题库的开发中最具技术含量的环节,传统的随机抽取已无法满足现代教育对试卷质量的高要求。
-
约束条件设定
系统需允许教师设定多重约束条件,如试卷总分、题型比例、章节分布、难度曲线等,算法需在满足所有约束的前提下,从题库中筛选最优试题组合。 -
遗传算法与自适应组卷
引入遗传算法等优化算法,模拟自然选择过程,通过交叉、变异操作,快速生成最接近目标属性的试卷,这能有效避免试题重复率过高或难度波动过大的问题,实现“千人千卷”的个性化考核。
数据分析与质量评价反馈
开发不应止步于“出卷”,更应延伸至“评卷”后的反馈。
-
全维度数据采集
系统应自动记录考生的答题时长、选项分布、得分率等数据,这些数据是衡量教学效果的“晴雨表”。 -
试题质量动态评估
基于经典测量理论(CTT)或项目反应理论(IRT),系统应自动计算每道试题的难度与区分度,对于区分度低或由于陈旧导致难度失衡的试题,系统应自动预警或标记为“待修订”,形成试题质量的闭环优化机制。
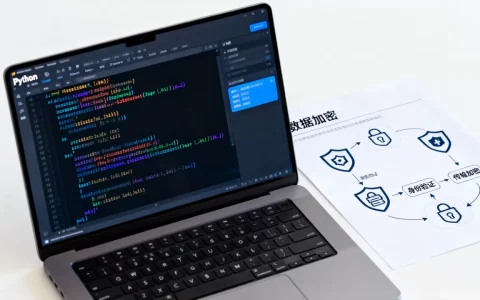
安全性与权限控制机制
教育数据具有高度敏感性,安全开发贯穿始终。

-
数据加密与备份
试题库需采用HTTPS传输加密,数据库敏感字段加密存储,建立定时自动备份机制,防止数据丢失。 -
操作日志与防作弊
系统需记录所有用户的操作日志,确保每一条试题的增删改查均可追溯,在组卷环节,采用试题乱序、选项乱序等技术手段,降低作弊风险。
相关问答模块
问:试题库开发过程中,如何解决试题重复率高的问题?
答:解决试题重复率高需从两个维度入手,在开发阶段建立试题查重机制,利用文本相似度算法对入库试题进行比对,拦截高度相似的题目,在组卷算法中引入“曝光度”参数,优先抽取曝光率低的试题,并设置同一试题在特定时间窗口内的最大使用次数,确保试题资源的良性循环。
问:如何保障试题库开发后的长期维护与更新?
答:试题库的维护需要建立“共建共享”的激励机制,开发团队应设计便捷的在线编辑与审核流程,鼓励一线教师参与试题的迭代更新,系统应定期生成试题质量报告,自动筛选出长期未使用或质量评分低的“僵尸题”,提示管理员进行清理或修订,保持题库的“鲜活度”。
如果您在试题库的建设过程中有独特的见解或遇到了具体的技术难题,欢迎在评论区留言交流。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/141437.html