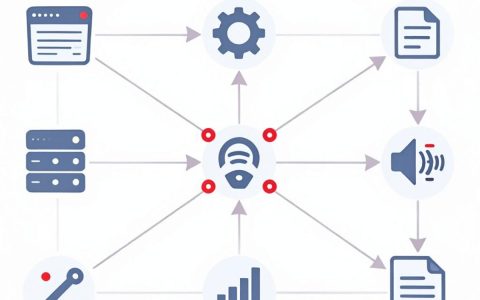
多个AI大模型协同运作并非简单的技术堆砌,而是构建智能化生态系统的必经之路,我的核心观点十分明确:单一模型已无法满足复杂业务场景的需求,构建“专精模型+通用模型”的组合流水线,才是实现降本增效、突破能力瓶颈的最优解,这种多模型流程不仅仅是工具的叠加,更是一种策略性的资源分配与任务编排,它要求我们根据不同模型的特性,精准匹配业务环节,从而实现整体效能的最大化。

关于多个ai大模型流程,我的看法是这样的:未来的AI应用竞争,本质上将是模型编排能力的竞争,企业若想在这一轮技术浪潮中站稳脚跟,必须从单一依赖转向多元协同,建立起一套高效、稳定且可控的模型调度机制。
为什么要采用多模型协同流程?
在实际的业务落地中,我们经常会遇到“不可能三角”的困境:即无法同时满足低成本、高速度和高精度,单一的大模型,即便是GPT-4这样的顶级模型,也难以在所有维度上都表现完美。
-
能力互补原则:
通用大模型(如GPT-4、Claude)知识面广,逻辑推理能力强,但往往缺乏特定行业的深度知识,且调用成本高昂,而垂直领域的开源小模型(如Llama系列微调版、行业专用模型),虽然在通用任务上表现一般,但在特定任务(如医疗报告生成、法律文书审核)上往往能超越通用模型,且部署成本极低。通过多模型协同,我们可以用小模型处理常规任务,大模型处理复杂推理,实现性价比的最优配置。 -
风险对冲与稳定性:
依赖单一模型供应商存在极大的业务风险,一旦API接口波动、服务中断或价格调整,业务将直接停摆。多模型架构天然具备容灾能力,当主模型响应异常时,系统可无缝切换至备用模型,保障业务连续性。 -
数据隐私与合规:
涉及核心机密数据的处理,往往不适合上传至公有云大模型,采用“本地私有化模型处理敏感数据+云端大模型处理非敏感数据”的混合流程,是解决数据安全顾虑的唯一可行方案。
构建高效多模型流程的核心策略
要搭建一套成熟的多模型工作流,不能盲目拼凑,必须遵循严谨的工程逻辑。核心在于“路由分发”与“结果聚合”两个关键环节。
智能路由分发机制
这是多模型流程的大脑,系统需要具备识别任务属性的能力,根据任务的难度、类型和实时性要求,将请求分发至最合适的模型。
- 基于规则的分流:对于格式固定、逻辑简单的任务(如摘要生成、关键词提取),直接路由至轻量级模型。
- 基于模型的分流:引入一个小参数的分类模型,对用户意图进行预判,如果意图涉及复杂逻辑推理或代码生成,则自动路由至旗舰级大模型。
- 成本控制策略:设定阈值机制,当单次请求Token消耗预估超过一定数值时,自动拆解任务,分配给多个小模型并行处理。
级联处理与结果优化

对于高精度要求的任务,单次生成往往难以达标,此时需要引入级联流程。
- 生成-审核循环:第一个模型负责生成初稿,第二个模型(通常具备特定审核能力)负责校对和修正,在公文写作场景中,通用模型生成内容,专用模型检查格式与合规性。
- 多模型投票机制:对于关键决策,可让三个不同架构的模型同时处理,通过“少数服从多数”或“加权评分”的方式选出最优解。这种方式能显著降低模型“幻觉”带来的风险。
实施过程中的痛点与专业解决方案
尽管理论完美,但在落地执行时,多模型流程面临着诸多挑战,基于实战经验,我总结了以下关键问题及对策。
提示词工程的碎片化难题
不同模型对提示词的敏感度差异巨大,GPT系列偏好结构化指令,而某些开源模型对复杂的Few-shot示例支持不佳。
- 解决方案:建立提示词中间件层,在发送给具体模型前,系统根据目标模型的特性,自动转换提示词格式,将统一的Markdown格式指令,自动转换为适合特定模型的JSON格式或对话历史格式,这大大降低了维护成本,实现了“一次编写,多处运行”。
上下文记忆的同步问题
在多轮对话中,如果涉及模型切换,如何保持上下文的一致性是一个技术难点。
- 解决方案:引入独立的向量数据库作为全局记忆中枢,不依赖模型自身的上下文窗口,而是将对话历史向量化存储,每当模型切换时,先从向量库中检索相关历史信息,构建新的Prompt注入当前模型,这样,无论后端模型如何变换,用户感知到的对话主体始终是连贯的。
延迟与响应速度的平衡
多模型串行处理势必会增加响应时间。
- 解决方案:采用并行处理与流式输出,在需要多模型协作的场景下,尽可能让模型并行工作,在长文本生成中,可以让多个模型分别负责不同章节的撰写,最后由一个模型进行统稿,开启流式传输,让用户看到“打字机”效果,优化等待体验。
未来展望:从“调用”走向“编排”
关于多个ai大模型流程,我的看法是这样的:我们正处于从“提示词工程”向“智能体编排”过渡的关键时期,未来的多模型流程将不再需要人工硬编码路由规则,而是由AI Agent自主判断任务需求,动态调用工具和模型。

企业现在的重点,应当放在构建标准化的模型接口层和数据资产沉淀上。谁先掌握了高效调度多个AI大模型的能力,谁就拥有了更低的边际成本和更高的业务护城河。 这不仅是技术架构的升级,更是企业数字化转型的战略高地。
相关问答
问:中小企业没有强大的技术团队,如何落地多模型流程?
答:中小企业可以优先选择集成了多模型能力的中间件平台或Agent开发平台,这些平台通常已经封装好了模型路由和API管理功能,企业只需关注业务逻辑配置,无需从零开发底层架构,利用开源的编排工具(如LangChain、Dify等)也能快速搭建起原型,逐步迭代。
问:多模型流程会不会导致数据泄露风险增加?
答:风险确实存在,但可控,关键在于建立严格的数据分级分类机制,在流程设计之初,就应明确哪些数据可以流向公有云模型,哪些必须留在本地,通过网关层对敏感信息进行脱敏处理,并在传输过程中采用加密通道,可以有效规避数据泄露风险,合理的多模型架构(本地+云端)反而比单一公有云模型更安全。
您在目前的业务场景中,更倾向于使用单一强力模型,还是尝试构建多模型协作流程?欢迎在评论区分享您的实践经验。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/151324.html