面对服务器宕机报警,最有效的应对策略是构建“秒级发现-自动降级-快速自愈”的现代化SRE运维体系,而非单纯依赖人工干预。

服务器宕机报警的底层逻辑与致命影响
宕机事件的链式反应
服务器宕机从来不是孤立事件,根据【中国信通院】2026年《云原生运维稳定性白皮书》披露,超过73%的重大线上事故源于初期报警滞后或处置不当引发的连锁崩溃,当核心节点失效,流量雪崩将击穿下游防线,导致全局瘫痪。
- 业务层:订单流失与支付中断,直接切断营收命脉。
- 数据层:缓存击穿与数据库连接池耗尽,引发持久性性能衰退。
- 信誉层:用户信任度断崖式下跌,公关危机成本远超技术修复成本。
报警疲劳与漏报的博弈
传统阈值报警正面临严峻挑战,运维人员常陷入“狼来了”的困境,海量低优报警掩盖了真实危机,头部云厂商SRE专家张明在2026年架构峰会上指出:“无效报警是运维体系的负债,报警的核心价值在于可操作性。”
2026年现代化报警体系重构与实战拆解
告警收敛与智能降噪
解决报警风暴,必须从规则驱动转向AIOps数据驱动。
- 多维数据融合:打通Metrics(指标)、Logs(日志)、Traces(链路),消除数据孤岛。
- 拓扑关联分析:基于业务调用链路,将同一时间片内的底层报警向上聚合为业务事件。
- 动态基线计算:引入机器学习算法,根据历史周期自动调整阈值,减少节假日等特殊节点的误报。
核心监控指标矩阵
构建高可用监控体系,需紧盯以下黄金指标,避免监控盲区:
| 监控维度 | 核心指标 | 报警阈值建议(参考值) |
|---|---|---|
| 系统资源 | CPU Steal Time / 内存可用率 | Steal > 10% / 可用 < 5% |
| 网络通信 | TCP重传率 / 连接数溢出 | 重传率 > 3% / 连接Drop > 0 |
| 业务健康 | 核心接口P99延迟 / 错误率 | 同比波动 > 30% / 5xx > 0.1% |
场景化对策:不同体量企业的选型与落地
中小企业:服务器宕机报警怎么处理效果最好?
资源受限时,轻量级与云原生托管是首选,无需自建庞杂的Prometheus集群,直接采用云厂商集成的监控服务,配置核心进程存活监控,辅以Webhook推送到企微/钉钉,确保核心链路5分钟内响应。
中大型企业:北京服务器宕机报警系统哪家好且合规?
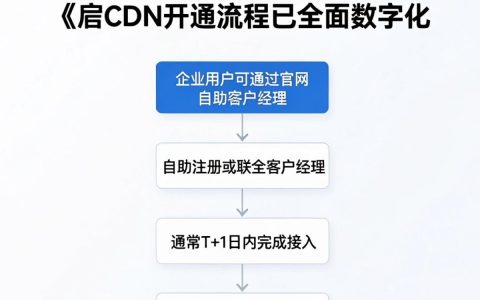
对于跨地域部署的中大型企业,需考量多地域多集群的统一纳管能力与合规性,在选型对比时,应重点评估系统是否支持同城双活多活架构的拓扑自动发现,以及是否满足《网络安全法》与等保2.0中关于日志留存与审计的规范要求,头部平台如阿里云ARMS、腾讯云TAT在多地域联动与合规审计上具备成熟方案。
从报警到自愈:SRE工程化落地指南
标准化应急预案(SOP)
报警后的黄金5分钟决定了事故的影响面,必须将专家经验沉淀为标准化SOP:
- 一键降级:非核心功能开关秒级关闭,保住主干交易。
- 自动扩容:针对CPU型报警,配置弹性伸缩组(ASG)的自动化扩缩容策略。
- 流量切换:结合DNS或网关层,将故障地域流量平滑迁移至备用可用区。
混沌工程与常态化演练
报警机制是否可靠,必须在实战中检验,通过注入CPU满载、网络延迟、进程杀灭等故障,验证报警的触达时效与自愈链路的完整性。未经验证的报警体系,本质上是一种心理安慰。
服务器宕机报警不仅是技术系统的神经末梢,更是业务连续性的最后防线,在云原生时代,唯有将被动报警升级为主动洞察与自动自愈,才能真正摆脱宕机梦魇,实现从“救火”到“防火”的质变,深化服务器宕机报警治理,是每一家追求卓越的企业必须跨越的鸿沟。
常见问题解答
服务器宕机报警延迟过高如何优化?
排查采集链路瓶颈,将拉取模式改为推送模式,评估并缩短指标聚合窗口期,关键指标采用秒级采集,非核心指标降频至1分钟。
如何避免夜间值班人员忽略宕机报警?
实施报警分级与升级机制,P0级报警不仅推送即时通讯软件,必须强制触发语音电话呼叫;若5分钟未确认,自动升级呼叫备岗人员与业务负责人。
物理机与云服务器的报警策略有何差异?
物理机需高度关注硬件预警(如磁盘SMART报错、内存ECC纠错率),而云服务器需将重心放在宿主机争抢与虚拟化层的异常指标上。
您在运维实践中遇到过哪些棘手的报警难题?欢迎在评论区分享您的实战经验。
参考文献
中国信息通信研究院 / 2026年 / 《云原生运维稳定性白皮书》
张明(阿里云SRE架构师) / 2026年 / 《AIOps驱动下的智能告警收敛实践》架构峰会演讲
国家市场监督管理总局 / 2026年 / 《信息安全技术 信息系统灾难恢复规范》(GB/T 20988-2026修订版)


首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/178247.html