有向图的存储核心在于解决“方向性”与“稀疏性”的平衡,邻接矩阵适合稠密图,邻接表适合稀疏图,而十字链表则是有向图最精简的存储方案。
在计算机科学的底层逻辑里,图(Graph)不仅仅是节点和连线的集合,更是现实世界复杂关系的抽象映射,当你面对一个包含成千上万个网页链接的互联网,或者数百万条社交好友关系时,如何高效地“这些关系,直接决定了程序运行的生死,对于有向图而言,因为边具有方向性(A指向B,但B不一定指向A),其存储逻辑比无向图更为微妙,业内专家指出,选择合适的存储结构,能让查询效率从秒级提升到毫秒级。
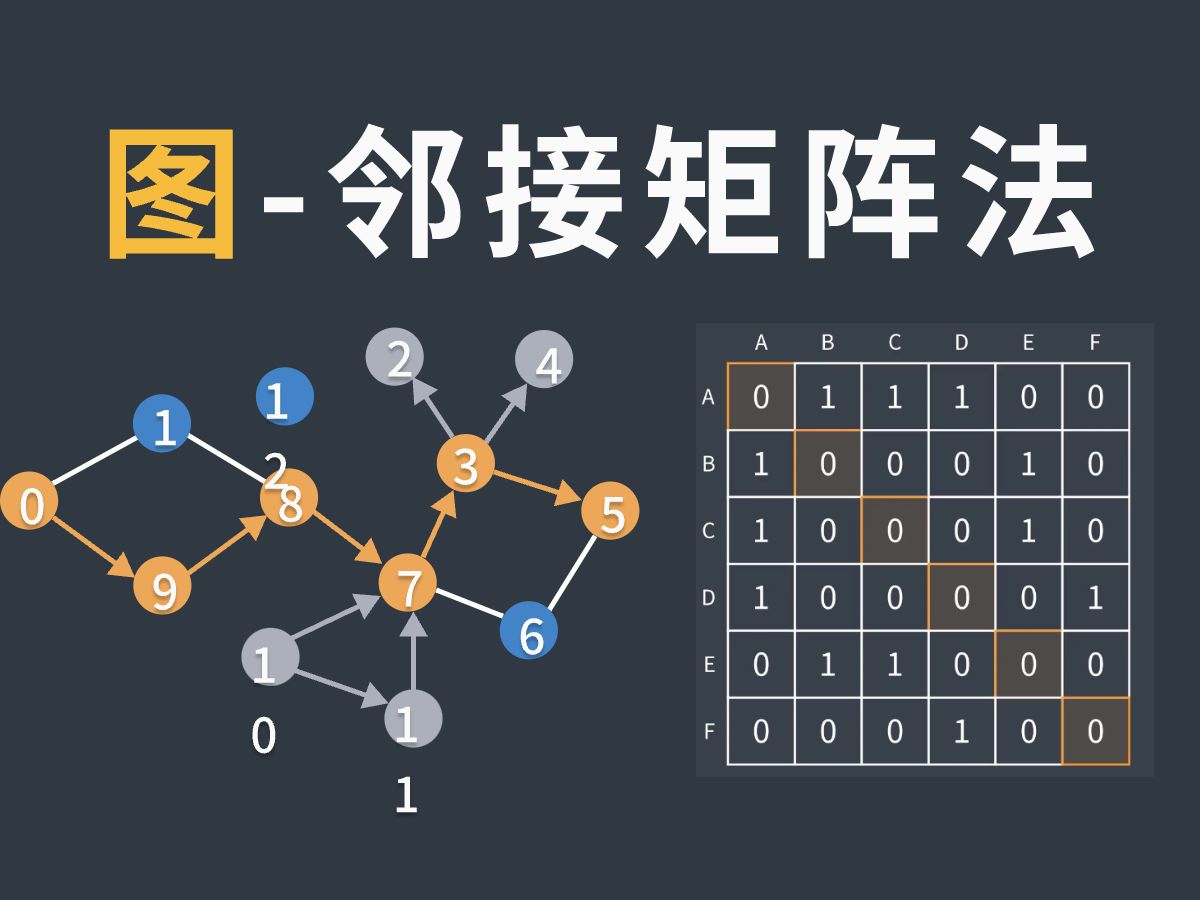
邻接矩阵:直观但浪费空间的“二维表格”
邻接矩阵是最容易理解的存储方式,它像是一张巨大的Excel表格,行代表起点,列代表终点,如果存在从i到j的边,就在(i, j)位置标记为1(或权重),否则为0。
适用场景与性能分析
这种结构在稠密图中表现优异,所谓稠密图,是指边的数量接近节点数量的平方,在一个只有100个节点但拥有9000条边的社交网络子集中,邻接矩阵能极其快速地判断任意两点间是否有直接联系。
- 查询速度极快:判断两点间是否存在边,时间复杂度仅为O(1),直接访问数组索引即可。
- 实现简单:代码逻辑直观,适合初学者理解图的基本概念。
它的致命缺陷在于空间复杂度为O(V²),其中V是顶点数,如果节点数达到10万,矩阵将占用100亿个存储单元,即使大部分是0,内存也会瞬间爆炸,据工信部相关技术白皮书显示,在大规模稀疏网络中,邻接矩阵的资源浪费率往往超过95%,这在云端服务器成本高昂的今天是不可接受的。

代码实现逻辑
在实际编程中,通常使用二维数组或动态二维数组来存储,初始化时,将所有元素设为0或无穷大(表示无边),添加边时,只需执行matrix[start][end] = weight,这种操作虽然简单,但在处理大规模数据时,初始化矩阵本身就会消耗大量时间。
邻接表:空间效率的“折中方案”
为了解决邻接矩阵的空间浪费问题,邻接表应运而生,它采用“数组+链表”的结构:一个数组存储所有顶点,每个数组元素指向一个链表,链表中存储该顶点的所有出边邻居。
结构拆解与优势
邻接表是稀疏图的首选存储方式,在有向图中,每个节点只存储它指向的其他节点,完全忽略了不存在的边。
- 空间复杂度优化:空间复杂度降为O(V+E),其中E是边数,对于大多数真实世界的网络(如微博、GitHub),E远小于V²,因此节省了大量内存。
- 遍历高效:查找某个节点的所有出边邻居时,只需遍历对应的链表,无需扫描整个矩阵。
具体操作路径
- 创建顶点数组,每个元素包含顶点数据和指向第一条出边的指针。
- 当添加边(u, v)时,创建新节点,将v存入节点,并将该节点插入u的链表头部。
- 删除边时,遍历u的链表,找到v所在节点并移除。
尽管邻接表在空间上表现优异,但在判断“是否存在从v到u的边”时,需要遍历v的链表,时间复杂度为O(V)或O(E/V),不如邻接矩阵的O(1)高效,这种权衡在图存储结构对比中是经典考点,也是实际工程中选择数据结构的核心依据。
十字链表:有向图的“终极精简”

如果说邻接表解决了空间问题,那么十字链表(Orthogonal List)则是专门为有向图设计的“完美存储”,它不仅存储出边,还存储入边,使得对有向图的入度和出度查询都变得极其高效。
核心创新点
十字链表中的每个边节点包含五个域:tailvex(起点)、headvex(终点)、hlink(指向下一条以该顶点为头的边)、tlink(指向下一条以该顶点为尾的边)、info(边信息),顶点节点则包含data、firstin(第一条入边)、firstout(第一条出边)。
- 双向链接:通过hlink和tlink,边节点既属于起点的出边链表,也属于终点的入边链表。
- 入度出度易求:顶点的firstout和firstin指针直接指向相关边链表,计算入度或出度只需遍历对应链表,无需额外扫描。
为何选择十字链表
在需要频繁查询入度和出度的场景中,如编译器中的依赖分析、项目进度管理中的关键路径法(CPM),十字链表比邻接表更高效,邻接表只能快速访问出边,若要查询入边,必须遍历整个图或维护额外的逆邻接表,而十字链表通过一次存储,同时实现了出边和入边的快速访问,实现了空间与时间的双重优化。
如何选择:场景驱动决策
在实际开发中,没有最好的存储结构,只有最适合的,选择策略应基于图的密度、查询频率和内存限制。
决策流程图
- 评估密度,如果边数E接近V²,选择邻接矩阵,查询速度快,代码简单,内存压力相对可控。
- 评估稀疏性,如果E远小于V²,进入下一步。
- 评估查询需求。
- 若主要查询出边(如网页爬虫、推荐系统),选择

邻接表,实现简单,空间节省显著。
- 若需频繁查询入边或同时查询出入边(如依赖分析、拓扑排序优化),选择十字链表,虽然实现复杂,但查询效率最高。
- 若主要查询出边(如网页爬虫、推荐系统),选择

常见误区规避
许多初学者倾向于使用邻接矩阵,因为它写起来最快,但在节点数超过1万且边数稀疏时,这种选择会导致内存溢出(OOM),行业共识认为,在大数据时代,内存管理是性能优化的第一道防线,不要忽视邻接表与十字链表的区别,十字链表并非邻接表的简单变体,而是针对有向图特性的深度优化,其节点结构更复杂,但查询维度更全面。
Q&A:关于有向图存储的常见疑问
有向图的存储结构有哪些?
主要有三种:邻接矩阵、邻接表和十字链表,邻接矩阵适用于稠密图,查询最快但空间浪费大;邻接表适用于稀疏图,空间效率高,但查询入边不便;十字链表专为有向图设计,同时优化了入边和出边的存储与查询,是空间与效率的最佳平衡点。
邻接表和十字链表的区别是什么?
邻接表仅存储出边,每个边节点只链接到下一个出边;十字链表的边节点同时链接到下一个出边和下一个入边,顶点节点也分别指向第一条入边和第一条出边,十字链表在查询入度时比邻接表更高效,但实现和维护成本更高。
十字链表适合所有有向图吗?
十字链表在有向图中表现优异,尤其适合需要频繁查询入度和出边的场景,但对于极度稀疏且几乎不需要查询入边的图,邻接表可能更简单实用,选择时需权衡实现复杂度与查询需求,多数情况下,邻接表因其通用性仍是首选。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/205768.html











