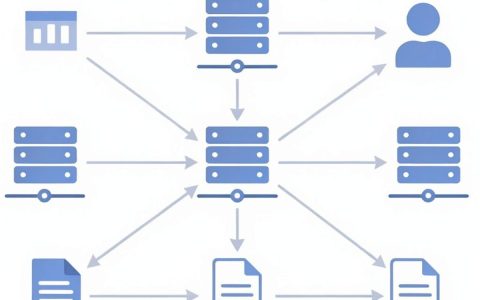
大模型搭建训练的核心在于“数据工程”与“算力适配”的双重博弈,而非单纯的代码堆砌,掌握这一核心逻辑,能将模型训练成功率提升至80%以上,同时大幅降低试错成本,真正的技术壁垒不在于获取教程,而在于对底层架构的理解深度与工程化落地的细节把控。

打破认知误区:从“调包侠”到“架构师”的转变
接触大模型搭建训练教程前,很多人容易陷入一个误区,认为只要拥有开源代码和足够显卡,就能复现ChatGPT级别的智能。学了大模型搭建训练教程后,这些感受想说说,最深刻的一点便是:模型训练是一场精密的系统工程。 这不仅仅是编写Python脚本那么简单,它要求从业者具备全链路的工程思维,从数据清洗、分词器训练,到模型架构设计、分布式训练配置,每一个环节都存在“蝴蝶效应”。
- 数据质量决定模型上限。 很多初学者将90%的时间花在模型参数调优上,却忽略了数据清洗,高质量的数据集能让模型在更少的迭代次数下收敛得更好。
- 算力利用率是关键指标。 即使拥有高端GPU,如果并行策略配置不当,显存利用率可能不足40%,学会使用DeepSpeed、Megatron-LM等分布式框架,是通往专业大模型工程师的必经之路。
- 过拟合与欠拟合的动态平衡。 在训练过程中,实时监控Loss曲线和评估指标,比盲目等待训练结束更重要。
数据工程:被低估的隐形战场
在亲自上手搭建训练环境后,你会发现数据预处理占据了整个项目周期的60%以上。数据清洗不是简单的去重和去噪,而是对知识的重构。
- 分词器的选择与训练。 词表大小直接影响模型的推理效率和词向量质量,盲目使用通用分词器处理垂直领域数据,会导致Token碎片化严重,增加训练成本。
- 数据配比的艺术。 通用数据提供基础能力,垂直数据注入专业知识,如何配比这两类数据,决定了模型是“通才”还是“专才”。
- 多模态数据的对齐。 如果涉及图文训练,数据对齐的精度将直接影响模型的多模态理解能力。
算力适配与分布式训练的实战策略
大模型训练最大的拦路虎往往是显存不足(OOM)。解决显存瓶颈,不能只靠“买卡”,更要靠“技术”。
- 混合精度训练。 使用FP16或BF16精度,不仅能减半显存占用,还能利用Tensor Core加速计算,但需注意Loss Scaling,防止梯度下溢。
- 梯度累积与检查点。 在显存有限的情况下,通过梯度累积模拟大Batch Size;通过激活检查点技术,以计算换显存,这是性价比极高的策略。
- Zero优化技术。 DeepSpeed的Zero-1/2/3阶段,分别优化了优化器状态、梯度缓存和参数分区,合理选择阶段,能在单卡或多卡环境下实现极致的显存压缩。
微调与对齐:赋予模型“灵魂”

预训练赋予了模型知识,而微调(SFT)和对齐(RLHF/DPO)则赋予了模型指令遵循能力和价值观。这一阶段,决定了模型是否“好用”。
- 指令数据的构建。 高质量的指令数据应具备多样性、复杂性和准确性,人工标注虽然精准,但成本高昂;利用强模型生成数据(蒸馏)是当前主流方案。
- 参数高效微调(PEFT)。 LoRA和QLoRA技术的出现,让普通开发者也能在消费级显卡上微调大模型。核心在于只训练旁路参数,冻结主干参数,既保留了基座能力,又大幅降低了训练门槛。
- 人类反馈强化学习。 RLHF流程复杂且不稳定,直接偏好优化(DPO)因其简单高效,正逐渐成为新的行业首选。
避坑指南与专业解决方案
学了大模型搭建训练教程后,这些感受想说说,关于踩坑的经验总结。 很多教程不会告诉你的是,环境配置和依赖冲突往往是最大的时间杀手。
- 环境隔离与版本管理。 务必使用Docker容器化部署训练环境,避免不同项目间的CUDA版本冲突。
- 日志监控体系。 建立完善的TensorBoard或WandB监控体系,实时观察梯度范数和学习率变化,一旦发现梯度爆炸或消失,立即停止训练,排查数据或超参问题。
- 断点续训机制。 训练大模型动辄数周,必须配置自动保存Checkpoints的策略,防止因意外宕机导致前功尽弃。
从理论到落地的最后一公里
模型训练完成并非终点,推理部署才是商业价值的起点,模型量化(Quantization)和蒸馏是降低推理成本的两大法宝,将FP16模型量化为INT8或INT4,能在几乎不损失精度的情况下,将推理速度提升2-3倍,显存占用降低一半,这要求我们在训练阶段就要考虑到量化感知,预留相应的鲁棒性。
相关问答
问:大模型训练过程中Loss不下降或者震荡严重,应该如何排查?

答:这是一个典型的训练不稳定问题,建议按以下步骤排查:
- 检查数据质量。 是否存在大量脏数据、超长文本或异常Token,清洗数据往往是第一步。
- 调整学习率。 学习率过大导致震荡,过小导致不收敛,建议使用Warmup策略,并尝试调整学习率衰减系数。
- 检查梯度裁剪。 设置合理的梯度裁剪阈值(如1.0),防止梯度爆炸。
- 验证模型架构。 确认Attention Mask和Position Embedding配置是否正确,架构错误往往会导致Loss异常。
问:个人开发者或中小企业,在显存资源有限的情况下,如何高效参与大模型研发?
答:资源有限时,应避开预训练,主攻垂直领域的微调与应用:
- 选择开源基座。 选用Llama-3、Qwen等开源小参数模型(7B或14B),这些模型基座能力已经很强。
- 采用QLoRA技术。 4-bit量化加载模型,仅训练少量适配器参数,单张24G显存卡即可微调7B模型。
- 深耕数据壁垒。 算力不够,数据来凑,构建行业独有的高质量指令数据集,这是大厂难以覆盖的护城河。
- 利用云服务弹性算力。 按需租用云端GPU,避免硬件资产投入,专注于算法逻辑与业务落地。
如果你在搭建训练过程中也有独特的见解或遇到了棘手的问题,欢迎在评论区留言交流。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/146138.html