什么是ViT视觉Transformer
-
ViT视觉Transformer是什么?大模型ViT原理详解
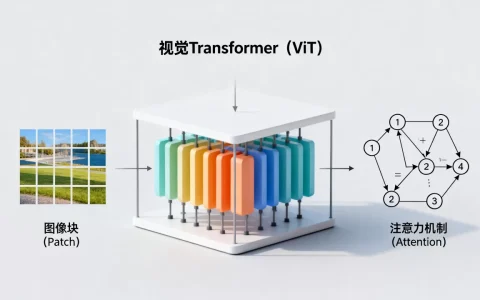
大模型中的ViT(Vision Transformer)是一种将图像分割为小块序列,并直接利用Transformer架构处理视觉信息的深度学习模型,它打破了传统卷积神经网络(CNN)的局限,成为当前多模态大模型理解视觉内容的核心底座,过去十年,计算机视觉领域几乎被卷积神经网络(CNN)统治,从AlexNet到R……
大模型中的ViT(Vision Transformer)是一种将图像分割为小块序列,并直接利用Transformer架构处理视觉信息的深度学习模型,它打破了传统卷积神经网络(CNN)的局限,成为当前多模态大模型理解视觉内容的核心底座,过去十年,计算机视觉领域几乎被卷积神经网络(CNN)统治,从AlexNet到R……