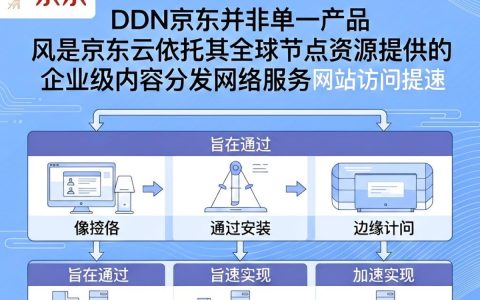
核心结论:当前大模型市场已进入“应用落地”与“垂直深耕”的决胜期,单纯比拼参数规模的时代正在终结,真正具备竞争力的模型,必须在通用基座能力、垂直场景精度以及私有化部署成本三者间找到最佳平衡点,深度了解各个公司大模型名称,说说我的看法,关键在于识别出那些能真正解决企业痛点、具备持续迭代能力的“实干型”选手,而非仅仅停留在概念炒作的“纸面巨人”。
头部阵营:通用能力的“军备竞赛”
在通用大模型领域,第一梯队玩家已构建起极高的技术壁垒,其核心优势在于海量数据训练与超大规模算力集群的协同效应。
- 百度文心一言系列:国内最早布局的模型之一,其核心优势在于搜索生态的深度融合,文心一言 4.5 版本在逻辑推理与长文本处理上表现稳健,特别适用于百度系产品(如搜索、文库)的智能化升级,拥有最成熟的中文语境理解能力。
- 阿里通义千问系列:依托阿里云庞大的电商与物流场景,通义千问在多模态理解(如视觉分析、代码生成)方面表现突出,其 Qwen-Max 版本在复杂任务规划上具有显著优势,是企业级应用的首选基座之一。
- 腾讯混元系列:深度绑定微信生态,混元大模型在社交场景与广告营销领域具备天然的数据优势,其强大的内容生成能力,使其在短视频脚本、营销文案等 C 端应用中极具竞争力。
- 华为盘古大模型:不同于纯互联网大厂,盘古大模型主打产业数字化,在气象预测、矿山开采、电力巡检等B 端工业场景中,盘古展现了极强的专业性与落地能力,是“模型 + 行业知识”结合的典范。
垂直赛道:细分领域的“破局者”
随着通用模型趋同,垂直领域的专业模型正成为新的增长极,这类模型往往参数量适中,但领域知识密度极高。
- 医疗领域:讯飞星火与多家三甲医院合作,构建了医疗垂直知识库,在辅助诊断、病历生成等场景下,准确率远超通用模型。
- 法律领域:法研所与多家科技公司联合开发的法律大模型,专注于法条检索与案情分析,能有效降低律师检索成本,提升文书撰写效率。
- 代码领域:月之暗面(Kimi)与智谱 AI 在长文本处理与代码生成方面表现优异,Kimi 的百万级上下文窗口能力,使其在处理长篇财报、技术文档时具有不可替代性。
深度洞察:模型选择的核心逻辑
在深度了解各个公司大模型名称,说说我的看法,我认为企业不应盲目追求“最强模型”,而应遵循以下选型逻辑:
- 数据主权优先:对于金融、政务等敏感行业,私有化部署是底线,必须选择支持本地化部署、数据不出域的模型方案,确保核心资产安全。
- 推理成本可控:大模型运行成本高昂,需评估模型的推理延迟与Token 消耗,选择性价比更高的量化版本或蒸馏模型,以实现商业闭环。
- 生态兼容性:模型必须能无缝接入现有业务系统,选择拥有丰富API 接口、开发者工具链完善的平台,能大幅降低集成难度与时间成本。
未来展望:从“大”到“强”的演进
未来的大模型竞争,将不再局限于参数量的堆砌,而是转向智能体(Agent)化与多模态融合。
- 智能体化:模型将从“对话者”转变为“执行者”,具备自主规划、工具调用与任务执行能力。
- 多模态融合:文本、图像、视频、音频的无缝切换将成为标配,模型将具备全感官理解世界的能力。
- 个性化定制:通过RAG(检索增强生成) 技术,企业可快速构建专属知识库,让模型成为懂业务、懂数据的“超级员工”。
相关问答模块
Q1:中小企业如何选择适合自己的大模型?
A1:中小企业应优先选择SaaS 化服务成熟的模型,避免自建高昂的算力成本,建议先通过 API 接口进行小规模测试,重点考察模型在特定业务场景(如客服、文案生成)的表现,并关注其响应速度与API 稳定性。
Q2:大模型是否会取代人类员工?
A2:大模型不会完全取代人类,而是重塑工作流,它将替代重复性、低价值的劳动(如数据录入、基础翻译),迫使人类员工向策略制定、创意构思、情感交互等高价值领域转型,人机协作(Human-in-the-loop)将是未来的主流模式。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/176766.html