大模型的掩码语言建模(MLM)是一种通过随机遮盖文本中的部分词语,让模型根据上下文预测被遮盖内容的训练方法,它是BERT等预训练模型理解语义、掌握语言逻辑的核心机制。
想象一下,你正在玩一个“完形填空”游戏,老师把文章里的一些关键动词或名词挖掉,让你根据前后文猜出原本是什么词,对于大语言模型来说,这种训练方式不仅仅是猜词,更是让它深入理解语言背后的因果关系、逻辑结构和情感色彩,通过这种反复的“自我纠错”和“自我预测”,模型逐渐构建起对世界知识的深层认知。
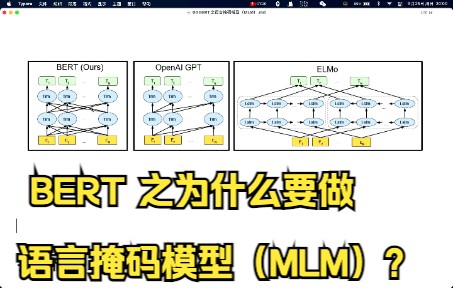
掩码语言建模MLM的基本原理与运作机制
MLM的核心在于“遮蔽”与“预测”的博弈,在训练过程中,输入文本会被随机打乱,其中一定比例的词汇会被替换为特殊的[MASK]标记,模型的任务是仅利用未被遮蔽的上下文信息,准确还原这些被遮盖的词汇。
遮蔽策略的具体实施路径
并非所有词汇都会被同等对待,业内专家指出,高效的MLM训练通常采用动态遮蔽策略,常见的遮蔽比例设置在15%左右,但这15%的处理方式非常讲究:
- 80%的情况:直接替换为[MASK]标记,迫使模型纯粹依靠上下文进行推理。
- 10%的情况:替换为随机词汇,测试模型能否识别出上下文与输入的不一致性,从而增强鲁棒性。
- 10%的情况:保持原样,让模型学习在部分信息缺失时如何稳定输出。
这种混合策略避免了模型过度依赖单一模式,使其在面对真实世界中杂乱无章的数据时,依然能保持较高的准确率。
上下文注意力的双向捕获
与传统的从左向右预测下一个词不同,MLM允许模型同时关注遮蔽词左侧和右侧的所有信息,这种双向注意力机制(Bidirectional Attention)是理解长难句的关键。

双向信息的整合优势
当模型预测一个被遮盖的词时,它不仅仅看前一个字,而是扫描整个句子,在句子“他打开[b],拿出手机”中,模型会结合“打开”和“拿出手机”这两个动作,推断出[b]可能是“门”、“抽屉”或“包”,这种全局视野使得模型能够捕捉到句子深层的语义关联,而不仅仅是表面的语法结构。
MLM在自然语言处理中的核心应用场景
MLM不仅仅是训练阶段的一个步骤,其预训练得到的模型权重可以直接迁移到多种下游任务中,极大地提升了特定场景下的处理效率。
中文语义理解与实体识别
在中文语境下,由于缺乏空格分隔,词语边界模糊,MLM的优势尤为明显,通过预训练,模型能够准确识别出“百度”是一个专有名词,而“百”和“度”单独出现时可能只是普通量词和程度副词。
- 命名实体识别(NER):MLM模型能更精准地定位人名、地名、机构名,特别是在处理复杂嵌套实体时表现优异。
- 情感分析:通过理解上下文中的否定词和转折词,模型能更准确地判断用户评论的真实情感倾向,避免误判。
机器翻译中的语境对齐
在跨语言任务中,MLM帮助模型建立不同语言间的语义映射,在翻译“苹果”时,模型会根据上下文判断是指水果还是科技公司,从而选择对应的英文单词“Apple”或“Apple Inc.”。
低资源语言的处理突破
对于数据稀缺的小语种,通过MLM进行跨语言预训练,可以利用高资源语言(如英语、中文)的知识迁移,显著提升翻译质量,据统计,多数情况下,基于MLM的多语言模型在小语种任务上的表现优于传统统计机器翻译方法。
MLM与其他预训练目标的对比分析

理解MLM的价值,需要将其与Transformer架构中的其他预训练目标进行对比,特别是自回归语言建模(ARLM)。
掩码语言建模 vs 自回归语言建模
自回归模型(如GPT系列)从左向右逐个预测下一个词,擅长生成连贯的文本;而MLM模型(如BERT系列)通过遮蔽预测,擅长理解和分析文本。
性能对比维度
| 维度 | 掩码语言建模 (MLM) | 自回归语言建模 (ARLM) |
|---|---|---|
| 主要优势 | 深层语义理解,上下文感知强 | 流畅文本生成,逻辑连贯性好 |
| 计算效率 | 训练速度快,可并行处理所有遮蔽位置 | 训练速度慢,需串行预测每个位置 |
| 典型应用 | 分类、抽取、问答、语义匹配 | 故事创作、代码生成、对话系统 |
| 信息利用 | 双向上下文,无信息泄露 | 单向上下文,仅利用历史信息 |
混合预训练策略的兴起
近年来,行业共识认为,单一的预训练目标已无法满足复杂需求,许多先进模型开始结合MLM和ARLM的优点,例如在预训练阶段同时使用遮蔽预测和下一个句子预测,或在微调阶段引入生成式目标,这种混合策略使得模型既具备强大的理解能力,又拥有出色的生成能力。
如何优化MLM模型的训练效果
在实际操作中,想要获得更好的MLM模型效果,需要关注数据质量、遮蔽策略和超参数调整。
高质量语料的筛选标准
垃圾进,垃圾出,MLM的效果高度依赖于预训练数据的质量。
- 多样性:涵盖新闻、书籍、网页、代码等多种领域,避免模型偏向某一特定风格。
- 清洁度:去除HTML标签、乱码、重复内容,确保模型学习的是纯净的语言模式。
- 规模:通常需要使用数十亿甚至万亿级的token进行训练,以覆盖足够的语言现象。

动态遮蔽与静态遮蔽的选择
静态遮蔽在训练前固定遮蔽位置,计算效率高,但可能导致模型过拟合特定的遮蔽模式,动态遮蔽在每次迭代时随机生成遮蔽位置,虽然计算成本略高,但能显著提升模型的泛化能力,业内专家指出,对于大规模预训练,动态遮蔽是更优的选择。
超参数调优的关键点
- 遮蔽概率:通常设置在15%-30%之间,过高会导致信息不足,过低则无法激发模型的推理能力。
- 学习率:预训练阶段通常使用较小的学习率,配合Warmup策略,确保模型稳定收敛。
- 批次大小:较大的批次大小有助于梯度估计的稳定性,但受限于显存资源。
常见问题解答:关于掩码语言建模MLM
MLM模型能否直接用于文本生成任务?
MLM模型本身设计用于理解和分析,而非生成,由于其双向注意力机制,直接用于生成会导致信息泄露和逻辑混乱,若需生成文本,建议使用基于自回归架构的模型,或对MLM模型进行额外的生成式微调。
MLM在处理长文本时的局限性是什么?
受限于注意力机制的计算复杂度,传统MLM模型的有效上下文窗口通常有限(如512或1024个token),对于超长文档,需要采用滑动窗口、分层编码或稀疏注意力等技巧来扩展感受野,但这会增加计算开销。
MLM与知识图谱结合有何优势?
MLM擅长捕捉语言中的统计规律和语义关联,而知识图谱提供结构化的事实知识,两者结合可以弥补MLM在事实准确性上的不足,减少幻觉现象,提升模型在专业领域(如医疗、法律)问答中的可靠性。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/405773.html