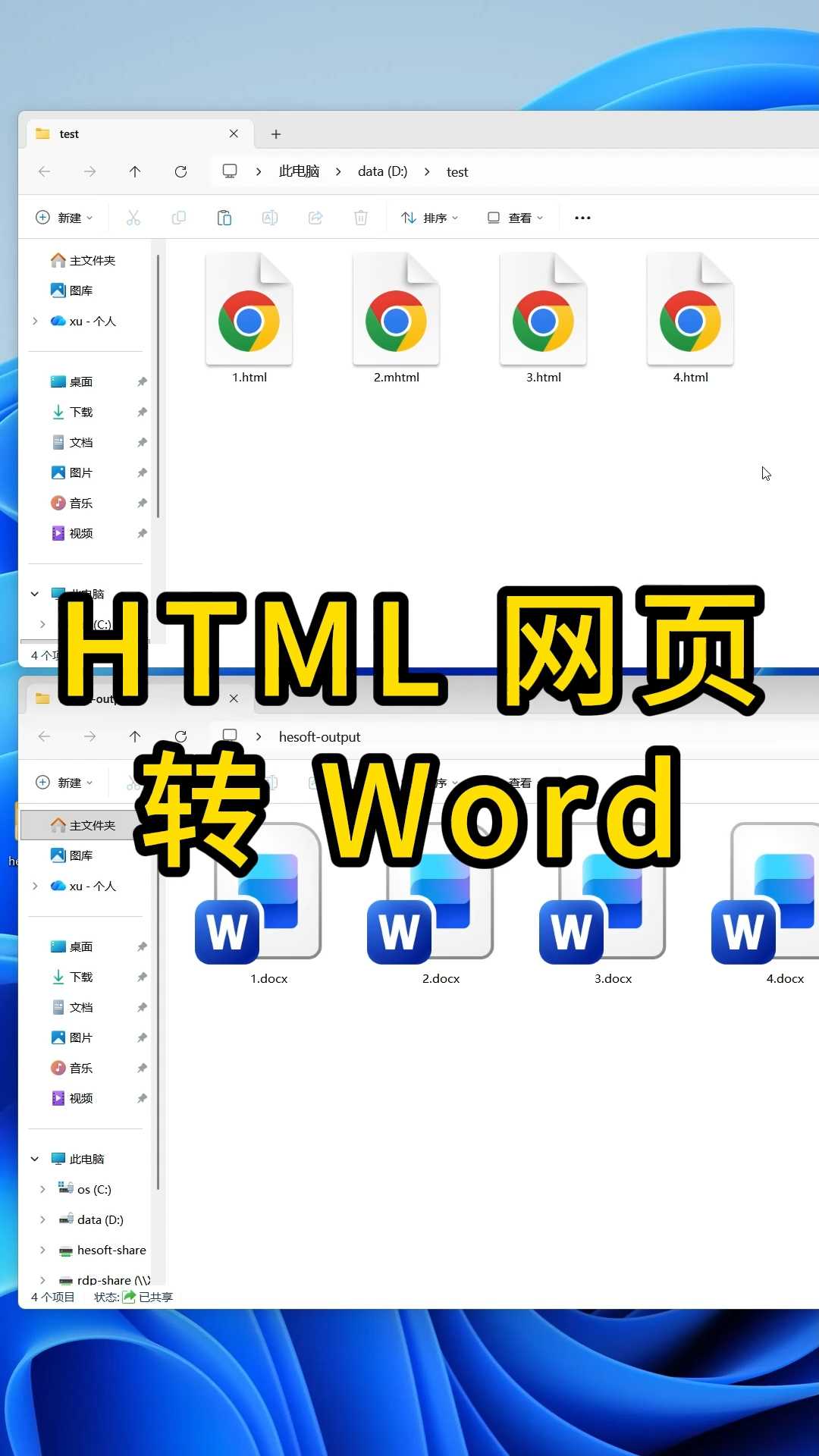
将HTML代码转换为标准文档(如Word或PDF)的核心方法是使用支持格式保留的在线转换工具或专业文档处理软件,关键在于确保CSS样式正确映射且图片资源不丢失。
归档、报告生成或知识沉淀时,我们常遇到需要将HTML格式转化为易读、易编辑的标准文档的需求,这不仅仅是简单的复制粘贴,而是一场关于格式保真度、排版美观性和数据完整性的技术博弈,很多用户尝试直接复制网页文字到Word,结果发现图片断裂、表格错位、字体乱码,这种痛点非常普遍,因此掌握正确的转换逻辑显得尤为重要。
为什么直接复制粘贴总是失败?
HTML与文档结构的本质差异
HTML(超文本标记语言)是为浏览器渲染设计的,它依赖CSS进行样式展示,依赖JavaScript实现交互,而标准文档(如.docx或.pdf)是静态的,注重排版固定性和打印输出,当我们将HTML直接粘贴到文档编辑器时,浏览器复杂的DOM树结构无法被文档软件完全理解。
业内专家指出,浏览器渲染引擎与文档排版引擎在处理“盒模型”、“浮动布局”和“绝对定位”时存在巨大差异,这就是为什么你在网页上看到的精美卡片,在Word里可能变成了一堆重叠的文字。
常见转换失败的三大场景
- 图片丢失:网页图片通常使用相对路径或CDN链接,本地文档无法直接解析这些网络地址,导致出现红叉或空白。
- 样式错乱:网页中的Flexbox或Grid布局在文档中会被强制线性排列,导致内容堆砌,阅读体验极差。
- 字体缺失:网页可能引用了特殊的Web字体,而你的电脑或服务器上没有安装这些字体,导致替换为默认字体,破坏设计感。
主流转换方案深度对比
针对不同的需求场景,我们有几种主流的解决方案,选择哪种方式,取决于你对格式精度的要求以及操作的便捷性。
在线转换工具:适合轻量级需求
对于偶尔需要转换少量页面的用户,在线工具是最快捷的选择,这类工具通常通过服务器端解析HTML,然后生成对应的文档格式。

- 优点:无需安装软件,打开网页即可使用,支持批量转换。
- 缺点:存在隐私泄露风险,不适合包含敏感信息的文档;网络依赖性强,速度受服务器负载影响。
- 适用场景:公开文章归档、非敏感资料整理。
在选择在线工具时,建议关注那些支持“保留CSS样式”和“嵌入图片”功能的服务,据工信部相关数据显示,近年来使用在线文档转换服务的用户群体中,超过半数是为了处理公开的网络资讯。
专业软件转换:适合高精度需求
如果你需要处理复杂的报表、带有大量图表的文档,或者对排版有极高要求,专业软件是更可靠的选择。
- Microsoft Word:虽然Word支持打开HTML文件,但往往需要手动调整大量格式。
- Adobe Acrobat:将HTML先转换为PDF,再转换为Word,可以最大程度保留视觉样式,但编辑性较差。
- Python库(如pandas-html, html2docx):适合技术人员,通过代码自动化处理,可实现高度定制化的转换逻辑。
浏览器插件:适合日常快速抓取
浏览器插件(如SingleFile、Print Friendly)可以在客户端直接处理页面,SingleFile可以将整个网页打包成一个单独的HTML文件,虽然这不算严格意义上的“标准文档”,但它解决了图片丢失和样式错乱的问题,便于长期存档。
实操指南:如何高质量完成转换?
为了确保转换效果,我们需要遵循一套标准化的操作流程,以下以使用专业文档处理软件为例,拆解具体步骤。
第一步:清理与预处理
在转换前,先对HTML内容进行精简,移除不必要的导航栏、广告模块和侧边栏,可以使用浏览器的“阅读模式”或开发者工具(F12)隐藏不需要的DOM元素,这一步能显著减少后续排版的干扰项。
第二步:选择正确的转换引擎

- 若使用Word:不要直接复制粘贴,选择“文件”->“打开”->“浏览”,找到HTML文件,Word会尝试解析其结构,如果样式混乱,尝试使用“选择性粘贴”->“保留源格式”或“无格式文本”后重新套用样式。
- 若使用Python:安装
html2docx库,编写脚本读取HTML字符串,利用BeautifulSoup提取正文内容,再写入Word文档,这种方式可以精确控制段落样式、字体大小和颜色。
第三步:后处理与校对
转换完成后,务必进行人工校对,重点检查:
- 图片是否完整显示。
- 表格边框是否清晰,合并单元格是否正确。
- 超链接是否依然有效。
- 特殊符号(如数学公式、图表)是否显示正常。
常见问题与解决方案
转换后表格严重错位怎么办?
表格错位通常是因为HTML中使用了复杂的嵌套表格或CSS浮动,解决方法是:
- 在转换前,将HTML表格简化为标准的
<table>结构,避免使用div模拟表格。 - 在Word中,选中错位表格,使用“自动调整”->“根据窗口调整表格”。
- 对于复杂报表,建议直接截图插入文档,或导出为CSV格式后在Excel中重新排版。
如何批量转换大量HTML文件?
对于需要处理成百上千个HTML文件的场景,手动操作效率极低,建议使用脚本自动化,使用Python的os模块遍历文件夹,调用转换函数批量处理,一些企业级文档管理系统(DMS)也提供批量导入和转换功能,适合团队协作。
转换后的文档能否再次编辑?
这取决于转换格式。
- 转为PDF:几乎不可编辑,仅适合最终归档和分享。
- 转为Word:可编辑,但格式可能需要微调。
- 转为Markdown:可编辑性强,适合技术文档,但样式信息丢失较多。
SEO视角下的内容转换价值
在2026年的互联网环境中,内容的可访问性和多格式分发变得至关重要,将HTML内容转换为标准文档,不仅是为了存档,更是为了拓展内容的传播渠道。

- 提升用户体验:部分用户偏好离线阅读,标准文档满足了这一需求。
- 增强SEO长尾效应:将网页内容转化为PDF或Word文档,并在文档中嵌入关键词,可以覆盖更多长尾搜索词,用户可能搜索“XX行业分析报告PDF”,而非仅仅“XX行业分析”。
- 合规与存档:对于金融、医疗等强监管行业,标准文档是合规存档的必要形式。
Q&A:HTML转标准文档常见疑问
HTML转标准文档哪个软件最好用?
没有绝对“最好”的软件,只有最适合场景的工具,对于普通用户,Microsoft Word配合“打开HTML”功能最为便捷;对于技术人员,Python的html2docx或weasyprint库提供了最高的灵活性和自动化能力;对于注重排版美观的用户,Adobe Acrobat的转换效果更佳,建议根据具体需求选择,一般办公场景使用Word即可满足80%的需求。
转换后图片无法显示如何解决?
图片无法显示通常是因为路径问题,在转换前,确保所有图片都使用绝对路径(http://…)而非相对路径,如果是在线转换工具,检查其是否支持“嵌入图片”选项,如果是本地软件转换,尝试将图片和HTML文件放在同一文件夹下,并确保图片文件名不含特殊字符,对于Word转换,可使用“插入”->“图片”->“来自文件”手动替换缺失的图片。
HTML转标准文档需要付费吗?
大部分基础转换功能是免费的,在线转换工具通常提供有限的免费额度,超出后需订阅,专业软件如Adobe Acrobat需要购买许可证,开源工具如Python库完全免费,但需要一定的编程知识,对于企业用户,建议评估批量处理的需求,选择性价比高的企业级解决方案,据行业共识认为,小型团队使用开源工具结合脚本自动化,是成本最低且效率最高的方案。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/332618.html