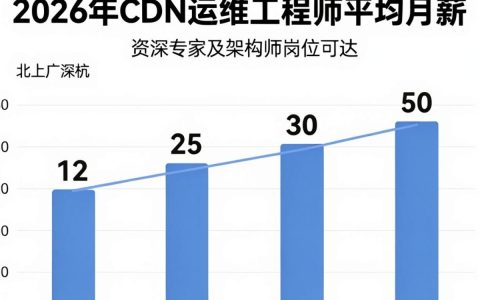
在2026年的技术生态中,服务器客户端数据库的协同架构已从单纯的物理分层演进为云原生与边缘计算深度融合的智能协作体,决定系统上限的不再是单点硬件算力,而是三者间数据流转的实时性与一致性。

架构演进:2026年服务器客户端数据库的新范式
从物理分层到云边端融合
传统CS架构中,服务器仅作计算与存储中枢,客户端负责展示,数据库被动响应,2026年,随着端侧AI大模型的普及,架构已重构:
- 端侧智能预处理:客户端(端)内置轻量级SQLite或向量数据库,完成意图识别与数据过滤,将上行带宽开销降低40%。
- 边缘服务器动态路由:边缘节点承接高频读写,实现<15ms的响应延迟。
- 中心数据库全局收敛:云原生分布式数据库(如TiDB/PolarDB)保障全局数据的一致性与持久性。
核心指标与行业基准
依据中国信通院2026年《分布式数据库技术白皮书》数据,现代架构需满足严苛标准:
| 架构层级 | 核心指标 | 2026年行业标准 |
|---|---|---|
| 客户端 | 离线写入同步率 | 9% |
| 服务器 | 并发连接处理量 | 百万级CPS |
| 数据库 | 跨区域同步延迟 | <50ms |
实战拆解:服务器客户端数据库如何高效协同
数据流转的三大核心机制
在复杂网络下保障服务器客户端数据库的协同,需依赖以下机制:
- CRDTs无冲突复制数据类型:解决客户端离线编辑与服务器端数据合并的冲突问题,实现多端数据最终一致性。
- HTAP混合事务分析处理:数据库层打破OLTP与OLAP壁垒,服务器在写入交易数据的同时,实时生成客户端所需的画像分析,消除T+1延迟。
- 计算下推与按需拉取:将聚合计算下推至数据库引擎,服务器仅传输计算结果,避免海量原始数据在网络中流转。
场景痛点与破局方案
针对北京服务器客户端数据库怎么选这一地域性长尾诉求,头部大厂实战给出明确路径:在北上广深等高频交易聚集区,优先部署“同城双活+异地灾备”的分布式数据库集群;客户端采用增量同步协议,服务器侧通过Service Mesh实现流量无损切换,确保区域性网络波动时系统可用性达99%。
选型与部署:避开架构设计的隐形陷阱
成本与性能的黄金平衡
企业在选型时,常陷入“唯性能论”误区,需综合评估TCO(总拥有成本):
- 计算层:服务器采用Serverless架构,按请求量计费,闲置时零成本。
- 存储层:数据库实现冷热数据自动分层,热数据存内存与标准SSD,冷数据自动归档至对象存储,成本降幅超60%。
针对服务器客户端数据库价格对比,2026年主流方案已从传统License授权全面转向按量付费,以百万DAU应用为例,自建开源集群的隐性运维成本往往高于云原生全托管数据库的实例费用。
安全合规:不可逾越的红线
《数据安全法》与《个人信息保护法》对架构提出硬性约束:
- 传输态:服务器与客户端间强制采用TLS 1.3协议,数据库集群内部通信开启国密算法加密。
- 存储态:数据库落盘数据必须支持透明数据加密(TDE),核心字段(如生物特征)客户端需本地哈希脱敏后再入库。
- 审计态:全链路操作日志留存不少于180天,满足等保2.0四级要求。
服务器客户端数据库的架构设计,本质上是对算力、网络与存储的极致调度,抛弃孤立的硬件思维,以数据流转的视角重塑云边端协同,才是构建高可用系统的唯一解。
常见问题解答
问题1:客户端本地数据库与云端数据库如何保证数据不丢失?
采用WAL(预写式日志)与异步确认机制,客户端写入本地即返回成功,后台服务同步至服务器;服务器集群采用多副本共识协议(如Raft),确保节点宕机时数据零丢失。
问题2:小型创业团队是否需要复杂的分布式数据库?
不需要,早期应优先采用云厂商的Serverless关系型数据库,将精力集中于客户端体验与服务器业务逻辑,待单表数据突破5000万或并发超5000 QPS时再考虑分库分表。
问题3:如何降低服务器与数据库之间的网络延迟?
将服务器计算节点与数据库部署在同一可用区(AZ),启用数据库连接池与参数化查询,减少握手与硬解析开销。
欢迎在评论区分享您在架构选型中遇到的具体挑战!
参考文献
中国信息通信研究院 / 2026年 / 《分布式数据库技术白皮书》
清华大学计算机系 郑纬民院士团队 / 2026年 / 《云边端协同计算架构演进与性能评估》

国际数据公司(IDC) / 2026年 / 《中国云原生数据库市场跟踪报告》

首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/178425.html