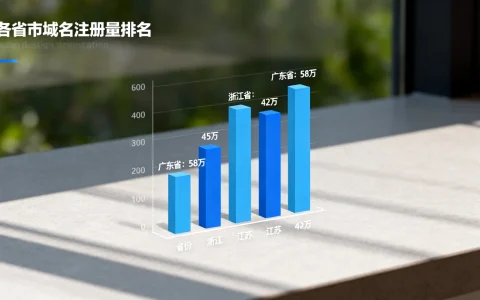
技术路径已从单一的静态知识检索,跨越至具备深度推理能力的动态智能体阶段,这一过程彻底改变了算法工程师的备考与学习范式。这一演进不仅仅是工具的升级,更是解题思维从“搜索匹配”向“逻辑生成”的根本性转变,掌握这一演进脉络,对于高效利用大模型技术提升算法能力至关重要。

技术萌芽期:基于检索的静态知识库模式
早期的技术应用主要集中在检索增强生成(RAG)的初级阶段,彼时,模型的角色更像是一个“智能搜索引擎”。
- 核心逻辑:系统通过向量检索技术,在庞大的题库数据库中匹配与题目描述最相似的已有题解。
- 主要局限:模型缺乏真正的逻辑推理能力,严重依赖历史数据的覆盖面,一旦遇到变型题或从未见过的全新题目,模型往往只能通过拼凑相似代码片段来应对,导致生成的代码逻辑不通,甚至出现“幻觉”,输出无法通过编译的错误答案。
- 用户体验:用户需要具备极强的辨别能力,在碎片化的信息中筛选有用逻辑,学习效率提升有限。
技术成长期:上下文学习与思维链的突破
随着GPT-4等高性能基座模型的出现,算法刷题技术进入了“推理为王”的成长期,这一阶段的标志性技术是思维链的广泛应用。
- 推理能力觉醒:模型不再仅仅匹配关键词,而是开始“读题”。通过将复杂问题拆解为多步骤的子问题,模型能够逐步推导算法思路,模拟人类解题时的思考过程。
- Few-Shot Learning(少样本学习):通过在提示词中注入少量的高质量解题范例,模型能够快速掌握特定的解题模式,提供几道动态规划题的解法,模型便能举一反三,解决类似的动态规划问题。
- 实际效果:代码生成的准确率大幅提升,模型能够解释每一步代码的意图,使得“大模型算法刷题技术演进,讲得明明白白”成为可能,用户不仅获得答案,更能理解背后的逻辑。
技术成熟期:多模态交互与Agent智能体应用
当前,大模型算法刷题技术已步入成熟期,核心特征是智能体与多模态交互的深度融合。

- 端到端解题流程:现代技术方案构建了闭环的Agent系统。从题目解析、思路分析、代码生成到在线测试、错误修正,全流程自动化,模型能够根据编译器的反馈信息,自主调试代码,直至通过所有测试用例。
- 个性化学习路径:系统不再局限于解决单道题目,而是基于用户的历史做题数据,构建用户能力模型。算法能够精准定位用户的薄弱知识点,并智能推荐针对性的强化练习,实现了从“刷题工具”到“AI私教”的跨越。
- 多模态输入:支持截图识题、语音交互等模式,极大地降低了用户输入题目的门槛,提升了交互体验的流畅度。
未来演进趋势:从辅助工具到协同伙伴
展望未来,大模型在算法领域的应用将更加注重“人机协同”。
- 代码形式化验证:结合形式化验证工具,模型生成的代码将具备数学层面的正确性保证,彻底消除“幻觉”风险。
- 逆向工程与教学:模型将不仅限于解题,更能进行逆向教学,通过反问、引导式提问,帮助用户构建完整的算法知识体系,而非直接给出答案。
- 竞技级算法探索:随着模型算力的提升,AI有望在ACM国际大学生程序设计竞赛等顶级赛事中探索人类未曾发现的算法优化策略,推动计算机科学理论的边界拓展。
专业解决方案与实施建议
针对算法学习者,基于上述技术演进,提出以下专业建议:
- 善用思维链提示:在使用大模型时,强制要求模型输出详细的思考步骤,而非直接给出代码,这有助于培养自身的逻辑思维能力。
- 建立反馈闭环:不要盲目信任模型生成的代码,务必在本地IDE或在线判题系统中运行验证,并将报错信息反馈给模型,观察其自我修正过程,这是提升编程实战能力的关键。
- 关注技术迭代:大模型算法刷题技术演进速度极快,学习者应关注最新的Agent框架和Prompt Engineering技巧,保持工具链的更新,以维持竞争优势。
相关问答模块
大模型在处理复杂算法题时,为什么有时会产生“幻觉”?

解答:大模型的“幻觉”主要源于其概率生成的本质,在处理超长上下文或极其复杂的逻辑推理时,模型可能会丢失关键信息,或者在训练数据的分布外进行错误的概率预测。通过引入外部工具(如代码解释器)进行执行验证,或采用更先进的树状搜索算法,可以有效抑制幻觉现象。
普通算法学习者如何利用当前的大模型技术提升刷题效率?
解答:建议采用“三步法”,第一步,先独立思考,尝试解题;第二步,利用大模型进行思路点拨,而非直接索要代码;第三步,利用大模型对通过但不够优雅的代码进行复杂度分析和优化建议,这种交互方式能最大化地利用大模型的推理能力,而非仅仅将其作为答案库。
如果您在算法学习过程中有独特的大模型使用心得,欢迎在评论区分享您的见解。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/142418.html