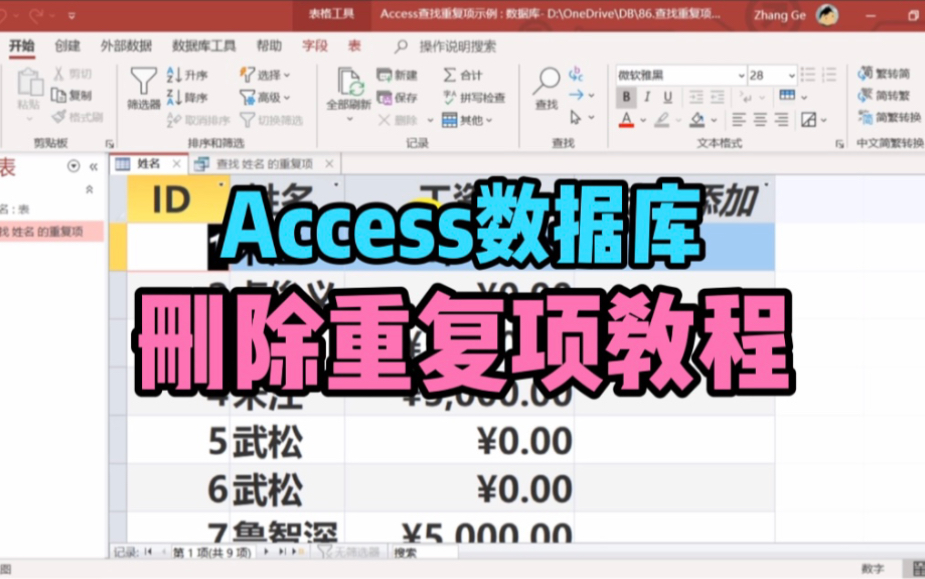
具体代码示例
假设我们要从“客户表”中找出“手机号”重复的记录,SQL代码如下:
SELECT 客户ID, 姓名, 手机号, COUNT() AS 重复次数
FROM 客户表
GROUP BY 客户ID, 姓名, 手机号
HAVING COUNT() > 1;代码解读:
- SELECT:指定要显示的字段。
- GROUP BY:按手机号分组,相同手机号的记录归为一类。
- HAVING COUNT() > 1:这是筛选条件,只保留那些出现次数大于1的分组,即重复记录。
如果需要进一步删除重复项,可以先将上述查询保存为“查询A”,然后基于“查询A”创建删除查询,但务必先备份数据,以防误删。
高级筛选与排序(临时查看用)
如果你只是偶尔需要检查数据,不想创建永久查询对象,可以使用高级筛选。
操作路径
- 打开数据表,点击“开始”选项卡下的“高级”按钮。
- 选择“高级筛选/排序”。
- 在“排序”行中,选择你要检查重复的字段(如“订单号”),并选择“升序”或“降序”。
- 在“筛选”行中,虽然Access没有直接的“重复”筛选按钮,但你可以结合“分组依据”功能,或者手动观察相邻行的数据变化。

这种方法适合小数据量的快速预览,但对于成千上万条记录,效率较低,容易遗漏。
VBA宏自动化(高阶定制)
对于需要定期自动清理重复数据的场景,VBA(Visual Basic for Applications)提供了强大的自动化能力。
适用场景
当重复数据的判断逻辑非常复杂,或者需要跨表比对时,VBA是最佳工具,比较“表A”和“表B”中是否存在相同ID的记录。
简要思路
编写一个VBA过程,使用DAO或ADO对象模型打开记录集,遍历记录并比对关键字段,将重复项标记或删除,虽然学习曲线较陡,但一旦建成,可实现“access数据库自动去重”的一键操作。
常见误区与优化建议
在实施去重操作时,许多用户会陷入一些认知误区,导致数据丢失或效率低下。
认为“唯一索引”能解决所有重复问题
唯一索引确实能防止新数据录入时产生重复,但它无法清理历史数据,如果你的数据库已经存在大量重复记录,必须先通过上述查询方法清理,再添加唯一索引作为预防机制。

忽略“看似不同实则相同”的数据
手机号“13800001111”和“138-0000-1111”在视觉上不同,但在业务逻辑上是同一个号码,在进行“access数据库手机号去重”时,应先使用替换功能或SQL的函数(如REPLACE)统一格式,再进行筛选。
优化建议:建立数据规范
去重只是治标,规范才是治本,建议在数据录入环节设置“必填项”和“格式验证”,并在表中设置“主键”或“唯一约束”,据行业共识认为,前端的数据校验比后端的去重处理成本更低、效果更持久。
Q&A:Access数据库筛选重复常见问题
access数据库怎么查找重复记录并显示详细信息?
在使用“查找重复项查询向导”时,务必在第四步之后,将“其他字段”中的详细信息(如姓名、日期、备注等)添加到右侧的“选定字段”列表中,这样生成的查询结果不仅会显示重复的关键字段,还会附带该记录的其他所有信息,方便你进行人工核对和处理,如果使用SQL,只需在SELECT语句中加入这些字段,并确保它们也出现在GROUP BY子句中即可。

access数据库批量删除重复项前需要注意什么?
在进行任何批量删除操作前,必须备份数据库文件,删除操作是不可逆的,建议先创建一个“查找重复查询”确认哪些记录是重复的,然后基于该查询创建一个“删除查询”,但在执行前,先将删除查询改为“选择查询”预览结果,确认无误后,再切换回删除模式执行,如果重复记录中有部分信息更完整,应先合并数据,再删除冗余行。
access数据库如何对比两个表查找重复数据?
要对比两个表(如“表A”和“表B”)中的重复数据,可以使用“查找不匹配项查询向导”的变体,或者编写SQL联合查询,使用INNER JOIN连接两个表,匹配关键字段(如“订单号”),然后筛选出两边都存在的记录,SQL示例:SELECT A.订单号 FROM 表A A INNER JOIN 表B B ON A.订单号 = B.订单号,这将返回在两个表中都存在的订单号,即为跨表重复数据。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/446755.html