AI接入盘古大模型的核心在于通过API接口调用其垂直领域能力,实现企业私有数据与公有云算力的安全融合,从而降低定制化开发成本并提升业务响应速度。
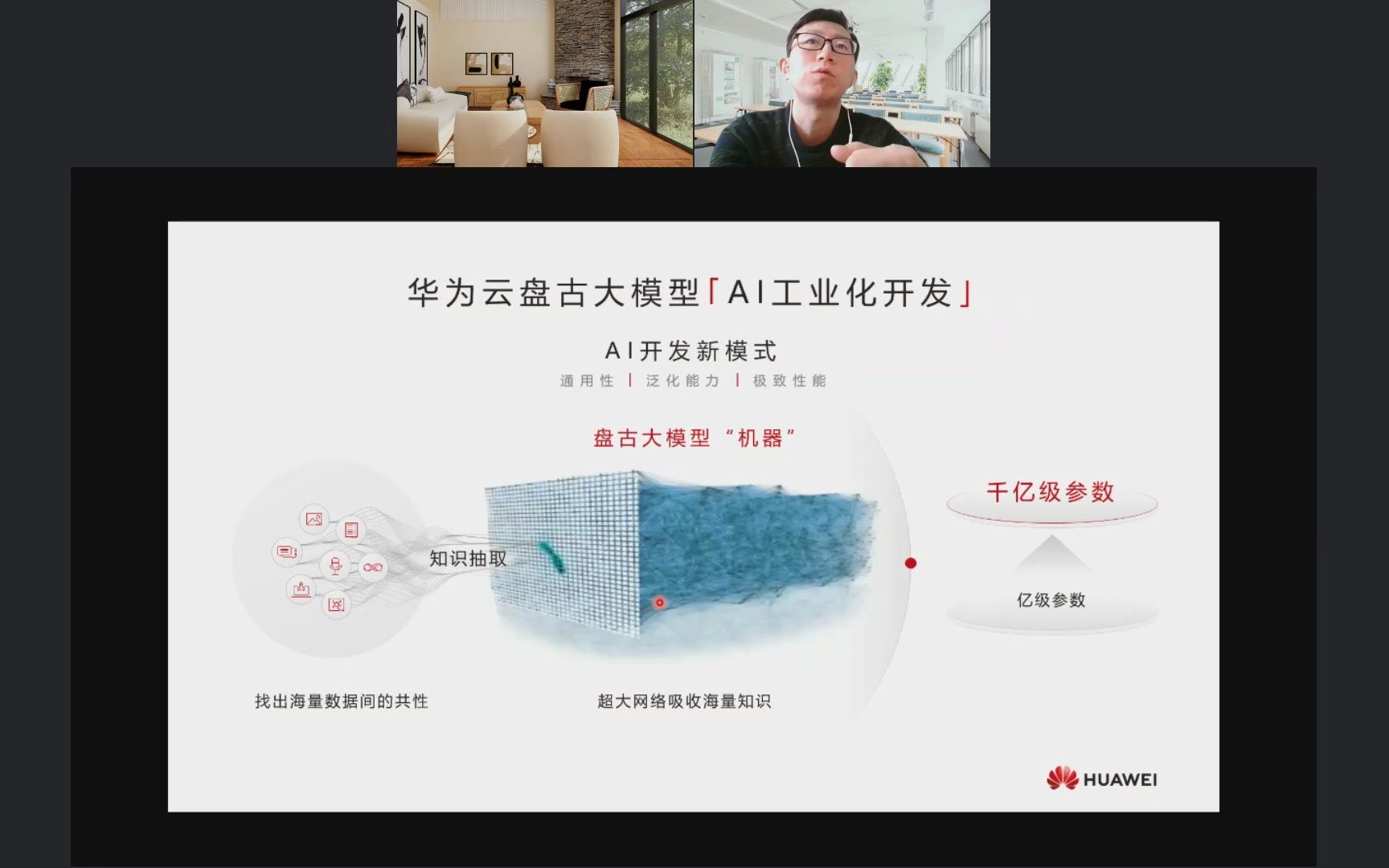
在2026年的技术语境下,单纯谈论“大模型”已经显得过于宽泛,企业真正关心的不再是模型有多聪明,而是它如何嵌入现有的工作流,华为云盘古大模型之所以在政企市场占据重要席位,是因为它解决了通用大模型在行业深度理解上的短板,接入过程并非简单的代码复制,而是一场涉及数据治理、权限管理和场景适配的系统工程。
为什么选择盘古大模型进行企业级接入
许多技术负责人在选型时,往往会在通用开源模型和头部商业闭源模型之间犹豫,业内专家指出,盘古大模型的优势在于其“行业大模型”的定位,它不是从零开始训练,而是在通用基座之上,注入了气象、矿山、制药、金融等特定领域的海量专业数据。
通用模型与行业大模型的差异对比
通用大模型擅长处理常识性问题和创意生成,但在处理专业术语、复杂逻辑推理时,容易出现“幻觉”,相比之下,盘古大模型针对特定场景进行了微调。
- 数据精准度:行业大模型使用了经过清洗的行业专有数据,理解能力远超通用模型。
- 响应速度:针对特定任务优化了推理路径,减少了无效计算。
- 安全性:数据不出域,符合国企和大型民企的合规要求。
核心应用场景解析
接入盘古大模型并非为了展示技术先进性,而是为了解决具体痛点,以下是几个高频落地场景:
智能客服与知识问答
传统客服依赖关键词匹配,准确率低,接入后,系统能理解用户意图,直接从企业知识库中提取答案,在电信行业,用户询问“宽带故障”,系统能结合用户的历史账单和网络状态,给出具体排查步骤,而非泛泛而谈。

代码辅助与开发提效
对于软件开发团队,盘古代码大模型能理解企业内部的代码规范,它不仅能生成代码片段,还能解释复杂逻辑,甚至自动修复常见Bug,这显著降低了初级工程师的学习曲线。
文档自动化处理
在金融和法律领域,合同审查、研报摘要生成是高频需求,盘古模型能一次性阅读数百页文档,提取关键风险点,生成结构化摘要,将原本需要数小时的工作压缩至分钟级。
如何低成本实现AI接入盘古大模型
对于大多数中小企业而言,自建算力集群是不现实的,通过API接口接入,是性价比最高的路径,这一过程涉及环境配置、接口调用和结果处理三个关键环节。
前期准备与账号开通
在开始编码之前,需要完成基础的环境搭建。
- 注册华为云账号:确保账号已通过实名认证,并开通ModelArts或相关AI服务权限。
- 获取AK/SK密钥:在控制台生成Access Key和Secret Key,这是身份验证的核心凭证,务必妥善保管。
- 确定计费模式:目前主流模式包括按调用次数计费和包年包月,对于初创项目,建议先选择按量付费,以控制初期成本。
技术集成步骤详解
接入过程并不复杂,主要依赖官方提供的SDK或RESTful API。
第一步:环境依赖安装
使用Python作为开发语言时,需安装华为云提供的SDK库,在命令行中输入以下命令即可完成安装:
`pip install huaweicloud-sdk-ai`
第二步:初始化客户端
编写初始化代码,配置AK/SK及区域信息,这是所有后续调用的基础。
from huaweicloud.sdk.core.auth import BasicCredentials
from huaweicloud.sdk.ai.v1.region.ai_region import AiRegion
credentials = BasicCredentials(ak, sk)
client = AiClient.new_builder()
.with_credentials(credentials)
.with_region(AiRegion.value_of("cn-north-4"))
.build()
第三步:构建请求参数

根据具体模型(如盘古NLP、盘古CV等),构造输入文本或图像数据,注意,输入数据需符合模型规定的格式要求,如JSON结构。
第四步:调用接口并处理响应
发送请求后,解析返回的JSON数据,重点关注`output`字段中的文本内容或置信度评分,若遇到错误码,需查阅官方文档进行排查。
2026年接入成本与效果评估
成本是决策的关键因素,随着模型技术的成熟,调用价格逐年下降,但不同场景下的投入产出比差异巨大。
价格体系透明化
华为云对盘古大模型的API调用采取了阶梯定价策略。
| 模型类型 | 计费单位 | 适用场景 | 预估成本趋势 |
|---|---|---|---|
| 文本生成 | 每千Token | 客服、翻译 | 持续下降,极具性价比 |
| 图像识别 | 每千张 | 质检、安防 | 相对稳定,受算力影响 |
| 代码生成 | 每千行 | 辅助编程 | 略高于文本,但节省人力 |
注:具体价格随市场活动波动,建议以华为云官网实时报价为准。
ROI(投资回报率)评估维度
企业在评估接入效果时,不应仅看技术指标,更应关注业务价值。
- 人力替代率:通过自动化处理重复性文档工作,预计可替代30%-50%的基础人工工时。
- 响应时效提升:从小时级缩短至秒级,显著提升客户满意度。
-

错误率降低
:在数据录入和初步筛选环节,AI的准确率通常高于人工,减少后续纠错成本。

常见误区与避坑指南
在实际落地过程中,许多团队容易陷入一些认知误区,导致项目延期或效果不佳。
认为接入即完美
大模型并非万能钥匙,它需要高质量的“投喂”数据,如果企业内部数据杂乱无章、标签缺失,模型的效果将大打折扣,数据治理是接入前的必要步骤。
忽视安全合规
在金融、医疗等敏感行业,数据隐私是红线,务必启用数据脱敏功能,确保敏感信息在传输和存储过程中不被泄露,需定期对模型输出进行人工抽检,防止生成违规内容。
过度依赖单一模型
不同模型擅长领域不同,建议采用“混合架构”,将盘古大模型与开源小模型结合,简单任务用小模型处理以降低成本,复杂任务调用盘古大模型以保证质量。
AI接入盘古大模型Q&A
AI接入盘古大模型需要多少技术门槛
对于具备基础Python开发能力的团队而言,技术门槛较低,华为云提供了完善的SDK和文档,大部分工作集中在接口调试和业务逻辑适配上,若企业缺乏AI人才,可考虑采用低代码平台或寻求第三方服务商协助,将开发周期缩短至1-2周。
AI接入盘古大模型支持哪些编程语言
官方SDK主要支持Python、Java、Go和C++,其中Python生态最完善,文档最全,适合快速原型开发,Java和Go则更适合大型微服务架构,若使用其他语言,可通过直接调用RESTful API实现,兼容性良好。
AI接入盘古大模型的数据安全性如何保障
华为云承诺数据不用于模型训练,除非用户明确授权,传输过程采用HTTPS加密,存储过程采用AES-256加密,企业可部署私有化实例,实现数据完全本地化存储,满足最高级别的安全合规要求,据工信部相关数据安全规范显示,此类混合云架构是目前政企客户的主流选择。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/375811.html