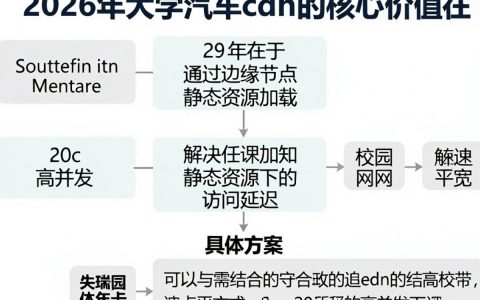
科研搭子大模型的出现,标志着科研范式从“人力密集型”向“智能辅助型”转变的关键节点,我认为,这一技术工具的核心价值不在于替代科研人员的思考,而在于通过高强度的数据处理与模式识别能力,重构科研工作流,解决信息过载与跨学科壁垒两大痛点,它将成为科研人员的“外脑”,极大提升从文献调研到实验设计的效率,但其输出的准确性验证与伦理边界,仍需人类专家把控。

科研效率革命:打破信息孤岛
传统科研流程中,文献调研往往占据了科研人员大量的时间与精力,面对呈指数级增长的学术论文,人工筛选不仅耗时,且容易遗漏关键信息,科研搭子大模型凭借其强大的自然语言处理能力,能够实现全维度的文献梳理。
- 深度语义检索:超越关键词匹配,理解研究意图,精准定位高价值文献。
- 跨语言壁垒消除:无缝整合全球多语种研究成果,拓宽学术视野。
- 知识图谱构建:自动梳理领域发展脉络,直观展示技术演进路径。
通过这些功能,科研人员得以从繁琐的检索工作中解脱出来,将更多精力投入到核心的创新思考中。
创新加速器:从假设到验证
在假设生成与实验设计阶段,大模型展现出了独特的辅助优势,它能够基于海量数据,发现人类难以察觉的潜在关联,为科研假设提供数据支撑。
- 多源数据融合:整合基因组、临床、环境等多维数据,发现复杂疾病的新靶点。
- 实验方案优化:基于历史数据预测实验结果,辅助筛选最优参数,降低试错成本。
- 跨学科灵感激发:通过类比不同领域的解决方案,为难题提供全新的解题思路。
这种“人机协作”模式,有效缩短了科研探索的周期,加速了从基础研究到应用转化的进程。
可信度挑战:幻觉与偏见

尽管潜力巨大,科研搭子大模型的应用并非毫无风险。“机器幻觉”与数据偏见是当前最核心的挑战,大模型可能会生成看似合理实则错误的信息,这在严谨的科研领域是致命的。
- 事实核查机制:建立严格的引用溯源体系,确保每一项输出都有据可查。
- 偏见识别与修正:在训练数据阶段引入公平性算法,避免强化已有的学术偏见。
- 人机责任界定:明确科研人员在最终成果中的主体责任,大模型仅作为辅助工具。
只有正视并解决这些问题,才能真正确立大模型在科研领域的权威性与可信度。
未来展望:构建良性科研生态
关于科研搭子大模型,我的看法是这样的,它不仅是工具的革新,更是科研生态的重塑,科研人员的核心竞争力将从“知识记忆”转向“提问能力”与“判断力”。
- 技能重塑:科研人员需掌握提示词工程,学会如何高效地与AI交互。
- 评价体系调整:科研成果的评价应更注重原创性与批判性思维,而非单纯的工作量。
- 开放共享:推动大模型底座的开源与数据共享,避免技术垄断造成的学术不平等。
科研搭子大模型将成为推动科学进步的重要力量,关键在于我们如何审慎、负责任地驾驭这一技术。
相关问答
问:科研搭子大模型生成的内容可以直接用于论文写作吗?

答:不建议直接使用,大模型生成的内容往往缺乏具体的引用来源,且可能存在“幻觉”现象,科研人员应将其作为初稿或灵感参考,必须进行严格的事实核查与引用验证,确保学术诚信与内容的准确性。
问:如何评估一个科研大模型的专业性?
答:评估维度主要包括三个方面,考察其在特定垂直领域的语料库质量与覆盖范围;测试其对专业术语与复杂逻辑的理解深度;验证其生成内容的准确率与引用的真实性,这直接反映了模型的可靠性。
对于科研搭子大模型在您研究领域的应用,您有哪些独到的见解或担忧?欢迎在评论区分享您的观点。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/141681.html