构成存储层次的主要依据是速度、容量和成本的平衡关系,即通过构建多级存储体系,在性能与经济性之间找到最优解。
在计算机系统的内部,数据就像是在高速公路上奔跑的车辆,而存储设备则是不同等级的道路,如果所有数据都跑在最快的超跑专用道上,那造价将高到让人无法承受;如果所有数据都挤在泥泞的土路上,系统效率又会低到让人抓狂,现代计算架构不得不采用一种折中方案:存储层次结构,这种结构并非随意堆砌硬件,而是基于物理特性、经济逻辑和管理需求精心设计的金字塔。
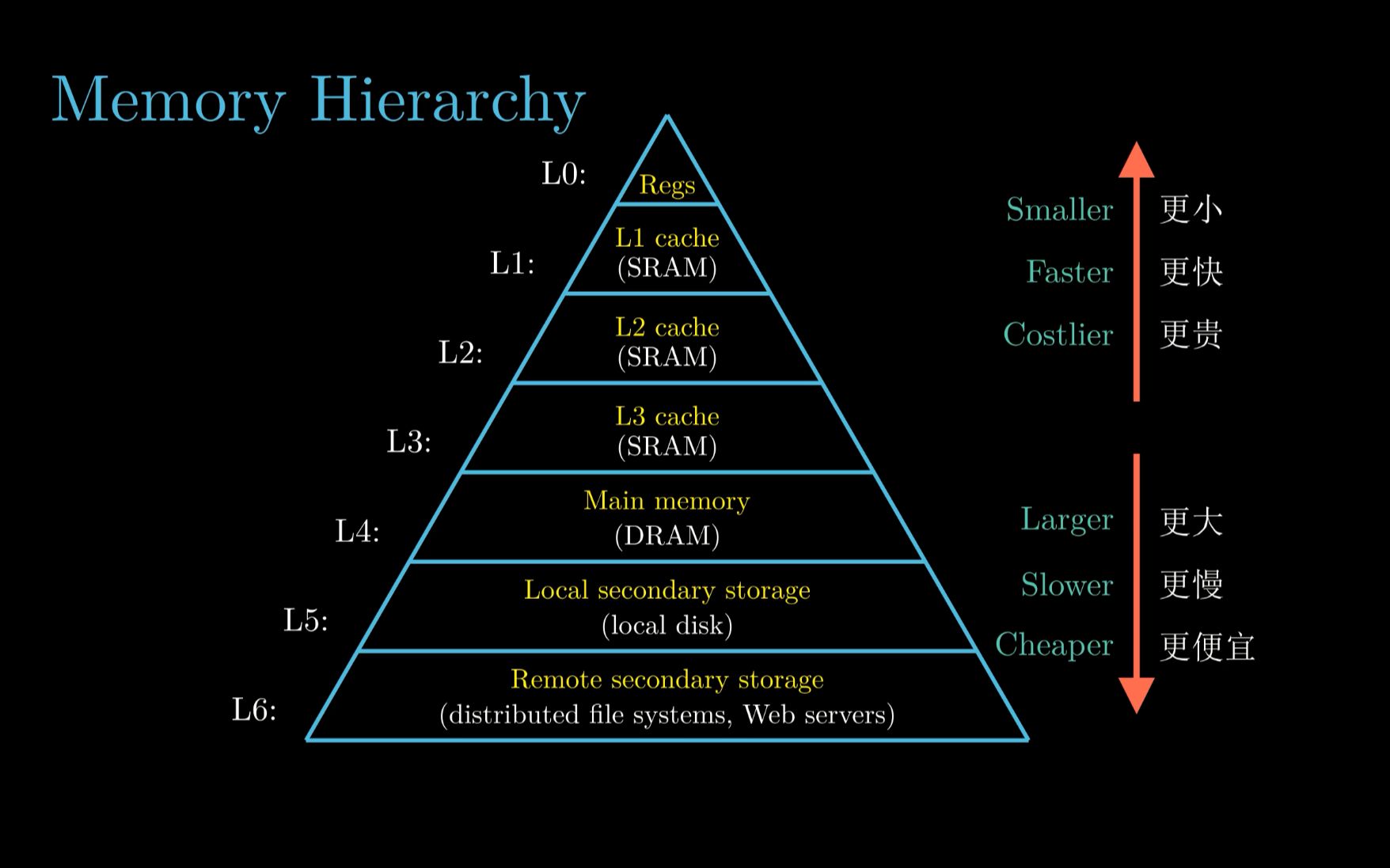
存储层次结构的核心构建逻辑
业内专家指出,存储层次的设计本质上是解决“不可能三角”:速度、容量和价格无法同时达到极致,为了理解这一逻辑,我们需要拆解构成这一层次的主要依据,它们共同决定了数据在系统中的流动路径。
访问速度与响应时间
速度是存储层次的第一驱动力,CPU的处理速度极快,如果它必须等待慢速的机械硬盘读取数据,那就像法拉利在拥堵的早高峰行驶,性能浪费惊人,靠近CPU的存储必须足够快。
- 寄存器与高速缓存:位于CPU内部或紧邻CPU,访问时间在纳秒级,用于存放当前正在执行的指令和即时数据。
- 主存储器:通常由DRAM构成,速度稍慢但容量更大,作为CPU与辅助存储器之间的缓冲区。
- 辅助存储器:包括SSD和HDD,速度较慢,但用于长期保存海量数据。
这种速度差异直接导致了数据的“冷热”分布,热数据(频繁访问)被推向高层,冷数据(极少访问)沉入底层。
单位成本与经济效益
成本是限制存储规模的关键因素,如果主存使用SRAM(静态随机存取存储器)来构建整个系统的存储,其成本将是天文数字,普通企业甚至个人用户根本无法负担。
- 价格梯度

:从寄存器到磁带库,每GB的成本呈指数级下降。
- 容量扩展:随着层级向下,存储容量急剧增加,现代数据中心中,对象存储和磁带库提供了PB甚至EB级的廉价空间。
- 性价比权衡:通过层次结构,系统可以用少量的昂贵高速存储处理热点数据,用大量廉价慢速存储保存归档数据,从而实现整体成本的最优化。

数据持久性与易失性
并非所有数据都需要在断电后保留,这一物理特性决定了哪些数据适合放在易失性存储中,哪些必须放在非易失性存储中。
- 易失性存储:如DRAM和SRAM,断电后数据丢失,适合临时计算结果、运行中的程序状态。
- 非易失性存储:如Flash、HDD、光盘、磁带,断电后数据依然保留,适合操作系统、用户文件、数据库备份。
这种区分使得系统可以在重启时快速加载关键状态,同时确保长期数据的完整性。
不同层级存储的技术实现与应用场景
理解了构建依据后,我们来看看这些理论如何在实际硬件中落地,不同的存储介质各有优劣,组合使用才能发挥最大效能。
高速缓存层级:性能的加速器
高速缓存(Cache)是解决CPU与内存速度差距的关键,它利用局部性原理,预测CPU接下来可能需要的数据并提前加载。
- L1/L2/L3缓存:L1最快但最小,L3较大但稍慢,现代多核处理器中,L3缓存常被多个核心共享。
- 写入策略:包括写直达(Write-Through)和写回(Write-Back),写回策略能显著减少内存访问次数,提升性能,但需要更复杂的一致性维护机制。
主存层级:系统的临时仓库
主存(Main Memory)是计算机工作的主战场,它直接映射虚拟地址空间,为应用程序提供统一的内存视图。
- DRAM技术演进:从DDR4到DDR5,带宽不断提升,延迟逐步降低。
- 内存池化技术:在云计算环境中,内存不再局限于单个服务器,而是通过RDMA网络实现跨节点的内存共享,提高了资源利用率。

辅助存储层级:数据的最终归宿
辅助存储承担着海量数据的持久化任务,随着技术的发展,这一层级的形态也在不断演变。
- 固态硬盘(SSD):基于NAND Flash,无机械部件,随机读写性能远超HDD,已成为现代数据中心的主流选择。
- 机械硬盘(HDD):凭借每GB极低的成本,仍在大容量冷数据存储中占据重要地位,尤其是对于视频监控、备份归档等场景。
- 磁带存储:常被忽视的“冷数据王者”,磁带具有极高的容量密度、极低的长期保存成本和优异的能源效率,据行业共识认为,对于需要保存数十年的合规性数据,磁带依然是最具经济性的选择。
存储层次优化策略与最佳实践
知道原理后,如何优化存储层次以提升系统性能?以下是几种常见的实操策略。
数据分层管理
根据数据访问频率,将数据自动迁移到不同的存储层级。
- 识别热数据:通过监控IO操作频率,识别出高频访问的数据集。
- 自动分层软件:部署存储分层软件,设置策略如“超过30天未访问的数据自动迁移至低频存储”。
- 性能监控:定期分析分层效果,调整迁移阈值,避免过度迁移导致的性能抖动。
缓存命中率优化
提高缓存命中率是提升系统响应速度的直接手段。
- 预取机制:预测数据访问模式,提前将后续数据加载到缓存中。
- 替换算法:采用LRU(最近最少使用)或ARC(自适应替换缓存)等算法,确保缓存中始终保留最有价值的数据。
- 容量规划:根据工作负载特点,合理分配各级缓存的大小,避免缓存溢出或资源浪费。

混合存储架构设计
对于大多数企业而言,纯SSD成本过高,纯HDD性能不足,混合架构是现实之选。
- 全闪存阵列:适用于核心数据库、虚拟化平台等对延迟极度敏感的场景。
- 混合闪存阵列:结合SSD和HDD,SSD作为缓存层加速热点数据,HDD作为容量层存储冷数据。
- 对象存储集成:将非结构化数据(如图片、视频、日志)存入对象存储,通过API接口访问,实现存储与计算的解耦。
常见问题解答:存储层次相关疑问
存储层次的主要依据是什么?
存储层次的主要依据是速度、容量和成本的平衡,是利用不同存储介质在访问速度、单位成本和持久性上的差异,构建一个金字塔形的结构,高层存储速度快、容量小、成本高,用于处理热点数据;底层存储速度慢、容量大、成本低,用于保存冷数据,这种设计旨在以最低的总体成本,提供满足应用性能需求的存储服务。
如何判断数据是否适合放入高速缓存?
判断数据是否适合放入高速缓存,主要看其访问频率和局部性,如果数据在短时间内被多次访问(时间局部性),或者其相邻数据也被频繁访问(空间局部性),则非常适合放入缓存,对于写多读少的数据,需谨慎使用写回策略,以免数据丢失风险增加。
SSD和HDD在存储层次中各自扮演什么角色?
SSD通常扮演“加速层”或“主存储层”的角色,因其高IOPS和低延迟,适合存放操作系统、应用程序、数据库索引等热数据,HDD则扮演“容量层”或“归档层”的角色,因其高容量和低每GB成本,适合存放备份文件、视频素材、历史日志等冷数据,在现代架构中,两者常通过自动分层技术协同工作,SSD缓存HDD上的热点数据,从而兼顾性能与成本。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/204440.html











