大模型的自我改进并非依赖人工逐行修改代码,而是通过“生成-评估-筛选”的闭环机制,利用自身生成的数据反向优化自身参数,从而实现无需人类直接标注的自主进化。
这种机制正在重塑人工智能的训练范式,过去,我们依赖海量人工标注数据来教模型说话;模型开始自己出题、自己答题、自己批改,并在错误中迭代,这不仅是技术的升级,更是算力与算法效率的质变。
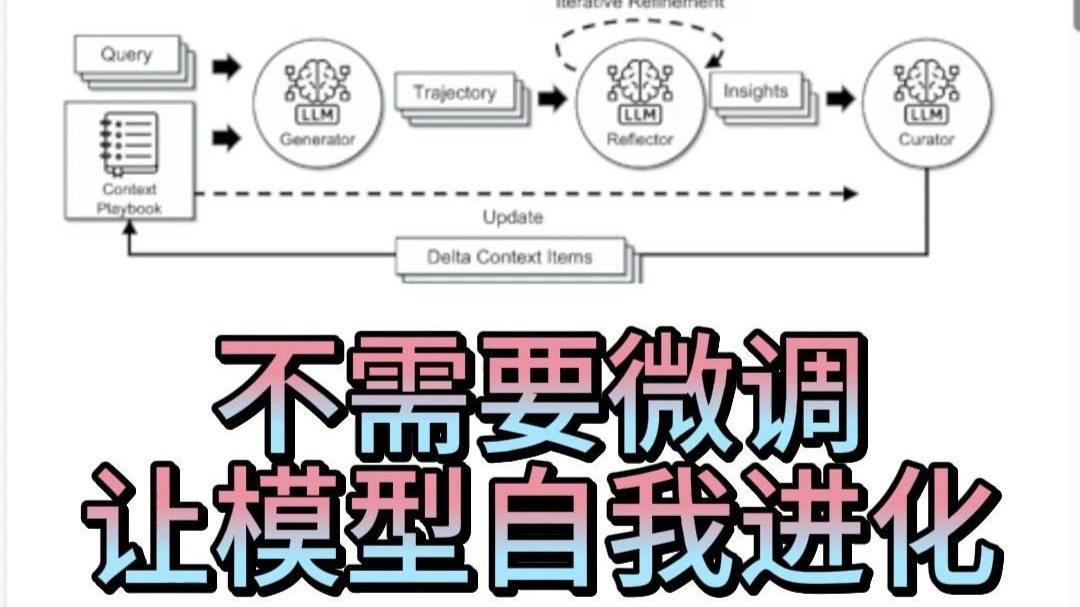
大模型自我改进的核心逻辑与运作机制
从被动学习到主动反思
传统的监督学习(SFT)就像老师拿着标准答案教学生做题,而自我改进(Self-Improvement)则更像是一个学霸在刷题后,自己分析错题,总结规律,然后重新做一遍,直到做对为止,这个过程主要包含三个关键步骤:
- 数据生成:模型利用已有的知识库,生成新的问题或代码片段。
- 自我评估:模型扮演“裁判”角色,对生成的答案进行打分或排序。
- 偏好优化:根据评估结果,筛选出高质量数据,用于下一轮的模型训练。
业内专家指出,这种机制的核心在于“数据飞轮”,随着模型能力的提升,它生成的数据质量越高,进而训练出的新模型更强,形成正向循环。
关键技术路径:RLHF与DPO的演进
实现自我改进主要有两条技术路线,它们在应用场景和成本上存在显著差异。
| 特性维度 | 传统RLHF (基于人类反馈的强化学习) | 直接偏好优化 (DPO) |
|---|---|---|
| 依赖数据 | 需要大量人工标注的偏好数据 | 仅需静态的偏好对(好答案vs坏答案) |
| 训练复杂度 | 高,需训练奖励模型和价值模型 | 低,直接优化策略模型 |
| 稳定性 |
容易崩溃,超参数敏感 | 相对稳定,收敛更快 |
| 适用场景 | 通用大模型基础能力构建 | 垂直领域微调、模型自我迭代 |

对于大多数企业而言,大模型自我改进技术哪家强 并不是一个非此即彼的问题,而是取决于业务场景,通用大模型往往需要复杂的RLHF流程来对齐价值观,而垂直领域的模型则更倾向于使用DPO进行快速迭代。
自我改进在垂直场景中的实战应用
代码生成的自动化闭环
在编程领域,自我改进的效果最为显著,开发者不再需要手动调试每一行代码,而是让模型生成测试用例,运行测试,根据报错信息自我修正。
具体操作路径如下:
- 初始生成:输入需求描述,模型生成初始代码。
- 执行测试:将代码投入沙箱环境运行,收集错误日志。
- 反馈修正:将错误日志作为提示词的一部分,再次输入模型。
- 迭代优化:模型根据反馈调整代码,直到测试通过。
据统计,在复杂的算法题解决场景中,经过多轮自我修正的模型,其代码通过率比单次生成高出较大比例,这种“思考-执行-反思”的模式,让AI从单纯的代码补全工具,进化为具备调试能力的编程助手。
数学推理与逻辑链优化
数学推理是大模型的短板,但也是自我改进最能发挥作用的领域,通过引入“思维链”(Chain-of-Thought)技术,模型在给出最终答案前,会先生成一系列推理步骤。
在大模型自我改进技术原理的研究中,一个关键发现是:模型在生成推理步骤时,如果步骤出现逻辑跳跃,它可以通过自我验证发现不一致,在解答应用题时,模型可能会先假设一个解,然后反向验证是否符合题意,如果不符合,它会回溯并调整推理路径。
这种机制在大模型自我改进应用场景中,特别适用于金融风控、法律条文解析等需要极高逻辑严密性的领域,通过让模型自己“找茬”,可以显著降低幻觉率,提升输出的可信度。

实施自我改进面临的挑战与对策
模型坍缩风险
自我改进并非没有代价,如果模型过度依赖自身生成的数据,可能会出现“模型坍缩”现象,就是模型开始重复自己的错误,或者陷入局部最优解,导致多样性丧失。
为了解决这个问题,业界普遍采用“混合数据策略”:
- 保留人工数据:在训练集中保留一定比例的高质量人工标注数据,作为“锚点”。
- 引入外部验证:使用独立的、更强大的模型或规则引擎对自我生成的数据进行二次筛选。
- 多样性惩罚:在损失函数中加入多样性约束,鼓励模型探索不同的解题路径。
算力成本与效率平衡
自我改进需要大量的推理和训练资源,对于中小企业来说,大模型自我改进价格 往往是一个敏感话题,完全从头训练一个具备自我改进能力的大模型,成本高昂且周期漫长。
更务实的做法是:
- 利用开源基座:选择Llama 3、Qwen等开源基座进行微调,而非从头预训练。
- 轻量化评估:使用小型模型作为“裁判”,降低评估阶段的算力消耗。
- 增量更新:仅在特定任务上进行小规模的自我改进迭代,而非全量参数更新。
据工信部相关数据显示,采用混合策略的企业,其模型优化成本可降低相当一部分,同时保持核心性能的稳定。
未来趋势:从自我改进到自主智能体
自主智能体的崛起
自我改进是大模型迈向自主智能体(Agent)的关键一步,未来的AI不再只是被动回答问题,而是能够主动规划任务、执行操作、并根据结果自我调整策略。
这种转变意味着:
- 长期记忆:模型能够记住过去的改进经验,避免重复犯错。
- 工具调用:模型能够自主调用外部工具(如计算器、搜索引擎)来辅助自我改进。
- 多模态融合:自我改进不仅限于文本,还将扩展到图像、视频等多模态数据。

人机协作的新范式
尽管自我改进能力强大,但人类的角色并未消失,而是变得更加关键,人类将从“数据标注员”转变为“规则制定者”和“最终审核者”。
在大模型自我改进技术对比中,一个重要的区分点是“可控性”,完全自动化的自我改进可能导致不可控的风险,引入人类在关键节点的干预,是确保AI安全对齐的必要手段。
常见问题解答
大模型自我改进技术是否会导致数据泄露?
自我改进过程中,模型主要利用内部生成的数据进行训练,通常不涉及外部敏感数据的直接复用,如果训练数据中包含未脱敏的用户隐私信息,模型可能会在自我生成时无意中重现这些信息,在实施自我改进前,必须对原始数据进行严格的隐私清洗和脱敏处理,这是行业共识认为的安全底线。
小模型能否进行有效的自我改进?
小模型进行自我改进的效果通常不如大模型显著,因为自我改进依赖于模型自身的推理能力和知识广度,小模型在生成高质量数据方面存在局限,容易陷入“低水平重复”,业内专家指出,对于小模型,更推荐采用“大模型指导小模型”的蒸馏模式,而非完全依赖自我改进。
如何评估自我改进后的模型效果?
评估自我改进效果不能仅看单一指标,需建立多维度的评估体系,主要包括:
- 准确性提升:在标准测试集上的得分变化。
- 多样性保持:生成答案的丰富程度,避免同质化。
- 鲁棒性测试:在对抗性输入下的表现稳定性。
- 人工抽检:定期由专家对生成数据进行随机抽检,确保无逻辑谬误。
通过综合这些指标,才能全面判断自我改进是否真正提升了模型价值。
大模型的自我改进是人工智能从“工具”向“伙伴”演进的重要里程碑,它通过闭环反馈机制,实现了能力的指数级增长,对于企业和开发者而言,理解并善用这一技术,将在未来的AI竞争中占据先机,核心在于平衡自动化与可控性,让AI在自我进化的同时,始终服务于人类的真实需求。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/403963.html