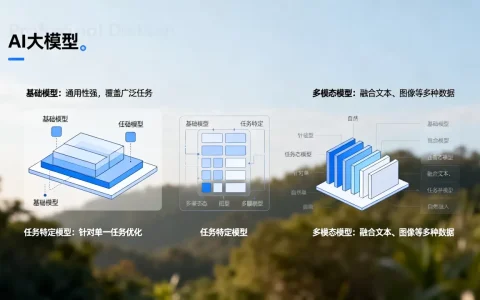
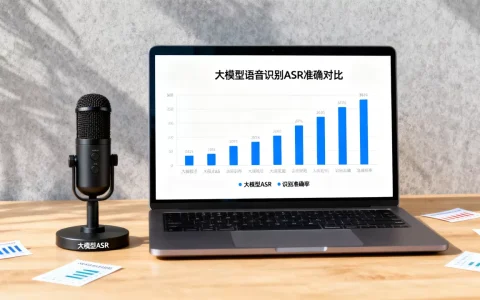
大模型音频生成技术已实现从“合成语音”到“高保真音乐与音效”的跨越,其核心在于利用扩散模型和自回归架构,通过文本描述或简短旋律即可在秒级内生成具备情感、空间感且版权清晰的原创音频内容。
过去我们提到AI配音,脑海中浮现的往往是机械、缺乏起伏的朗读声,这一技术已经发生了质的飞跃,大模型不再仅仅是简单的文字转语音工具,而是成为了懂音乐、懂音效、懂情绪的“全能音频创作者”,无论是独立游戏开发者需要独特的环境音效,还是短视频博主寻找免版权的背景音乐,亦或是在线教育机构制作生动的教学课件,大模型音频生成都提供了极具性价比的解决方案。

大模型音频生成的技术底层与核心优势
理解这项技术,首先要明白它与传统音频处理的区别,传统方式需要录音棚、专业设备和后期剪辑,而大模型则是通过海量数据训练,学习声音的物理属性和艺术规律。
从TTS到全模态生成的进化
早期的文本转语音(TTS)技术主要解决“听得清”的问题,重点在于音素的准确性和语法的流畅度,但现在的音频生成大模型,如Suno、Udio以及国内多家大厂推出的相关模型,已经进入了“全模态生成”阶段。
- 语义理解深度提升:模型不仅能识别文字内容,还能理解文字背后的情感色彩,同样是“你好”,模型可以生成温柔、严肃或欢快的不同语调。
- 多乐器与复杂结构:在音乐生成领域,模型能够处理长达数分钟的结构,包含前奏、主歌、副歌、间奏和尾奏,并自动分配钢琴、鼓点、贝斯等多种乐器轨道。
- 非语音音频的突破:除了人声和音乐,模型还能生成风声、雨声、脚步声等环境音效,这对于影视后期和游戏开发至关重要。
效率与成本的颠覆性改变
业内专家指出,大模型音频生成最直观的优势在于效率,传统制作一首3

分钟的原创背景音乐,可能需要作曲家数天时间,加上录音、混音,成本高达数千甚至上万元,而使用大模型,只需输入提示词,几分钟内即可生成多个版本供选择,成本几乎可以忽略不计,这种效率的提升,使得“音频定制”从高端服务变成了大众消费品。
主流应用场景与实操指南
大模型音频生成并非空中楼阁,它已经深入到了具体的业务场景中,以下结合不同用户群体的需求,梳理出最实用的应用路径。
创作者的流量加速器
对于自媒体人而言,音频是提升完播率的关键因素,很多视频因为背景音乐版权受限而被下架,或者因为配音单调而流失观众。
- 短视频背景音乐定制:不要使用平台自带的热门歌曲,尝试用大模型生成独一无二的BGM,输入“轻快、爵士、萨克斯、午后阳光”等关键词,生成符合视频节奏的音乐。
- 个性化配音克隆:虽然部分平台限制声音克隆,但在合规前提下,利用大模型调整音色、语速和停顿,可以让AI配音更贴近真人情感,避免“机器人感”。
游戏与影视工业的降本利器
独立游戏开发者和小型影视团队往往受限于预算,无法聘请专业的音效师,大模型音频生成填补了这一空白。
- 动态音效生成:在游戏中,玩家的动作(如走路、跳跃、攻击)需要即时反馈音效,传统方式是预录大量素材,而大模型可以根据游戏引擎的参数,实时生成不同材质、不同力度的音效,极大丰富了交互体验。
- 概念音效快速验证在影视前期筹备阶段,导演可以通过大模型快速生成场景音效demo,用于向资方展示视听效果,降低沟通成本。
教育与企业培训的生动化改造
枯燥的PPT朗读往往让人昏昏欲睡,利用大模型,可以将文字课件转化为生动的有声故事或情景剧。
- 多角色对话生成:输入剧本,让模型生成不同角色的声音进行对话,模拟真实课堂或商务谈判场景,提升学习者的沉浸感。
- 多语言无障碍传播:大模型支持多语言音频生成,且能保持原声的情感色彩,助力企业出海和本土化教育内容的快速制作。

选择服务商的关键考量因素
市场上音频生成工具众多,如何选择合适的服务?这取决于你的具体需求。
音质与保真度
这是基础门槛,优质模型生成的音频应无明显底噪、失真或机械感,对于专业用途,需关注采样率是否支持44.1kHz或48kHz以上,以及是否提供无损格式输出。
版权与商用许可
这是许多用户容易忽视的风险点,不同平台的版权政策差异巨大。
| 平台类型 | 版权归属 | 商用限制 | 适用场景 |
|---|---|---|---|
| 免费开源模型 | 用户所有 | 需自行审查训练数据合规性 | 个人学习、非商业实验 |
| 国内主流SaaS平台 | 付费用户所有 | 需购买商用授权包 | 企业宣传、商业视频 |
| 国际头部平台 | 订阅用户所有 | 高级订阅含商用权 | 全球发行内容、大型项目 |
注:具体版权政策请以各平台最新用户协议为准,建议在使用前仔细阅读条款。
控制精度与可编辑性
高阶用户往往需要更精细的控制,指定某段音乐在何时进入、何时淡出,或者调整特定乐器的音量比例,具备“分段生成”和“局部重绘”功能的模型,能提供更强的创作自由度。

未来趋势与伦理挑战
随着技术的迭代,大模型音频生成正朝着更真实、更交互的方向发展。
实时交互与低延迟
未来的音频生成将不再局限于“生成后播放”,而是实现实时互动,在虚拟数字人直播中,AI能根据观众的弹幕实时生成回应语音和背景音乐,延迟控制在毫秒级,带来前所未有的沉浸体验。
深度伪造与伦理监管
音频生成的强大能力也带来了滥用风险,如诈骗电话中的声音克隆、虚假新闻的配音等,行业共识认为,水印技术和溯源机制将成为标配,所有生成的音频文件都将嵌入不可见的水印信息,以便追踪来源,各国政府正在加快制定相关法律法规,明确AI生成内容的标识义务。
常见问题解答(FAQ)
大模型音频生成能替代真人歌手吗?
在技术层面,大模型已经能够生成极具感染力的演唱,音色、气息甚至颤音都能高度拟真,但在艺术创作的核心情感表达的独特性和文化共鸣上,真人歌手依然具有不可替代的价值,大模型更多是作为创作辅助工具,或用于满足海量、标准化的音频需求,而非完全取代顶级艺术家的创作。
生成的音频版权归谁所有?
版权归属取决于你使用的平台和服务条款,通常情况下,付费订阅的用户拥有生成内容的商用权,但需遵守平台的使用规范,免费用户或开源模型生成的内容,版权界定较为模糊,建议在使用前咨询法律专业人士,并保留好生成记录作为证据。
大模型音频生成的价格是多少?
目前市场上大多数平台采用订阅制或按量计费,基础版通常每月几十元人民币,提供有限的生成时长;专业版或企业版则根据并发数、音质等级和商用授权范围,每月费用可能在数百至数千元不等,相比传统录音棚的高昂成本,大模型音频生成的价格门槛极低,适合绝大多数个人创作者和小微企业。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/404604.html