云计算
-
本机连接MySQL数据库密码忘了怎么办?如何修改MySQL root用户密码
本机连接MySQL数据库时,若需进行本地维护,核心在于通过命令行客户端或图形化工具使用正确的账号密码进行身份验证,确保权限匹配且网络配置允许本地回环访问,在日常开发或运维场景中,我们经常遇到需要直接在服务器或本地电脑上管理MySQL数据库的情况,这种“本机维护”并非简单的登录操作,它涉及网络协议、权限体系以及安……
-
变更备案地址怎么改?备案地址变更流程及所需材料
变更备案地址必须通过原备案接入服务商在工信部系统提交,通常需3-20个工作日审核,期间网站需保持可访问或按管局要求放置提示页,切勿擅自关闭网站否则可能导致备案被注销,备案地址变更的核心逻辑与时效解析很多站长在搬家或更换服务器机房时,第一反应是直接把网站挂到新IP上,这其实是极大的误区,备案信息是绑定在“接入服务……
-
版权保护查询难?如何查询版权保护
版权保护的核心在于“先登记后使用”,通过官方渠道进行版权查询与登记,是规避法律风险、确立权利归属最高效且低成本的手段,爆发式增长的当下,无论是原创作者还是企业法务,面对海量的图文、视频或代码,首要任务不是盲目维权,而是厘清权利边界,版权并非自动产生即具备完整对抗效力的“护身符”,尤其是涉及商业授权时,权属证明至……
-
昆仑CDN是什么,昆仑CDN加速服务好用吗
昆仑CDN在2026年依然是国内高并发、低延迟场景下的首选加速方案,其核心优势在于依托百度智能云强大的底层算力与AI智能调度能力,实现了毫秒级响应与99.99%的高可用性,特别适合电商大促、直播互动及政企高安全需求场景,核心优势与技术架构解析昆仑CDN并非传统的静态资源分发网络,而是百度智能云在2026年全面升……
-
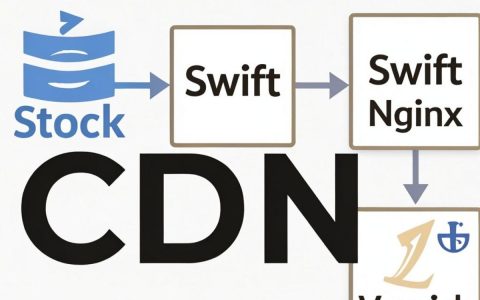
OpenStack CDN是什么,OpenStack CDN配置教程
OpenStack CDN并非原生内置模块,而是基于Swift或Ceph对象存储,通过集成Nginx、Varnish或专用CDN网关实现的边缘加速解决方案,其核心价值在于为私有云环境提供低成本、高可控的大文件分发能力,在2026年的企业级私有云架构中,随着数据主权意识的觉醒,越来越多的金融机构、政务云及大型制造……
-
CDN品牌哪个好用?CDN加速服务推荐
2026年CDN品牌选择的核心结论是:对于高并发、低延迟要求的业务,应首选具备边缘计算节点覆盖广、安全防护能力强且支持智能调度算法的头部品牌,如阿里云、腾讯云或Cloudflare,具体需根据业务地域分布与预算进行精细化选型,CDN品牌核心竞争力的2026年演变随着5G普及与AI应用下沉,CDN(内容分发网络……
-
cdn 后端配置报错怎么办,CDN加速服务
CDN后端架构的核心价值在于通过智能调度与边缘计算深度融合,实现毫秒级响应并降低源站负载,其2026年主流方案已全面转向云原生与Serverless化,综合成本较传统架构降低约30%-40%,架构演进:从静态分发到智能边缘2026年的CDN后端已不再是简单的缓存服务器集群,而是演变为具备自治能力的分布式智能体……
-
cdn icp备案流程,cdn备案需要多久
在2026年,CDN加速与ICP备案并非互斥选项,而是网站合规上线与高性能交付的“双引擎”;未备案域名无法接入国内CDN节点,且备案主体需与CDN服务合同主体一致,否则将面临服务中断风险,CDN加速与ICP备案的底层逻辑关联合规性:备案是接入国内CDN的“入场券”根据《互联网信息服务管理办法》及工信部最新监管要……
-
并发访问量多大算高?并发扩展最佳实践
并发扩展的核心在于通过水平扩容与智能负载均衡,将系统处理请求的能力从单点瓶颈转化为集群弹性,从而在流量洪峰来临时保持服务稳定不宕机,当你的网站或应用面临突发流量时,传统的单机架构往往像是一个只有一个小门的仓库,货物(请求)一旦堆积就会造成拥堵甚至瘫痪,解决这个问题的关键,不是把门修得更大,而是增加仓库的数量,并……
-
如何设置负载均衡IP黑白名单?简米云SLB白名单配置教程
白名单机制通过精准过滤IP来源,是保障负载均衡实例安全的第一道防线,建议优先启用白名单模式以阻断未授权访问,在云计算的日常运维中,负载均衡(SLB)不仅是流量的入口,更是安全防御的前沿阵地,许多开发者往往只关注后端服务的性能优化,却忽略了入口安全的重要性,当你的应用暴露在公网时,未经筛选的请求会如潮水般涌来,其……