到2026年,大模型开发已彻底告别“炼丹”时代,全面转向工业化落地与智能体(Agent)构建,核心工作不再是单纯的模型预训练,而是基于通用基座模型进行垂直领域适配、复杂智能体系统编排、以及高效推理部署架构的搭建,开发者必须从算法研究者转变为AI应用架构师,核心价值在于解决“最后一公里”的落地问题,实现从“对话”到“行动”的跨越。

基座模型选型与垂直领域精调
2026年的大模型生态呈现“一超多强”格局,通用大模型已具备极强的泛化能力,开发者的首要任务并非从头训练,而是精准选型与精调。
- 数据工程成为核心竞争力,高质量、行业专属的数据集是护城河,开发者需构建自动化数据清洗流水线,将企业私有文档、业务日志转化为模型可理解的知识。
- 参数高效微调(PEFT)常态化,全量微调成本过高且容易导致灾难性遗忘,LoRA、P-Tuning等技术成为标配,开发者需掌握在少量算力下,将通用模型改造为懂业务、懂流程的专家模型。
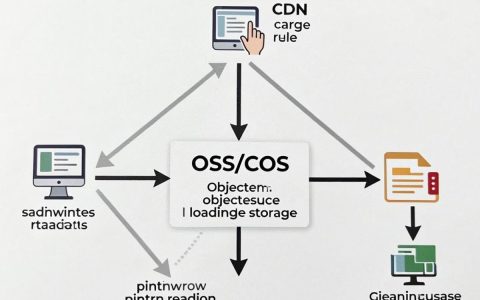
- 检索增强生成(RAG)的深度优化,简单的向量检索已无法满足精度需求,混合检索、重排序、以及知识图谱与RAG的结合,是提升模型回答准确率的关键,开发者需构建动态知识库,解决模型幻觉问题。
智能体开发与工具链集成
这是2026年大模型开发最大的变化,模型不再仅仅是生成文本,而是通过Agent架构操控软件、执行任务。
- 多智能体协作框架搭建,单一Agent难以处理复杂任务,开发者需设计“管理者-执行者”架构,一个Agent负责需求分析,另一个负责代码生成,第三个负责测试,通过协同完成软件开发全流程。
- 工具调用能力开发,大模型需要连接API、数据库、操作系统,开发者需定义标准化的工具接口,让模型能够自主决策何时调用浏览器、何时读取Excel、何时发送邮件。
- 记忆与规划机制设计,让模型具备长期记忆和反思能力,开发者需引入向量数据库存储历史交互,设计思维链提示策略,使Agent能够拆解复杂目标,规划执行步骤,并在失败后自动重试。
推理优化与系统架构工程化

随着模型应用规模扩大,推理成本和延迟成为瓶颈,工程化能力决定了产品的商业可行性。
- 模型量化与蒸馏技术,将千亿参数模型压缩至百亿甚至更小,使其能在端侧设备(手机、PC)流畅运行,是开发重点,量化技术如GPTQ、AWQ需熟练掌握。
- 推理服务架构设计,利用vLLM、TensorRT-LLM等框架,实现高并发、低延迟的推理服务,需关注KV Cache管理、动态批处理,确保服务在高负载下稳定运行。
- 端云协同部署,隐私敏感型任务在端侧处理,复杂计算型任务在云端处理,开发者需设计混合架构,平衡性能、成本与数据安全。
安全对齐与合规性保障
2026年,AI安全不再是可选项,而是必选项,监管政策完善,要求开发过程必须合规。
- 红队测试自动化,建立自动化攻击脚本库,模拟恶意Prompt注入、越狱攻击,提前发现模型漏洞。
- 内容风控系统构建,在模型输入输出层增加安全围栏,过滤敏感信息,确保生成内容符合法律法规与伦理道德。
- 可解释性研究应用,通过归因分析、注意力可视化等手段,解释模型决策逻辑,满足金融、医疗等高风险领域的审计要求。
开发范式转变:从代码驱动到意图驱动
开发者的工作流发生根本性变革。

- Prompt Engineering工程化,提示词不再是简单的自然语言,而是包含变量、逻辑判断、上下文管理的“伪代码”。
- 低代码/无代码平台集成,大模型开发平台降低了门槛,开发者更多时间花在业务逻辑梳理、流程编排上,而非底层代码编写。
- 全生命周期管理,监控模型在生产环境的表现,收集Bad Case,持续迭代数据与模型,形成数据飞轮效应。
相关问答
2026年大模型开发还需要从头训练模型吗?
绝大多数应用场景不需要,从头训练千亿参数模型需要数千张GPU和海量数据,这是头部大厂的业务,对于大多数企业与开发者,核心工作是基于开源或闭源基座模型,利用行业数据进行微调和RAG增强,构建应用层解决方案,算力成本决定了“精调”优于“预训练”。
非技术背景的人员能进行大模型开发吗?
完全可以,2026年的开发工具已高度成熟,自然语言成为新的编程语言,通过智能体编排平台,业务人员可以通过拖拽组件、描述需求的方式构建AI应用,但具备编程基础、理解模型原理的开发者,能构建更稳定、性能更优的系统,解决复杂业务问题。
您认为2026年大模型开发最大的挑战是什么?欢迎在评论区分享您的观点。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/151439.html