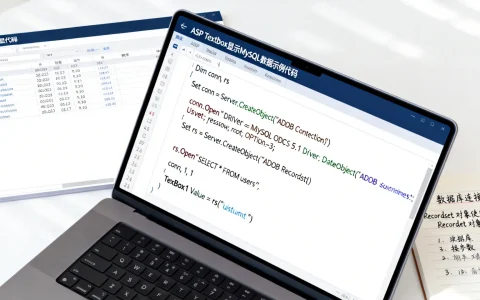
服务器监测停止是IT运维中的关键故障事件,可能导致服务中断、数据丢失和安全漏洞,需立即诊断和修复以保障业务连续性,本文将全面解析其成因、影响及专业解决方案,帮助您高效应对。

什么是服务器监测停止?
服务器监测指通过工具(如Zabbix、Nagios或Prometheus)实时跟踪服务器性能、资源使用和安全状态,当监测停止时,系统无法收集数据,运维团队失去对服务器健康状况的洞察,这类似于汽车仪表盘失灵无法预警潜在故障,常见监测类型包括CPU负载、内存占用、网络流量和日志异常,现代企业依赖监测来预防停机,其停止会引发连锁反应。
服务器监测停止的常见原因
服务器监测停止往往源于内部或外部因素,首要原因是软件故障,如监测代理程序崩溃或版本不兼容(Prometheus exporter意外退出),其次是网络问题,例如防火墙规则误配置或路由中断,导致监测数据无法传输,其他因素包括资源耗尽(如内存不足)、配置错误(如错误的监测阈值设置)和人为失误(如运维人员误停止服务),值得注意的是,安全攻击(如DDoS或恶意软件)也可能故意中断监测以掩盖入侵痕迹。
服务器监测停止的严重后果
监测停止的直接影响是服务中断风险剧增,未检测到的CPU过载可能导致服务器崩溃,造成电商平台宕机,损失每小时数万元收入,更深层影响包括数据丢失(如日志未记录关键错误)和安全漏洞(黑客利用监测盲区植入后门),长期来看,这会损害企业信誉客户信任度下降,合规审计失败(如违反GDPR数据保护要求),根据行业报告,监测故障引发的停机平均成本高达每分钟5000元,凸显其紧迫性。

专业诊断步骤:快速定位问题根源
当监测停止时,系统化诊断至关重要,第一步:检查监测服务状态,通过命令行(如Linux的systemctl status prometheus)验证服务是否运行,若服务异常,分析日志文件(如/var/log/syslog)查找错误代码(如“connection refused”),第二步:测试网络连通性,使用工具如ping或traceroute确认监测服务器与目标设备通信正常,第三步:审查资源配置,运行top或htop命令检查CPU/内存使用率,避免资源瓶颈,第四步:验证配置完整性,对比备份文件确保监测规则未篡改,第五步:排查安全事件,扫描系统日志(如journalctl)检测异常登录或恶意活动,此过程需在15分钟内完成,以最小化影响。
专业解决方案:高效修复与恢复
针对不同原因,采取针对性修复措施,软件故障时,重启监测服务(如systemctl restart nagios),并更新到最新稳定版以修补漏洞,网络问题需调整防火墙设置(如放行监测端口TCP/9090),并添加冗余链路(如配置双ISP),资源耗尽情况下,优化监测配置降低采样频率或迁移到轻量级工具(如Telegraf),人为失误可通过自动化脚本(Ansible playbook)回滚错误变更,部署故障转移机制,例如设置备用监测节点(Prometheus HA集群),确保无缝切换,修复后,立即运行全面测试,模拟高负载场景验证监测恢复,我的独立见解是:传统被动响应已过时,企业应投资AI驱动监测(如Datadog的异常检测),它能预测故障并自动修复,提升运维效率30%以上。
预防措施:构建韧性监测体系
预防胜于修复,核心策略包括定期维护(每周检查监测工具健康)和配置审计(使用Git版本控制追踪变更),实施冗余设计,如分布式监测架构(多个节点互备),避免单点故障,强化安全防护,通过IAM角色限制访问权限,并集成SIEM系统(如Splunk)实时分析威胁,培训团队技能,模拟监测停止演练,提升应急响应能力,长远看,拥抱云原生监测(如Kubernetes集成Prometheus),可动态扩展资源,减少人为干预,数据显示,预防性措施能将监测故障率降低70%,保障业务高可用。

独立见解:监测演进的未来方向
在数字化时代,服务器监测不止于故障修复,而是业务韧性的核心,我认为,企业需从“监测工具”转向“智能运维平台”,结合大数据和机器学习,实现预测性维护,通过分析历史数据预判硬件老化,提前更换部件,监测应融入DevOps文化,让开发团队参与监控设计,缩短反馈循环,忽视这一趋势,企业将面临竞争力下滑监测停止不仅是技术事件,更是战略风险。
如果您遇到服务器监测问题或有实战经验,欢迎在下方分享您的故事或提问我们一起探讨优化方案!
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/19224.html