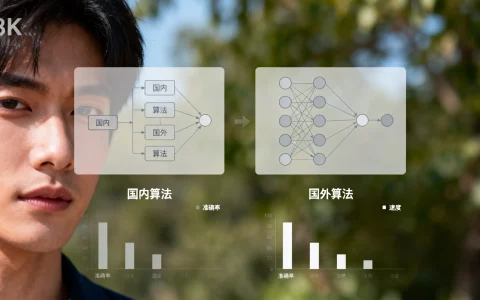
图像识别技术作为计算机视觉的核心领域,正处于从实验室研究向大规模工业化应用转型的关键时期,当前,全球图像识别技术呈现出明显的分层竞争态势:国外在基础算法创新、通用大模型构建及底层理论研究上依然保持领先优势,而中国则凭借海量数据资源、丰富的应用场景以及强大的工程落地能力,在垂直行业的商业化应用和场景化解决方案方面已实现反超。 图像识别的竞争将不再局限于单一的识别准确率,而是向多模态融合、边缘计算效率、数据隐私安全以及低成本商业化解决方案等深水区迈进。

国外技术现状:基础创新与通用大模型的引领者
以美国为代表的西方国家在图像识别领域的底层逻辑和架构设计上占据制高点,Google、Meta(Facebook)、OpenAI等科技巨头长期主导着前沿算法的迭代。
深度学习架构的持续演进是国外技术强项的核心体现,从早期的CNN(卷积神经网络)到如今大热的Vision Transformers(ViT),国外研究机构在模型架构的突破性上具有先发优势,Meta发布的SAM(Segment Anything Model)模型,展示了极强的通用分割能力,几乎能够分割出图像中的任何物体,这种“大一统”的模型思路极大地降低了图像识别的应用门槛。
在生成式AI与识别的结合上,国外也走在了前列,通过引入多模态学习机制,如CLIP模型,实现了文本与图像的语义对齐,使得机器不仅能“看见”图像,还能“理解”图像背后的语义关系,这种技术路径的探索,为图像识别在开放环境下的泛化能力提供了理论保障,使得模型在面对未见过的数据时,依然能保持较高的鲁棒性。
国内发展态势:场景落地与数据闭环的构建者
与国外侧重“从0到1”的原始创新不同,国内图像识别产业更擅长“从1到N”的规模化应用,中国在安防、金融、医疗、工业制造等领域的渗透率全球领先,形成了独特的“算法+场景+数据”飞轮效应。
在智慧安防与城市治理领域,国内企业利用海量视频监控数据,训练出了极高精度的行人重识别、车辆属性分析及异常行为检测模型,这种基于超大规模数据集的工程优化能力,使得国内系统在复杂光照、遮挡等恶劣环境下的表现往往优于国外同类产品。
工业视觉检测是另一大优势阵地,随着“中国制造2026”的推进,图像识别技术被广泛用于产品表面的瑕疵检测,国内厂商通过定制化开发,针对特定产品(如锂电池片、半导体晶圆、纺织品)构建专用数据集,利用小样本学习技术解决了工业场景中样本稀缺的痛点,实现了高精度的自动化质检,大幅降低了人力成本。

移动端与边缘侧的部署能力也是国内的一大亮点,得益于智能手机和物联网设备的普及,国内厂商在模型轻量化、剪枝、量化等技术上积累了丰富经验,使得复杂的图像识别算法能够运行在算力有限的边缘设备上,实现了实时的端侧智能处理。
技术瓶颈与专业解决方案
尽管发展迅猛,但国内外图像识别技术目前都面临着数据隐私保护、小样本学习能力不足以及模型可解释性差等共性挑战,针对这些痛点,行业需要采取更为专业的解决方案。
推进“云边协同”的混合计算架构
单纯依赖云端计算存在高延迟和隐私泄露风险,而全边缘计算则受限于算力,专业的解决方案应采用云边协同架构:在边缘端进行特征提取和初步推理,快速响应实时需求;在云端进行复杂的模型训练和长周期数据分析,这种架构不仅能满足工业级实时性要求,还能通过联邦学习技术,在不交换原始数据的前提下联合训练模型,有效解决数据孤岛和隐私问题。
发展自监督学习与合成数据技术
针对高质量标注数据获取成本高的问题,应大力发展自监督学习,利用海量未标注数据进行预训练,让模型自主学习图像特征,再用少量标注数据进行微调,利用生成式对抗网络(GAN)合成逼真的训练样本,针对罕见场景或长尾数据进行数据增强,从而显著提升模型在极端情况下的识别准确率。
构建可解释性AI(XAI)系统
在医疗和自动驾驶等高风险领域,仅仅给出识别结果是不够的,未来的解决方案必须包含可视化模块,能够通过热力图等方式向用户展示模型关注的图像区域及决策依据,建立人机信任机制,这是图像识别技术走向核心业务系统的必经之路。
总体而言,图像识别技术正在经历从感知智能向认知智能的跨越,国外强在基础研究的深度与广度,国内强在应用落地的速度与精度,对于企业而言,盲目追求“大模型”并不可取,构建“通用大模型+行业小模型”的分层技术体系才是最优解,利用通用大模型强大的泛化能力作为基础底座,结合行业特有的小数据进行精细化微调,才能在保证成本可控的前提下,实现识别效果的最大化。

相关问答
Q1:目前国内图像识别技术与国外最大的差距在哪里?
A: 最大的差距主要体现在底层基础算法的原创性和高端芯片的算力支撑上,国外在Transformer等新型架构的提出和基础理论创新上仍掌握话语权,且在训练超大规模模型所需的GPU算力生态上具有明显优势,国内虽然在应用层和工程层做得很好,但在底层核心算法框架(如PyTorch, TensorFlow的替代品)的生态影响力上仍有待提升。
Q2:中小企业在缺乏海量数据的情况下,如何实施图像识别项目?
A: 中小企业应采用“迁移学习”和“小样本学习”策略,不要试图从零开始训练模型,而是下载开源的预训练模型(如ImageNet预训练模型),利用企业手头拥有的少量特定数据进行微调,可以采用数据增强技术,对现有样本进行旋转、裁剪、加噪等操作扩充数据集,这样在低成本下也能获得满足业务需求的识别效果。
互动环节
您所在的行业目前是否已经引入了图像识别技术?在实际部署过程中,您是更看重模型的识别精度,还是更关注推理速度和硬件成本?欢迎在评论区分享您的实战经验与看法。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/38067.html