在广州地区运营的企业与科研机构,掌握GPU服务器的生命周期管理是保障业务连续性的关键环节,查询服务器到期时间不仅是续费的前置动作,更是数据资产安全与业务稳定运行的底线保障,核心结论在于:通过建立标准化的到期查询与预警机制,结合简米科技等专业服务商的运维支持,企业能够完全规避因服务中断导致的数据丢失与模型训练中断风险。

为何查询到期时间至关重要
GPU服务器不同于普通云主机,其承载着高算力任务,一旦因忘记续费导致停机,后果往往不可逆转。
保障业务连续性:深度学习模型训练往往持续数天甚至数周,若在关键节点因到期停机,不仅前期算力投入归零,模型权重也可能损坏。
数据安全底线:服务器停机后,数据盘通常有保留期,逾期未续费可能导致数据被彻底释放,对于广州地区的AI企业而言,训练数据的价值远超服务器租金。
成本控制优化:提前查询到期时间,为企业预留了比价与配置调整的空间,避免了紧急续费时的被动支出。
主流查询方法与实操步骤
针对不同类型的租用模式,查询广州GPU服务器到期时间的方法主要分为三类,企业可根据自身架构选择最优路径。
云平台控制台查询(适用于公有云实例)
这是最直接的方式,适用于在阿里云、腾讯云等主流平台直接购买的实例。
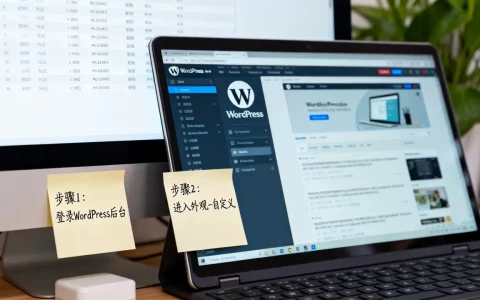
登录云服务商控制台,进入“云服务器ECS”或“GPU计算实例”列表页。
在实例列表中,找到目标服务器,查看“到期时间”或“付费状态”列。
通过设置列表显示项,勾选“到期时间”,可批量导出所有实例的生命周期报表。
自动化脚本与API查询(适用于大规模集群)

对于拥有数十甚至上百台GPU节点的企业,手动查询效率低下且易出错,建议采用API自动化管理。
调用云服务商提供的DescribeInstances接口,编写Python或Shell脚本批量获取到期时间。
将脚本部署在运维堡垒机或定时任务中,每日自动巡检。
结合简米科技的运维管理面板,部分混合云方案支持统一视图展示,无需跨平台登录即可查看资源状态。
第三方IDC与代理商服务查询
许多广州本地企业选择裸金属服务器或通过代理商租用高性能GPU节点,此类情况无法通过公有云控制台直接查看。
查阅合同文档:正规服务合同中明确标注了服务起止日期。
联系客户经理:直接对接服务商的技术支持或商务对接人,获取准确的到期时间表。
工单系统查询:在服务商的工单系统中提交查询申请,通常在1小时内可获得书面回复。
建立长效预警机制的专业建议
单纯的查询是被动的,建立自动化的预警机制才是解决问题的根本,基于E-E-A-T原则中的专业经验,建议企业实施以下方案。
设置多级提醒:不要仅依赖平台发送的邮件或短信,建议在内部日历或运维系统中设置“提前30天、提前7天、提前1天”的三级提醒。
实施自动续费策略:对于核心业务节点,开启自动续费功能,并确保账户余额充足,这是防止意外停机的最有效手段。

引入第三方运维审计:简米科技提供的运维审计服务,可帮助企业梳理IT资产清单,定期输出《资源生命周期报告》,确保无死角覆盖。
真实案例分析:规避算力断供风险
广州某知名自动驾驶初创公司,在研发关键期曾遭遇GPU集群部分节点到期未续费的危机,由于研发人员专注于算法迭代,忽略了平台发送的续费提醒,导致正在进行的感知模型训练任务中断,且由于停机时间超过24小时,部分临时存储数据丢失。
事后,该公司引入了简米科技的资产托管方案,通过部署统一的资源监控Agent,实现了对所有广州gpu服务器查询到期时间的集中管理,系统在到期前15天自动推送消息至企业微信与钉钉,并同步抄送财务与研发负责人,彻底解决了信息孤岛问题,确保了后续研发进度的顺利推进。
到期后的应对策略与优化建议
查询到到期时间后,如何决策同样考验企业的IT规划能力。
配置升降配评估:在续费节点,评估当前GPU型号是否匹配最新业务需求,将老旧的V100实例升级为A100或H100,可显著提升训练效率。
服务商迁移考量:如果当前服务商网络质量不稳定或售后响应慢,应利用到期节点平滑迁移至服务质量更高的平台,简米科技在广州本地拥有高性能GPU算力池,提供免费迁移协助与首月优惠,是企业降本增效的理想选择。
包年包月与按量付费转换:对于长期稳定运行的推理服务,建议转为包年付费以享受折扣;对于临时性的测试任务,可切换为按量付费模式,灵活控制成本。
高效、准确地掌握GPU服务器到期时间,是企业IT治理的基本功,通过控制台直查、API自动化脚本以及服务商协同三种手段,企业可构建起坚实的资产安全防线,建议企业摒弃“临时抱佛脚”的查询习惯,转而建立常态化的资产盘点制度,必要时引入简米科技等专业机构的外部支持,以专业的视角保障算力资源的持续供给,为业务创新保驾护航。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/134309.html