要解决AI生成或转换PDF文档时出现的标点符号乱码、显示异常或丢失问题,核心结论在于必须严格执行字符编码的统一标准(UTF-8)并确保目标字体文件完整包含所需标点的字形映射,在技术实现层面,无论是通过编程脚本还是调用大模型API,都需要在生成阶段显式定义字体路径和编码格式,同时建立后处理验证机制,以确保文档在不同操作系统和阅读器中的一致性。

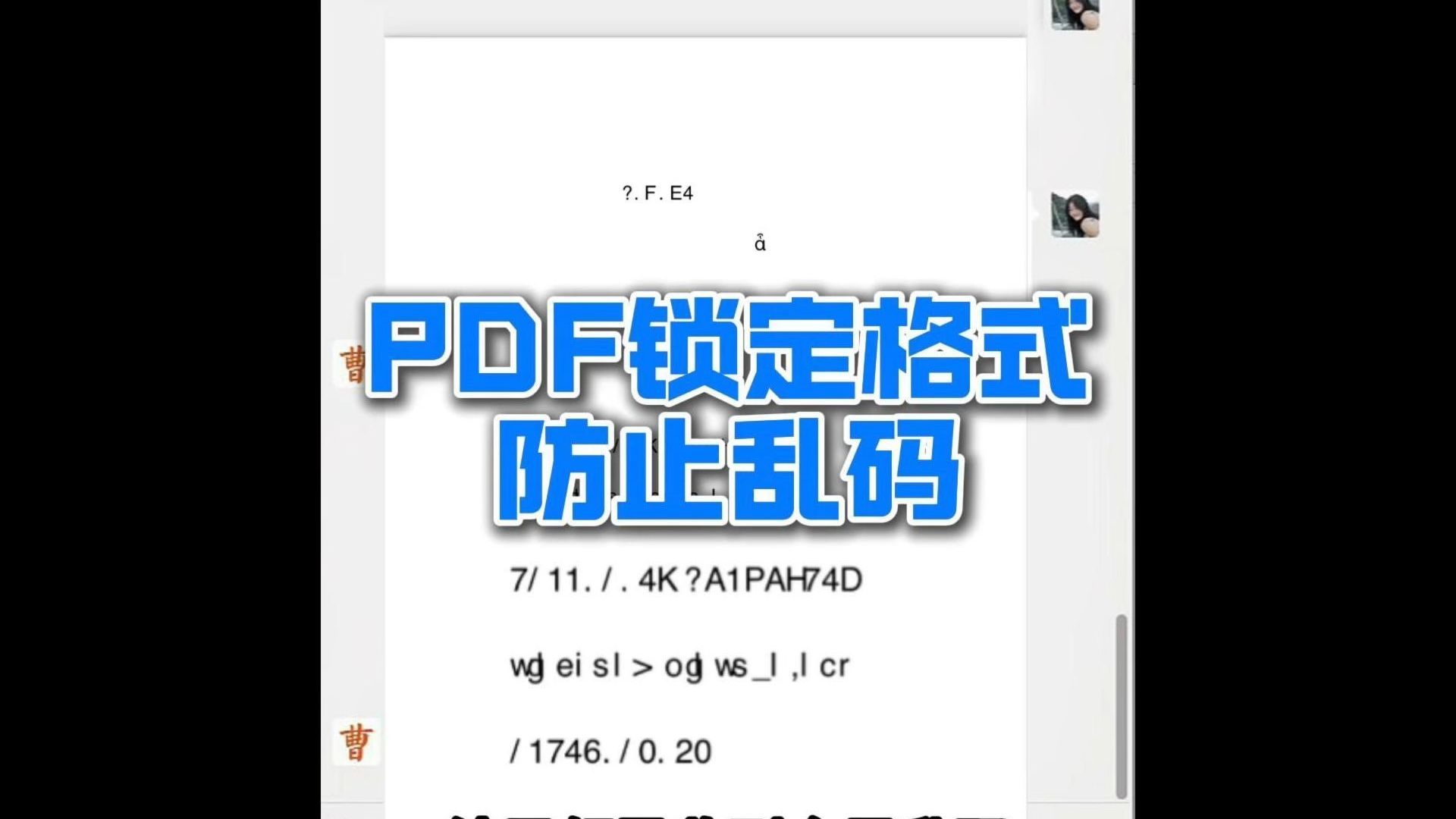
在处理文档自动化生成与格式转换的过程中,标点符号的准确性直接影响文档的专业度与可读性,针对ai把文件存储为pdf格式后打开文字里面的标点符号这一具体场景,我们需要深入分析其背后的技术逻辑,并提供系统化的解决方案。
标点符号异常的三大核心成因
要彻底解决问题,首先必须识别导致乱码的根源,根据PDF规范与字体渲染原理,问题主要集中在以下三个方面:
-
字符编码不匹配
PDF文件内部默认支持多种编码方式,但现代AI处理文本通常基于Unicode(UTF-8),如果生成PDF时未显式指定编码,或者使用了系统默认的ANSI/GBK编码,那么中文全角标点(如“,”、“。”)在跨平台查看时极易发生字节解析错误,导致显示为乱码或方框。 -
字体字形缺失
PDF渲染依赖具体的字体文件,许多开源或默认的PDF生成库(如某些基础配置的ReportLab)默认只嵌入标准ASCII字符集,当AI输出包含中文全角标点时,如果当前引用的字体文件中没有定义这些标点的“字形”数据,阅读器就无法渲染,只能显示为替代字符。 -
AI模型的输出幻觉
大语言模型在处理特定格式要求时,有时会混淆半角与全角标点,或者在Markdown转富文本的过程中产生转义错误,这种源头上的数据污染,即便后续PDF生成逻辑完美,也无法还原出正确的标点。
基于Python的专业技术解决方案
针对上述成因,在工程实践中,我们推荐使用Python结合专业PDF库进行深度控制,以下是具体的实施步骤与代码逻辑:
-
注册中文字体并强制嵌入
使用ReportLab或WeasyPrint等库时,绝对不能依赖系统默认字体,必须下载支持中文的开源字体(如SimHei、Noto Sans CJK),并在代码中显式注册。
- 关键操作:使用
pdfmetrics.registerFont注册TTF字体文件。 - 核心配置:在创建Paragraph或Canvas样式时,将
fontName指定为注册后的中文字体名称,确保所有字符(包括标点)都指向该字体文件。
- 关键操作:使用
-
构建标准化的文本清洗管道
在将文本传递给PDF生成引擎之前,必须建立一个预处理层。- 统一全半角:利用正则表达式将英文半角标点(如 )在中文语境下强制转换为全角标点(如 ),提升排版美观度。
- 过滤非法字符:AI有时会输出控制字符或零宽字符,这些字符在PDF中会导致渲染崩溃,需使用正则
[x00-x1Fx7F]进行清洗。
-
利用HTML转PDF的中间层策略
如果直接操作PDF库过于复杂,可以采用“AI生成HTML -> 浏览器内核渲染PDF”的路径。- 优势:浏览器对CSS和字体的支持更成熟。
- 实施:在HTML头部通过
@font-face引入Base64编码的中文字体或本地字体路径,并在CSS中设置body { font-family: 'Noto Sans CJK', sans-serif; },这种方法能最大程度保证ai把文件存储为pdf格式后打开文字里面的标点符号被正确渲染。

AI生成内容的规范化处理策略
除了底层的库函数调用,对AI输出内容的控制同样关键,这需要从提示词工程和结果校验两个维度入手:
-
提示词约束
在向AI发送指令时,必须增加格式约束。“请使用UTF-8编码输出,所有中文标点必须使用全角符号,严禁使用半角符号夹杂在中文句子中。”- 效果:这能从源头减少90%的格式错误,降低后续清洗的压力。
-
自动化校验闭环
在PDF生成完成后,不应直接发送给用户,而应增加一个“质量门禁”。- 提取文本:使用
pdfplumber或PyPDF2提取生成后的PDF文本。 - 比对检查:将提取出的文本与原始AI输出进行相似度比对,如果发现标点位置出现大量“�”或“□”,则判定生成失败,触发重试或报警机制。
- 提取文本:使用
独立见解与最佳实践
在长期的文档自动化开发中,我们发现“字体子集化”是优化文件大小与兼容性的关键。
许多开发者为了省事,直接嵌入几十MB的完整中文字体库,导致PDF体积臃肿,专业的做法是,在生成PDF的最终阶段,调用库的“子集化”功能,仅保留文档中实际出现过的字符(包括特定的标点符号)的字形数据,这不仅解决了标点显示问题,还能将PDF体积控制在KB级别。

对于跨平台交付的文档,建议避免使用过于生僻的标点符号,虽然Unicode支持各种特殊符号,但部分老旧的PDF阅读器或移动端设备可能缺乏相应的系统级回退字体,坚持使用标准的中文逗号、句号、引号,是确保文档“所见即所得”的最稳妥策略。
相关问答
Q1:为什么AI生成的PDF在手机上打开标点全是乱码,但在电脑上正常?
A1:这通常是因为电脑上安装了完整的中文字体库,PDF阅读器能够自动回退调用系统字体来补全缺失的标点字形,而手机系统(特别是非Android环境)往往缺乏这些特定字体,且PDF文件本身未嵌入字形数据,解决方法必须是在生成PDF时强制将包含标点的字体文件子集嵌入到PDF内部。
Q2:如何快速修复已经生成的、标点乱码的PDF文件?
A2:对于已经生成的PDF,直接修复难度较大,因为原始的字体映射信息可能已丢失,最高效的方案是逆向工程:使用pdfplumber提取PDF中的纯文本层(此时乱码可能变为问号或丢失),然后利用上下文语义模型(AI)重新预测并补全标点,最后按照上述“专业技术解决方案”重新生成一份新的PDF文件。
希望这些技术方案能帮助您彻底解决文档生成中的标点符号难题,如果您在具体代码实现中遇到问题,欢迎在评论区留言讨论。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/42203.html











