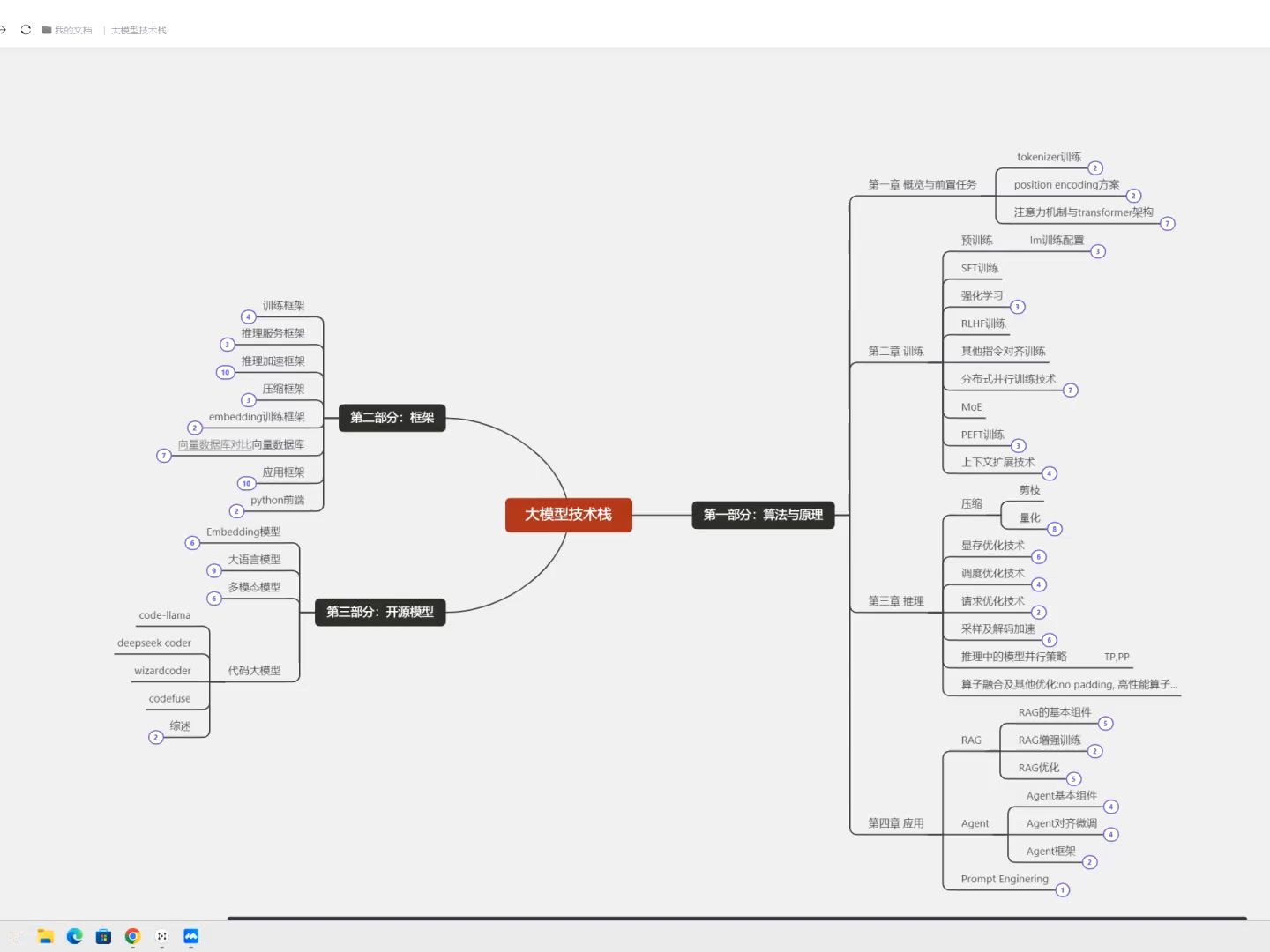
大模型技术栈的技术实现,本质上是一个从数据输入到模型推理的端到端工程化过程,其核心逻辑在于通过海量数据预训练获取通识能力,再经由指令微调与人类偏好对齐激发特定任务能力,最终依托高性能计算架构实现规模化服务。这一技术栈并非单一算法的突破,而是数据工程、算法架构、训练优化与推理部署四大核心支柱的系统性融合。

底座构建:数据工程与预处理
高质量数据是大模型能力的基石,数据工程占据了技术实现约70%的工作量。
- 数据采集与清洗:大模型训练数据通常涵盖网页文本、书籍、代码、论文等多源异构数据。核心在于去重、去噪与隐私清洗,技术团队需采用MinHash、SimHash等算法进行大规模去重,利用正则表达式和分类模型过滤低质量文本,确保输入数据的纯净度。
- 分词器训练:分词是将原始文本转化为模型可理解向量的关键步骤,目前主流采用BPE(Byte Pair Encoding)或Unigram算法。优秀的分词器能在压缩序列长度与保持词汇语义完整性之间取得平衡,直接影响模型的训练效率与推理速度。
- 数据配比:不同类型数据的配比决定了模型的“性格”与能力边界,增加代码数据比例可显著提升模型的逻辑推理能力,而高质量指令数据则能增强模型的指令遵循能力。
核心架构:Transformer及其演进
模型架构是大模型技术栈的“心脏”,决定了模型的天花板。
- Transformer架构统治地位:目前绝大多数大模型均基于Transformer架构,其核心是自注意力机制,能够并行处理序列数据并捕捉长距离依赖关系。
- Decoder-Only架构成为主流:在GPT系列成功后,Decoder-Only(仅解码器)架构因其在大规模文本生成任务中的优越性能,逐渐取代了Encoder-Decoder架构,成为生成式大模型的首选。
- 位置编码与注意力优化:为解决长文本限制,技术实现上引入了RoPE(旋转位置编码)、ALiBi等相对位置编码方案,为降低计算复杂度,FlashAttention技术通过优化显存访问机制,在不牺牲精度的情况下大幅提升了训练速度,成为当前标配。
训练优化:预训练与后训练的接力

训练过程分为预训练与后训练两个阶段,前者赋予知识,后者赋予能力。
- 大规模分布式预训练:这是算力消耗最大的阶段,技术难点在于3D并行策略(数据并行、张量并行、流水线并行)的合理配置,利用ZeRO优化器显存优化技术,可以在有限显存资源下训练千亿参数模型,预训练目标通常是预测下一个Token,通过海量数据让模型习得世界知识。
- 有监督微调(SFT):预训练模型虽具备知识,但不擅长对话,SFT阶段通过构建高质量的“指令-回答”对,打破模型“续写”惯性,激发其“问答”能力,此阶段数据质量远比数量重要,少量高质量指令数据即可显著提升模型效果。
- 人类偏好对齐(RLHF/DPO):为解决模型回答不安全、不遵循人类意图的问题,引入了基于人类反馈的强化学习。直接偏好优化(DPO)因无需训练奖励模型、流程更简化,正逐渐取代传统的PPO算法,成为高效对齐的主流方案。
推理部署:性能与成本的博弈
模型训练完成后,如何高效、低成本地部署上线是技术实现的最后一环。
- 模型量化技术:为降低显存占用,通常将FP16(16位浮点数)模型量化为INT8甚至INT4(4位整数)。AWQ、GPTQ等量化算法能在极小精度损失下,将显存需求减半,使大模型能在消费级显卡上运行。
- 推理加速引擎:KV Cache(键值缓存)是推理加速的核心技术,通过缓存已计算出的Key和Value矩阵,避免重复计算,结合PagedAttention技术(如vLLM框架),可有效管理显存碎片,将推理吞吐量提升数倍。
- 显存优化与服务化:利用连续批处理策略,动态调整Batch Size,最大化GPU利用率,技术团队通常通过Triton或Ray Serve构建服务集群,实现高并发下的稳定响应。
一文读懂大模型的技术栈的技术实现,关键在于理解这并非单一技术的突进,而是系统工程学的极致体现,从数据清洗的严谨到架构设计的精妙,再到训练策略的优化与推理部署的极致压榨,每一环都至关重要。未来的技术演进将更侧重于降低算力门槛、提升长文本处理能力以及实现更高效的端侧部署。
相关问答模块

大模型训练中,SFT(有监督微调)和RLHF(人类反馈强化学习)有什么本质区别?
SFT主要解决的是“指令遵循”问题,通过给模型展示正确的问答范例,让模型学会模仿人类的回答格式和逻辑,属于行为克隆;而RLHF解决的是“价值观对齐”问题,通过训练一个奖励模型来打分,引导模型生成更符合人类偏好(如更安全、更有用、更真实)的回答,属于价值引导。SFT决定了模型能不能好好说话,RLHF决定了模型说得是否符合人类心意。
为什么现在大模型推理都在强调KV Cache技术?
在生成式大模型的推理过程中,生成下一个Token需要依赖之前所有的Token信息,如果不使用KV Cache,每生成一个新Token都需要重新计算之前所有Token的Key和Value矩阵,计算量巨大且重复。KV Cache通过空间换时间的策略,将计算结果缓存下来,避免了重复计算,从而将推理复杂度从O(n²)降低,极大提升了生成速度,是大模型实时响应的关键技术。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/80562.html











