服务器监控端口
服务器监控端口是指运维团队持续观测的关键网络连接点,用于实时获取服务器核心性能与状态数据(如CPU、内存、磁盘、网络流量、应用进程状态等),其核心价值在于主动发现潜在瓶颈与故障,确保业务连续性,避免因资源耗尽、服务僵死或网络异常导致的意外中断,是保障IT基础设施健康运行的基石。

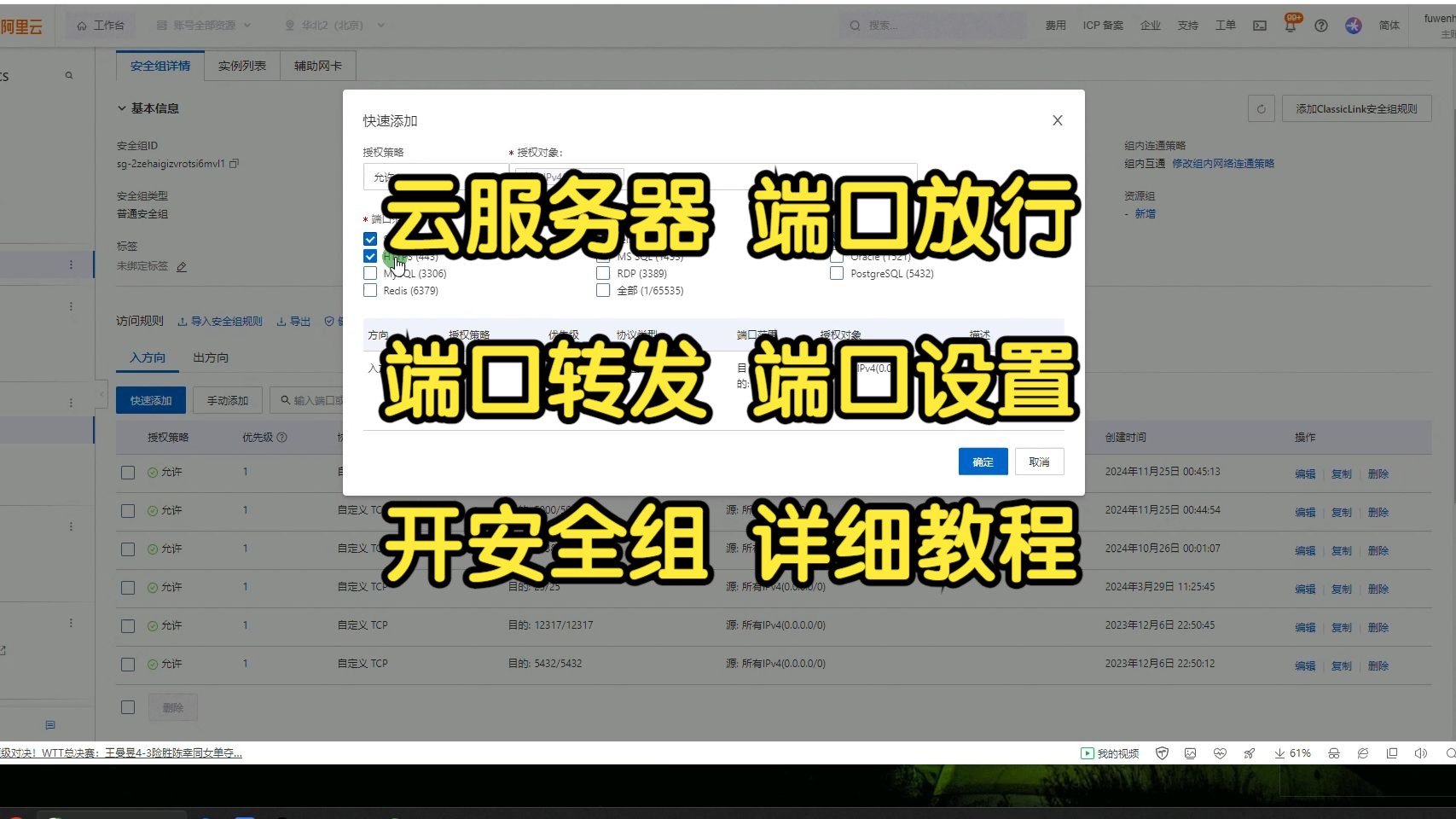
端口监控为何是运维生命线?
- 业务连续性的守护者: 服务端口(如Web服务的80/443,数据库的3306/1433)是用户访问的入口,监控其响应状态、连接数、延迟,直接关联业务可用性,一旦端口无响应或性能骤降,意味着服务中断或用户体验崩塌,需秒级告警响应。
- 资源瓶颈的预警雷达: 系统端口(如SSH的22,RDP的3389)是管理通道,其状态反映服务器基础健康,监控关联进程的资源消耗(CPU、内存),能提前预警资源耗尽风险,防止服务器因过载而宕机。
- 安全态势的关键感知: 异常端口活动(如非常规端口突发高流量、大量失败连接请求)常是攻击前兆(如端口扫描、暴力破解、后门通信),实时监控端口流量模式、连接来源,是识别入侵行为、加固安全的第一道防线。
- 性能优化的数据支撑: 持续收集端口级性能数据(连接延迟、吞吐量、错误率),可精准定位网络或应用性能瓶颈(如数据库连接池不足、Web服务器线程阻塞),为容量规划与调优提供实证依据。
专业监控的核心维度与指标
- 端口可用性:
- TCP/UDP 连通性检测: 基础中的基础,定期发起 SYN 探测或 UDP 报文,确认端口是否开放且响应。
- 关键指标: 连通状态 (Up/Down)、响应时间。
- 连接状态与负载:
- 活动连接数: 实时统计通过该端口的并发连接数量,反映当前负载压力。
- 新建连接速率: 单位时间内新建立的连接数,识别流量突发或异常增长。
- 监听队列深度: TCP 端口等待处理的连接请求队列长度,队列满将导致新连接被拒绝。
- 关键指标:
ESTABLISHED/TIME_WAIT等状态连接数、连接速率、队列长度。
- 流量分析:
- 入/出带宽: 监控通过端口的网络流量大小。
- 数据包速率: 单位时间内收发的数据包数量。
- 关键指标: 带宽利用率 (bps/Kbps/Mbps/Gbps)、PPS (Packets Per Second)、错包/丢包率。
- 应用层性能 (针对特定服务端口):
- 服务响应时间: 如 HTTP GET/POST 请求的响应时间、数据库查询执行时间。
- 事务处理速率/错误率: 如 HTTP 状态码 (5xx错误)、数据库查询错误数。
- 关键指标: 应用延迟、吞吐量 (Requests Per Second/QPS/TPS)、错误率/成功率。
常见挑战与专业解决方案
-
挑战:监控盲区与噪音干扰

- 问题: 仅监控知名端口,忽略动态端口或自定义端口;海量端口监控产生过多无效告警。
- 解决方案:
- 智能发现与基线学习: 利用工具自动扫描发现服务器活跃端口,结合CMDB信息;建立端口流量、连接数的动态基线,识别显著偏离基线的异常行为。
- 关键业务端口优先级: 严格定义核心业务依赖端口清单(如负载均衡VIP端口、核心数据库端口),设置更敏感阈值和升级策略。
- 关联分析: 将端口状态与服务器整体资源(CPU、内存)、应用日志、上下游依赖关联分析,减少误报(如因服务器重启导致的端口短暂不可用)。
-
挑战:大规模环境监控效率与成本
- 问题: 数以千计的服务器和端口,传统轮询方式开销大,数据存储与分析成本高。
- 解决方案:
- 分布式代理架构: 在每台服务器部署轻量级代理(如 Prometheus exporters, Telegraf),本地采集数据后统一上报,大幅减少中心节点压力与网络开销。
- 高效时序数据库: 采用专为监控设计的时序数据库(如 Prometheus TSDB, InfluxDB, TimescaleDB),高效压缩存储海量时间序列指标。
- 流式处理与聚合: 在数据采集端或传输过程中进行初步聚合(如计算1分钟内的平均连接数、最大带宽),减少存储与查询压力。
-
挑战:复杂网络环境下的精准探测
- 问题: 跨防火墙、NAT、复杂路由的网络路径导致外部探测结果失真;容器/K8s环境端口动态变化快。
- 解决方案:
- 内外结合探测: 外部探测(模拟用户访问)与部署在服务器/容器内部的本地探测(
netstat/ss, eBPF)相结合,获取最真实状态。 - 服务发现与动态配置: 在容器化/K8s环境中,集成服务发现机制(如 Prometheus + K8s Service Discovery),自动识别Pod IP和端口变化,动态更新监控目标。
- 网络拓扑感知: 监控系统理解网络设备(交换机、路由器、负载均衡器)状态,在端口异常时辅助定位是服务器问题还是网络路径问题。
- 内外结合探测: 外部探测(模拟用户访问)与部署在服务器/容器内部的本地探测(

构建健壮监控体系的实践框架
- 明确目标: 梳理核心业务服务及其依赖的端口,定义SLA(如99.9%可用性)。
- 工具选型与集成:
- 开源方案: Prometheus (采集/存储/告警) + Grafana (可视化) + Blackbox Exporter (外部探测) + Node Exporter (主机指标) 是强大组合,Zabbix, Nagios 也广泛应用。
- 商业方案: Datadog, Dynatrace, New Relic, 阿里云ARMS, 腾讯云Monitor 等提供全栈式APM与基础设施监控,集成度高,但成本较高。
- 关键: 工具需支持灵活的数据采集(支持多种Exporter/Agent)、强大的告警引擎(多条件、分级、降噪)、直观的可视化。
- 指标定义与采集: 为每个关键端口定义需采集的具体指标(如上述核心维度),配置采集频率(通常业务端口1分钟,基础端口5分钟)。
- 阈值设定与智能告警:
- 基于历史基线、SLA要求设定静态阈值(如端口Down、连接数 > 1000)。
- 利用机器学习或统计方法实现动态阈值告警(如流量突增300%)。
- 告警分级(P0紧急/P1高/P2中/P3低)并关联影响业务范围。
- 配置通知渠道(短信、电话、邮件、钉钉/企微/Slack)和升级策略。
- 可视化与洞察: 构建统一监控大盘,直观展示关键端口状态、历史趋势、关联资源,利用Grafana等工具创建丰富的仪表盘。
- 闭环与持续优化:
- 建立告警响应流程(On-Call轮值、故障诊断手册)。
- 定期复盘告警(分析根源、误报、改进阈值/策略)。
- 根据业务发展和技术演进(如云迁移、容器化)调整监控策略。
切记: 监控端口只是手段,核心目标是保障服务可用性与用户体验,避免“为监控而监控”,时刻将端口数据与实际业务影响关联思考。

您在服务器端口监控实践中,是否曾遭遇某个“诡异”端口问题?最终是如何抽丝剥茧定位并解决的?欢迎分享您的实战经验!
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/18912.html