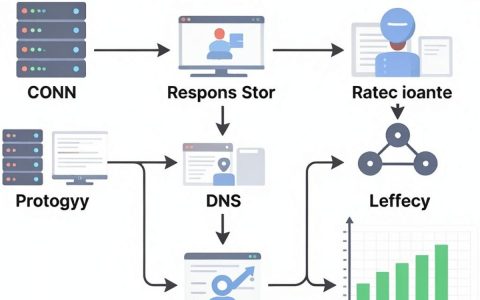
当移动应用提示“未找到指定主机服务器”时,核心原因是应用配置中的服务器地址解析失败或网络连通性受阻,通常通过检查DNS设置、防火墙规则或重新部署应用至正确分组即可解决。
移动应用至指定分组报错的常见成因分析
在企业管理软件或云原生架构中,将应用迁移到特定分组(Group)是常见的运维操作,这一过程往往伴随着网络层面的剧烈变动,当系统返回“未找到指定主机服务器”的错误代码时,这并非简单的软件故障,而是底层网络通信链路出现了断裂,业内专家指出,这类问题通常集中在域名解析、路由策略以及权限隔离三个维度。
DNS解析延迟与缓存污染
域名系统(DNS)是连接人类可读域名与机器可读IP地址的桥梁,在应用迁移场景中,如果目标分组使用了新的内部域名或负载均衡器地址,本地缓存可能仍指向旧的、已失效的节点。
- 缓存过期机制失效:许多企业级应用为了提升速度,会长期缓存DNS记录,当服务器IP变更而TTL(生存时间)未更新时,客户端持续向旧IP请求,导致连接超时。
- 内部DNS服务器不同步:在混合云环境中,本地数据中心与云端DNS服务器可能存在同步延迟,据统计,相当一部分此类故障源于DNS记录在集群间传播滞后,导致新节点尚未被全网识别。
网络隔离与安全组策略限制
“指定分组”往往意味着应用被移动到了不同的虚拟私有云(VPC)或子网段,不同分组之间默认可能存在严格的网络隔离策略。
- 安全组白名单缺失:目标分组的安全组可能未放行应用所需的特定端口(如8080、443或数据库端口)。
- 路由表缺失:如果应用跨AZ(可用区)或跨地域迁移,路由表中可能缺少指向新分组网段的静态路由或动态路由协议配置,导致数据包“迷路”。
如何快速排查app未找到指定主机服务器问题

面对这一报错,盲目重启服务往往收效甚微,我们需要按照从底层到上层的逻辑,逐步定位故障点,以下是一套经过验证的实操排查路径。
第一步:验证基础网络连通性
首先确认客户端是否能ping通目标服务器的IP地址,如果Ping不通,说明是物理或链路层问题;如果Ping通但应用无法连接,则是应用层或端口层问题。
- 使用Ping命令测试:在命令行输入
ping <目标IP>,若返回“请求超时”,请检查防火墙是否禁用了ICMP协议,或检查路由表。 - 使用Telnet或NC测试端口:执行
telnet <目标IP> <端口号>或nc -zv <目标IP> <端口号>,如果连接被拒绝,说明端口未监听或防火墙拦截。
第二步:检查应用配置与环境变量
应用迁移后,配置文件中的服务器地址可能未同步更新,特别是在容器化部署中,环境变量是动态注入的,容易遗漏。
- 核对配置文件:检查
application.yml或config.json中的server.host或database.url字段,确保其指向的是新分组的正确地址。 - 验证环境变量:在容器内部执行
env或printenv命令,确认关键变量(如DB_HOST、API_ENDPOINT)是否已正确加载。
第三步:审查负载均衡与健康检查
如果应用位于负载均衡器(SLB/ALB)之后,错误可能源于后端实例的健康检查失败。
- 检查健康检查状态:登录云控制台,查看负载均衡器的后端服务器组,若实例状态显示“异常”或“未注册”,则流量不会被转发。
- 验证健康检查路径:确认后端应用是否响应了负载均衡器设定的健康检查URL(如
/health或/status),若应用未实现该接口,或返回非200状态码,负载均衡器会将实例剔除。

移动应用至指定分组的最佳实践与预防策略
为了避免未来再次出现此类问题,企业应建立标准化的应用迁移流程,这不仅是技术操作,更是管理规范的体现。
自动化配置管理
手动修改配置极易出错,建议引入配置中心(如Nacos、Apollo或Consul)来管理应用配置。
- 配置版本化:将配置存储在Git中,通过CI/CD流水线自动同步到各分组。
- 环境隔离:为开发、测试、生产环境设置不同的配置命名空间,避免配置混淆。
网络架构的弹性设计
在设计应用架构时,应假设网络故障是常态,而非例外。
- 多可用区部署:确保应用分布在多个可用区,单一故障点不会导致整体服务不可用。
- 服务发现机制:使用Consul或Eureka等服务发现工具,让应用动态感知后端实例的变化,而非硬编码IP地址。
监控与告警前置
在问题发生前发出预警,比事后排查更为重要。
- 监控DNS解析时间:监控DNS查询的耗时,若解析时间突然增加,可能预示DNS服务器负载过高或存在劫持。
- 端到端链路追踪:部署APM(应用性能监控)工具,追踪请求从客户端到服务器的完整链路,快速定位瓶颈所在。
不同云厂商下的差异化处理细节
虽然核心原理相似,但不同云平台在实现上存在差异,了解这些差异有助于更精准地解决问题。
AWS环境下的处理
在AWS中,应用迁移通常涉及VPC对等连接或Transit Gateway的配置,若出现连接失败,需重点检查Route Tables(路由表)和NACLs(网络访问控制列表),NACL是无状态的,需同时放行入站和出站流量。
阿里云环境下的处理
阿里云用户需关注VPC路由表和安全组,特别是当应用跨地域迁移时,需开通云企业网(CEN)并配置路由传播,阿里云的SLB健康检查默认使用TCP连接,若应用仅监听HTTP,需确保TCP端口开放。

腾讯云环境下的处理
腾讯云的网络策略与阿里云类似,但其私有网络(VPC)的边界路由配置较为严格,在迁移应用时,需确保目标子网的路由条目正确指向网关或NAT设备。
Q&A关于app未找到指定主机服务器的问题
移动应用至指定分组后出现dns解析失败怎么办
若确认网络连通性正常,但应用仍无法解析域名,首先尝试清除本地DNS缓存,在Windows系统中执行 ipconfig /flushdns,在Linux系统中重启 systemd-resolved 服务或清除 nscd 缓存,若问题依旧,检查应用配置文件中的DNS服务器地址是否正确指向了企业内部DNS,而非公共DNS(如8.8.8.8),对于容器化应用,需在Dockerfile或Kubernetes配置中指定 dnsPolicy 为 ClusterFirst,以确保优先使用集群内部DNS。
应用迁移到新分组后端口无法访问
端口无法访问通常由防火墙或安全组规则引起,首先确认应用进程是否正在监听目标端口,可通过 netstat -tlnp 或 ss -tlnp 命令查看,若进程监听正常,则检查云平台的安全组规则,确保入站规则允许来自客户端IP段的流量访问该端口,注意,安全组规则通常基于状态检测,若出站规则限制过严,也可能影响响应包的返回,建议在测试阶段暂时开放所有端口,确认连通性后再逐步收紧策略。
如何避免应用迁移时的服务中断
为避免迁移导致的服务中断,应采用蓝绿部署或金丝雀发布策略,首先在新分组中部署应用实例,但不立即切换流量,通过健康检查确认新实例运行正常后,逐步将流量从旧分组迁移到新分组,在此过程中,保持旧分组实例运行,以便在新实例出现问题时能快速回滚,使用会话保持(Session Affinity)功能,确保用户请求在迁移期间被路由到同一实例,避免会话丢失。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/357019.html