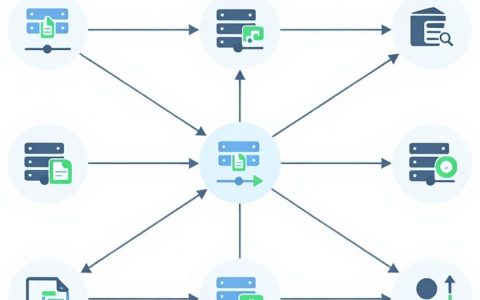
大模型实时训练App的核心价值在于打破了传统AI模型“离线训练、在线推理”的滞后性壁垒,实现了数据流与模型更新的同步闭环,经过深度调研与技术拆解,可以明确一个核心结论:真正具备落地价值的实时训练App,并非单纯追求毫秒级的参数更新速度,而是构建了一套包含数据清洗、增量学习、灾难性遗忘抑制以及边缘端推理优化的完整工程体系。 对于开发者与企业而言,选择和应用此类工具的关键,不在于“训练”二字,而在于如何在高频交互中保持模型的稳定性与安全性。

大模型实时训练App的底层逻辑与技术架构
传统大模型训练往往伴随着高昂的算力成本和漫长的时间周期,而实时训练App的出现,本质上是一场算力与效率的博弈,这类应用通常采用增量学习与参数高效微调(PEFT)相结合的技术路线。
- 增量学习机制:这是实时训练的核心,模型不再需要全量数据重新训练,而是针对新产生的数据进行局部参数调整,这要求App具备极高的数据筛选能力,确保进入训练管道的数据是高质量且具有代表性的。
- 边缘-云端协同架构:为了保证“实时”体验,大多数优秀的App采用了云边协同策略。云端负责复杂的模型迭代与全局参数聚合,边缘端(用户设备)负责轻量级的推理与数据预处理。 这种架构大幅降低了通信延迟,使得用户在交互过程中几乎感知不到训练过程的存在。
- 动态知识图谱嵌入:部分前沿App开始引入动态知识图谱,将实时训练的过程从单纯的参数调整转化为结构化知识的注入,极大地提升了模型在特定垂直领域的问答准确率。
实际应用中的挑战与专业解决方案
在深入研究过程中,发现大模型实时训练App面临着三大核心技术挑战,这也是衡量一款App是否成熟的关键指标。
灾难性遗忘问题的攻克
这是实时训练中最棘手的问题,模型在学习新知识的同时,往往会遗忘旧有的知识,导致在通用任务上的表现大幅下滑,专业的解决方案通常包括:
- 经验回放技术:在训练新数据的同时,随机混入少量旧数据进行“复习”,维持模型对历史知识的记忆。
- 参数隔离机制:针对特定任务或新知识,冻结模型主干参数,仅开放部分适配器层进行训练,从物理上切断了对核心知识区的破坏。
数据质量与安全性的实时把控
实时训练意味着数据源头开放,这极易引入噪声甚至恶意攻击数据。优秀的App必须内置一套严苛的实时数据清洗与审核模块。

- 自动化清洗管道:在数据进入模型前,通过规则引擎与小模型进行去噪、去重及敏感信息过滤。
- 联邦学习应用:为了解决隐私顾虑,部分App采用了联邦学习技术,数据不出本地,仅上传加密后的参数梯度,在保护用户隐私的前提下实现模型的实时进化。
算力成本与响应速度的平衡
实时训练对硬件资源消耗巨大,为了在移动端或Web端实现流畅体验,技术团队普遍采用了模型量化与投机采样技术,通过将模型参数从16位浮点数压缩为4位甚至更低,在不显著损失精度的前提下,将推理速度提升数倍,从而为实时训练腾出算力空间。
如何筛选与评估优质的大模型实时训练App
对于企业或个人开发者而言,面对市场上琳琅满目的工具,如何做出正确选择?花了时间研究大模型实时训练App,这些想分享给你,建议重点考察以下维度:
- API生态与兼容性:优质的App不应是信息孤岛,必须支持主流的开源模型架构(如Llama、Qwen等),并提供标准化的API接口,方便集成到现有的业务流中。
- 可视化监控面板:实时训练是一个黑盒过程,如果App能提供详细的Loss曲线、准确率变化及资源占用监控,将极大提升开发者的掌控感与调试效率。
- 回滚与版本管理能力:实时更新意味着风险,一旦新数据导致模型“变傻”,系统必须支持一键回滚到上一个稳定版本,这是业务安全的重要保障。
行业应用场景深度解析
理论必须服务于实践,大模型实时训练App已在特定场景展现出不可替代的价值:
- 智能客服领域:通过实时学习最新的产品手册与客诉案例,客服机器人的问题解决率可提升30%以上,且能即时适应新的营销话术。
- 金融风控场景:金融市场瞬息万变,实时训练App能迅速捕捉最新的欺诈特征与交易模式,将风控模型的响应周期从周级缩短至小时级。
- 个人知识助手:针对个人用户,App能实时读取用户的文档、笔记甚至浏览记录,构建专属的“第二大脑”,实现信息的个性化检索与生成。
未来趋势展望
随着端侧AI芯片性能的提升,大模型实时训练App将逐渐从“辅助工具”演变为“智能代理”,未来的模型将不再是静态的代码库,而是具有生命力的数字体,能够通过与用户的每一次交互实现自我进化。“所练即所得”将成为现实,但前提是必须解决好算力能耗比与模型可控性之间的矛盾。

相关问答模块
问:大模型实时训练App是否适合个人开发者使用?
答:非常适合,但需区分使用场景,对于个人开发者而言,从零构建实时训练系统成本过高,但利用现有的成熟App平台(如Hugging Face生态下的各类微调工具或国内的ModelScope相关应用),可以低成本实现个性化模型的定制,重点在于利用云端算力进行轻量级的LoRA微调,而非全量训练,这样既经济又高效。
问:实时训练会导致模型产生“幻觉”或偏见加剧吗?
答:存在这种风险,这也是实时训练必须配合强有力监督机制的原因,如果输入的新数据包含偏见或错误信息,模型确实可能产生“幻觉”,专业的实时训练App都会引入RLHF(人类反馈强化学习)机制或严格的奖励模型,对模型的输出进行实时打分与纠偏,确保模型在实时进化的同时,价值观与准确性保持在安全范围内。
便是关于大模型实时训练App的深度解析,如果你在实际应用中有更好的技术方案或遇到了具体的瓶颈,欢迎在评论区留言交流。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/151251.html