构建湖仓一体数据仓库在2026年不仅是好的选择,更是大多数中大型企业打破数据孤岛、实现实时智能决策的必然趋势,尽管初期架构复杂度较高,但其长期价值远超传统方案。
过去几年,数据架构领域经历了一场深刻的变革,传统的“数据湖”虽然便宜且能容纳海量非结构化数据,但数据质量差、管理混乱,被戏称为“数据沼泽”;而传统的“数据仓库”虽然查询快、一致性高,但存储成本高,且难以处理视频、日志等非结构化数据,湖仓一体(Lakehouse)应运而生,它试图融合两者的优势:既拥有数据湖的低成本扩展性,又具备数据仓库的高性能查询和AC事务支持,对于正在寻求数字化转型的企业来说,理解这一架构的利弊至关重要。
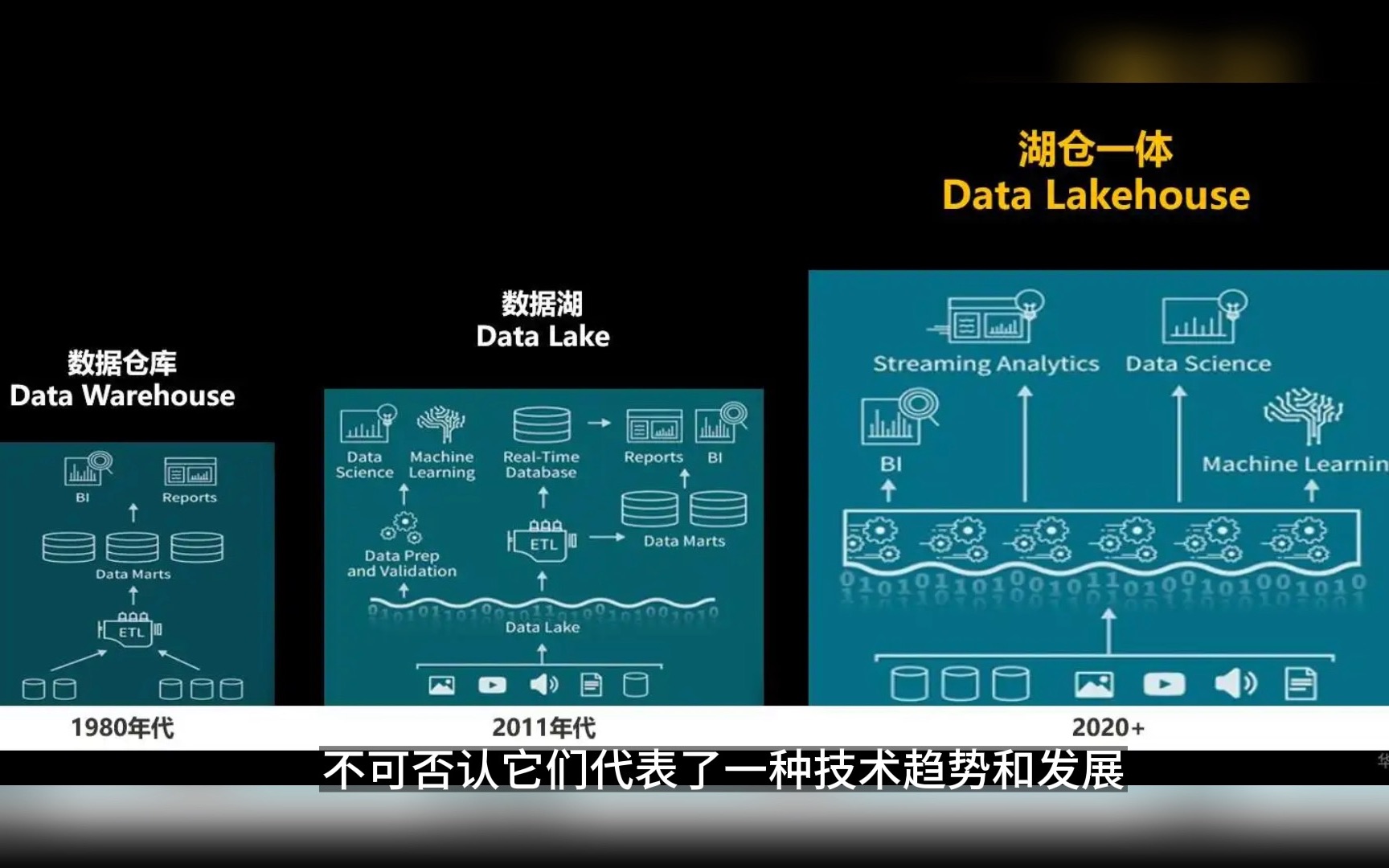
湖仓一体架构的核心优势解析
湖仓一体并非简单的技术堆砌,而是底层存储格式与计算引擎的深度协同,业内专家指出,这种架构通过统一的数据存储层,消除了数据在湖和仓之间频繁搬运的需求,从而大幅降低了数据延迟和出错概率。
消除数据冗余与延迟
在传统架构中,数据需要从数据湖ETL清洗后加载到数据仓库,这个过程往往需要数小时甚至数天,湖仓一体架构允许数据源直接写入统一的存储层,应用层可以直接查询最新数据。
- 实时性提升:多数情况下,数据从产生到可分析的时间从小时级缩短至分钟级甚至秒级。
- 单一事实来源:无需维护多套数据副本,减少了数据不一致的风险。
成本效益的显著优化
存储成本是企业IT支出的大头,湖仓一体通常基于对象存储(如AWS S3、阿里云OSS),其成本远低于传统数据仓库的专用存储。
- 存储成本降低:据行业共识认为,采用对象存储后,数据湖的存储成本可比传统方案降低50%以上。
- 计算存储分离

:计算资源和存储资源独立扩展,避免了资源闲置或瓶颈,尤其在应对突发流量时更具弹性。

实施湖仓一体面临的挑战与痛点
尽管前景广阔,但并非所有企业都适合立即转型,构建湖仓一体数据仓库好不好?答案取决于你的数据成熟度和技术能力,如果盲目上马,可能会陷入新的困境。
数据治理的复杂性增加
数据湖的开放性意味着任何人都可以写入数据,如果缺乏严格治理,湖仓一体也会变成“数据沼泽”。
- 元数据管理难题:需要建立统一的元数据目录,确保数据可发现、可理解。
- 数据质量监控:必须引入自动化数据质量检查机制,防止脏数据污染分析结果。
技术栈的学习曲线陡峭
湖仓一体涉及多种开源技术栈,如Apache Iceberg、Hudi、Delta Lake等,选择哪种格式、如何配置权限、如何优化查询性能,都需要专业的数据工程师团队支持。
- 人才稀缺:具备湖仓一体架构设计经验的人才在市场上供不应求。
- 运维难度:分布式系统的运维复杂度远高于传统单体数据库,需要完善的监控和告警体系。
2026年主流湖仓一体技术选型对比
在2026年,市场上主流的湖仓一体实现方案主要集中在三大开源表格格式上,了解它们的差异,有助于企业做出正确的技术选型。
Apache Iceberg vs Delta Lake vs Hudi
这三种格式各有侧重,适用于不同的业务场景。
| 特性 | Apache Iceberg | Delta Lake | Apache Hudi |
|---|---|---|---|
| 主要推动者 | 社区主导,Netflix等大厂贡献 |
Databricks主导 | Uber主导 |
| 兼容性 | 高度兼容Spark、Trino、Presto等 | 深度绑定Spark生态 | 支持Flink、Spark |
| 更新性能 | 优秀,支持小文件合并 | 优秀,支持UPSERT | 优秀,支持增量读取 |
| 适用场景 | 多引擎共存、大规模批处理 | 实时ETL、流批一体 | 高频更新、近实时分析 |

如何选择适合你的方案
- 如果你使用Databricks平台:Delta Lake是原生支持的最佳选择,集成度最高。
- 如果你追求引擎无关性:Apache Iceberg因其开放性和广泛的引擎支持,成为许多云厂商的首选。
- 如果你需要高频更新数据:Apache Hudi在Upsert和增量读取方面表现优异,适合用户画像等场景。
构建湖仓一体数据仓库的实操路径
对于决定转型的企业,建议采取分阶段实施策略,避免一步到位带来的巨大风险。
第一阶段:基础架构搭建
- 选择存储层:基于云对象存储(如S3、OSS)建立统一数据湖。
- 引入表格格式:选择Iceberg或Delta Lake作为底层表格式,启用ACID事务。
- 配置计算引擎:部署Spark或Trino集群,用于数据读写和分析。
第二阶段:数据迁移与治理
- 存量数据迁移:将传统数据仓库中的核心表迁移至湖仓,验证数据一致性。
- 建立数据目录
:使用Apache Atlas或云厂商提供的元数据服务,建立数据血缘关系。
- 制定数据标准:明确命名规范、数据类型、分区策略等,确保数据质量。

第三阶段:应用赋能与优化
- 实时数据接入:通过Kafka或Flink将实时数据流写入湖仓,实现近实时分析。
- BI工具对接:连接Tableau、PowerBI等可视化工具,让业务人员直接查询湖仓数据。
- 性能调优:根据查询模式调整分区键、索引策略,优化查询速度。
常见疑问解答
构建湖仓一体数据仓库好不好,是否适合中小企业?
对于数据量较小、分析需求简单的中小企业,传统数据仓库或云数据仓库(如Snowflake、Redshift)可能更具性价比,湖仓一体更适合数据量大、类型复杂、需要实时分析的中大型企业,中小企业若选择湖仓一体,建议直接使用云厂商托管的湖仓服务(如阿里云Data Lake Analytics、AWS Lake Formation),以降低运维成本。
湖仓一体与数据湖仓的区别是什么?
“数据湖仓”(Data Lakehouse)是“湖仓一体”的另一种表述,两者在概念上基本一致,但在某些语境下,“湖仓一体”更强调架构的统一性,而“数据湖仓”可能更侧重于产品形态,无论名称如何,核心都是指统一存储、统一计算、统一治理的数据架构。
湖仓一体架构的维护成本如何?
初期搭建和治理成本较高,需要投入专业团队进行元数据管理和数据质量监控,但长期来看,由于消除了数据搬运和冗余存储,运维成本会显著降低,据统计,成熟湖仓一体架构的总拥有成本(TCO)通常低于传统混合架构。
构建湖仓一体数据仓库不是万能药,但它是应对大数据时代复杂挑战的有力武器,企业应根据自身数据规模、技术能力和业务需求,审慎评估,稳步实施。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/205394.html










