大模型Docker容器显存配置的核心在于通过NVIDIA Container Toolkit绑定GPU设备,并利用CUDA_VISIBLE_DEVICES变量隔离显存,同时结合vLLM或TensorRT-LLM等推理引擎的显存碎片化优化策略,实现显存的高效利用与稳定运行。
在本地部署或云端调试大语言模型时,很多开发者常遇到容器启动后显存占用异常、OOM(显存溢出)或者多模型争抢资源导致服务崩溃的问题,这通常不是因为硬件不够强,而是容器层面的显存分配逻辑没有理顺,显存不像CPU内存那样可以随意交换到磁盘,它是GPU的“黄金资源”,配置不当直接导致推理速度断崖式下跌。
基础环境搭建与驱动匹配
配置显存的第一步是确保宿主机与容器之间的通信通道畅通,如果驱动版本不匹配,容器内的CUDA库将无法调用宿主机的GPU,导致进程直接退出或回退到CPU运算,速度极慢。
验证NVIDIA Container Toolkit安装状态
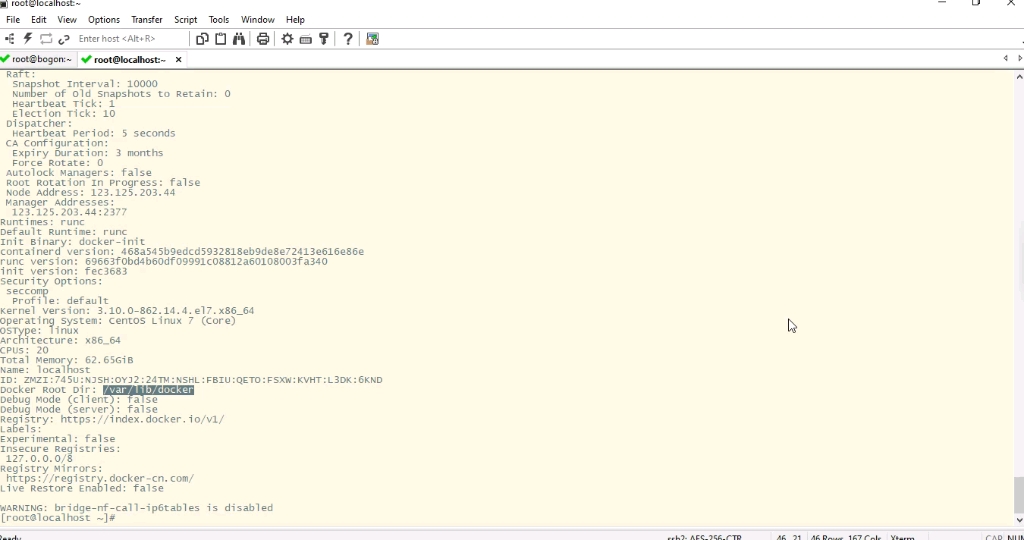
业内专家指出,正确的容器运行时配置是显存管理的前提,你需要在宿主机上安装nvidia-container-toolkit,并重启Docker服务,安装完成后,可以通过以下命令验证环境是否正常:
docker run --rm --gpus all nvidia/cuda:12.2.0-base-ubuntu22.04 nvidia-smi
如果输出中显示了GPU型号、驱动版本以及当前显存使用情况,说明底层链路已打通,若提示“no devices were found”,则需检查Docker daemon配置中是否启用了nvidia运行时。
选择匹配的CUDA镜像版本
不同的大模型框架对CUDA版本有严格要求,PyTorch 2.0+通常要求CUDA 11.8或12.1以上,盲目拉取最新镜像可能导致依赖冲突,建议根据模型框架的官方文档,选择对应的base或devel镜像,对于追求极致性能的推理场景,使用包含完整CUDA Toolkit的镜像便于后续编译优化算子。

容器级显存隔离与变量控制
这是解决显存混乱最关键的环节,默认情况下,Docker容器可能看到宿主机所有GPU,或者完全无法访问GPU,通过环境变量和启动参数,可以精确控制容器可见的GPU资源。
使用CUDA_VISIBLE_DEVICES进行显存隔离
当你有多张显卡,但只想让某个容器使用特定显卡时,CUDA_VISIBLE_DEVICES是最佳工具,限制容器仅使用第0号和第1号GPU:
docker run -it --gpus '"device=0,1"' -e CUDA_VISIBLE_DEVICES=0,1 your_model_image
在容器内部,0对应宿主机的0,1对应宿主机的1,这种映射关系确保了不同容器之间的显存互不干扰,对于需要精细控制显存占用的场景,建议每个关键服务绑定独立GPU,避免显存碎片化导致的分配失败。
限制显存增长策略
PyTorch等框架默认会按需申请所有可用显存,这会导致其他进程无显存可用,在容器内设置PYTORCH_CUDA_ALLOC_CONF环境变量可以有效缓解这一问题。
export PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True
开启expandable_segments后,PyTorch将使用更高效的显存分配器,减少碎片,提升显存利用率,对于显存紧张的场景,还可以结合max_split_size_mb参数限制单次分配的最大块大小,防止大模型加载时瞬间耗尽显存。
推理引擎的显存优化实战
通用框架如原生PyTorch在推理大模型时显存效率较低,主要因为KV Cache(键值缓存)管理粗放,引入专用推理引擎是提升显存利用率的主流方案。
vLLM的PagedAttention机制优势
vLLM通过PagedAttention技术,将KV Cache像操作系统内存页一样进行分页管理,相比传统方法,它能显著减少显存浪费,支持更高的并发批次,在同等显存下,vLLM的吞吐量通常比Hugging Face Transformers高出数倍。

配置vLLM容器时,无需手动计算显存大小,引擎会自动根据模型权重和上下文长度动态分配,但需注意,--max-model-len参数决定了最大上下文长度,设置过大可能导致OOM,过小则限制服务能力,建议根据显存容量,通过实验确定最佳值。
TensorRT-LLM的量化部署策略
对于对延迟极度敏感的场景,TensorRT-LLM是更优选择,它支持INT8/FP8量化,能将模型权重体积压缩至原来的1/2甚至1/4,从而在有限显存中部署更大参数的模型。
# 示例:构建TensorRT-LLM引擎时的量化参数 --dtype float16 --fp8
量化虽能节省显存,但会轻微影响生成质量,在医疗、法律等专业领域,需权衡精度损失与显存收益,FP8量化在保持较高精度的同时,能带来显著的显存节省,是近年来的行业共识。
常见故障排查与性能调优
即使配置正确,运行时仍可能出现显存泄漏或性能瓶颈,以下是针对典型问题的排查路径。
识别显存泄漏
如果容器运行一段时间后显存占用持续上升且不释放,可能是代码中存在显存泄漏,使用nvidia-smi dmon命令监控GPU内存变化曲线,若曲线呈阶梯状上升,需检查循环中是否未正确释放中间变量,在Python代码中,确保使用torch.cuda.empty_cache()清理缓存,并避免在循环中创建大型张量。
调整Batch Size与序列长度
显存不足时,最直接的方法是减小Batch Size或最大序列长度,但降低Batch Size会影响吞吐量,建议采用动态批处理策略,如vLLM的--max-num-batched-tokens参数,允许引擎在显存允许范围内动态调整批次大小,平衡延迟与吞吐。
多容器资源竞争处理

当多个模型容器共享GPU时,需设置显存上限,Docker本身不支持直接限制GPU显存使用量,但可通过NVIDIA驱动层的nvidia-smi命令或第三方工具如gpu-mem-limit进行软限制,更稳健的做法是通过Kubernetes的limits字段指定GPU数量,并结合应用层的显存隔离策略,确保关键服务不受干扰。
大模型Docker容器显存配置常见问题解答
大模型Docker容器显存配置中如何避免OOM错误?
避免OOM的核心在于预分配控制和碎片优化,使用CUDA_VISIBLE_DEVICES隔离GPU,确保容器只访问指定显存,启用expandable_segments减少PyTorch显存碎片,根据模型参数量和上下文长度,预估显存需求,预留20%左右的缓冲空间,若使用vLLM,通过调整--max-num-batched-tokens动态控制负载,可有效防止瞬时显存溢出。
大模型Docker容器显存配置与K8s资源限制有何区别?
Docker层面的配置侧重于单容器内的显存可见性与应用层优化,如环境变量和框架参数,而Kubernetes资源限制(如limits: nvidia.com/gpu: 1)侧重于集群层面的调度与隔离,防止单个Pod耗尽节点所有GPU,两者需配合使用:K8s确保物理资源分配,Docker配置确保应用高效利用分配到的资源,仅靠K8s限制数量,无法解决容器内显存碎片化问题。
大模型Docker容器显存配置中量化对性能的影响有多大?
量化能显著降低显存占用,INT8量化通常可减少约50%的显存需求,FP8可减少约75%,对于70B参数模型,量化后可在单张A100 80G上运行,而全精度版本可能需要多卡或H100,性能方面,INT8量化对生成速度提升明显,但对复杂逻辑推理的准确率可能有轻微下降,通常在可接受范围内,FP8则在精度和显存节省间取得更好平衡,适合对延迟敏感的生产环境。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/397950.html