湖仓一体并非简单的技术堆砌,而是通过统一元数据管理打破数据孤岛,在降低存储成本的同时实现实时分析与离线计算的融合,是2026年企业构建现代化数据基础设施的最优解。
过去几年,企业数据架构经历了从数据仓库到数据湖,再到数据湖仓的演变,到了2026年,单纯的“存”或“算”已无法满足业务需求,企业面临的核心痛点是:既要像数据仓库那样保证数据的准确性、一致性和高性能查询,又要像数据湖那样容纳海量非结构化数据并支持低成本存储,湖仓一体(Data Lakehouse)正是为了解决这一矛盾而生,它不是两种技术的物理拼接,而是通过底层存储格式(如Parquet、Iceberg、Hudi)和计算引擎的深度融合,实现“一次写入,多处消费”。
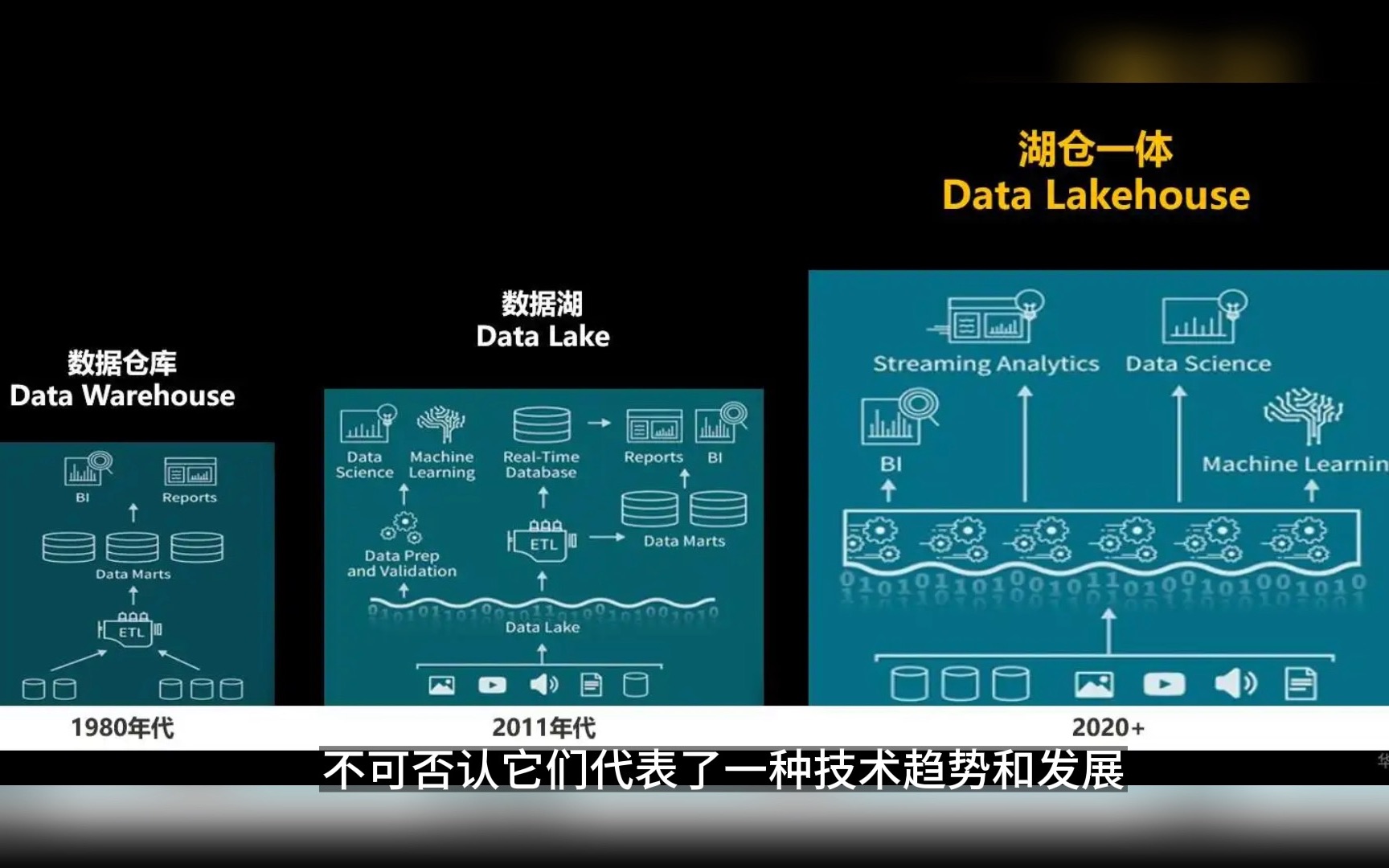
湖仓一体架构的核心优势解析
业内专家指出,湖仓一体的核心价值在于消除了数据冗余和数据搬运带来的延迟与错误,在传统架构中,数据从数据湖清洗后导入数据仓库,这个过程不仅耗时,还容易出错,湖仓一体让数据只需存储一份,即可同时服务于BI报表、机器学习模型和实时大屏。
降低总体拥有成本
存储成本是企业数据支出的大头,传统数据仓库基于专有硬件或封闭云环境,扩容昂贵且灵活度低,湖仓一体通常运行在对象存储(如AWS S3、阿里云OSS)之上,存储成本仅为传统数仓的十分之一甚至更低,计算与存储分离架构允许企业根据负载动态调整计算资源,用多少算多少,避免了资源闲置浪费。
提升数据时效性
传统ETL流程往往以天或小时为单位,难以支撑实时决策,湖仓一体支持微批处理和流式写入,数据进入数据湖后可在分钟级甚至秒级内被查询引擎发现,对于电商大促、风控拦截等场景,这种时效性意味着直接的业务价值。
统一数据治理
数据孤岛导致“数据找不到、不敢用”,湖仓一体通过统一的元数据目录,对所有数据资产进行集中管理,无论是结构化表格还是非结构化文件,都拥有统一的身份标识和权限控制,数据工程师无需在不同系统间切换,即可实现数据血缘追踪和质量监控。

构建湖仓一体数据仓库怎么样:技术选型与落地
很多企业在询问“构建湖仓一体数据仓库怎么样”时,往往忽略了技术选型的复杂性,2026年的技术生态已经相对成熟,但选择合适的工具链依然关键。
表格式选择:Iceberg与Hudi的博弈
表格式是湖仓一体的灵魂,它决定了数据更新、删除和时间旅行能力的效率,目前主流选择包括Apache Iceberg、Apache Hudi和Delta Lake。
- Apache Iceberg:以高性能和兼容性著称,支持复杂的Schema演进,适合大规模离线分析和批处理场景,其隐藏分区机制简化了数据管理。
- Apache Hudi:在流式写入和增量处理方面表现优异,特别适合需要频繁小批量更新的数据场景,如用户行为日志。
- Delta Lake:由Databricks主导,与Spark生态集成紧密,适合已经深度使用Spark的技术团队。
计算引擎的适配
计算引擎需要能够高效读取上述表格式,Trino(原PrestoSQL)因其强大的多数据源查询能力,成为湖仓一体架构中的常见选择,它允许用户通过SQL直接查询存储在对象存储中的Iceberg或Hudi表,无需数据迁移,对于实时性要求更高的场景,Flink可以作为流处理引擎,将实时数据写入湖仓,实现流批一体。
实施路径:从POC到生产
构建湖仓一体不是一蹴而就的,建议遵循以下路径:
- 数据分层设计:明确ODS(原始数据层)、DWD(明细数据层)、DWS(汇总数据层)和ADS(应用数据层)的边界,湖仓一体适合在DWD和DWS层实施,保留原始数据的灵活性。
- 元数据迁移:将传统数仓的元数据导入湖仓的元数据服务中,确保数据血缘的连续性。
- 查询性能优化:针对高频查询场景,建立物化视图或索引,湖仓一体虽然灵活,但全表扫描依然昂贵,合理的分区和聚类策略至关重要。

常见误区与避坑指南
尽管湖仓一体优势明显,但企业在落地过程中常犯错误,了解这些误区,能避免大量试错成本。
认为湖仓一体能替代所有数据仓库
湖仓一体并非万能药,对于极高并发、极低延迟的OLTP场景,关系型数据库依然是最佳选择,湖仓一体主要面向OLAP(分析型)场景,如果业务需要毫秒级响应的事务处理,不应强行迁移至湖仓。
忽视数据质量治理
“垃圾进,垃圾出”在湖仓一体中更为致命,由于数据源多样化,数据质量参差不齐,必须建立自动化数据质量监控体系,在数据写入湖仓时进行校验,否则,混乱的数据将导致分析结果不可信,进而失去业务部门的信任。
过度追求技术先进性
不要盲目追求最新的技术栈,稳定性、团队技能和社区支持同样重要,如果团队熟悉Spark和Delta Lake,强行切换到Iceberg可能带来不必要的学习成本和运维风险,选择最适合团队现状的技术,而非最热门的技术。
湖仓一体数据仓库价格与ROI分析
企业决策者最关心的往往是投入产出比,构建湖仓一体数据仓库价格通常低于传统数仓,但隐性成本不容忽视。
直接成本对比
| 成本项 | 传统数据仓库 | 湖仓一体架构 |
|---|---|---|
| 存储成本 | 高(专有存储或高配云盘) | 低(对象存储,按量付费) |
| 计算成本 | 固定或按节点计费 | 弹性伸缩,按查询量计费 |
| 数据搬运成本 |
高(频繁ETL) | 低(一次写入,多处读取) |
| 运维成本 | 高(需专人维护集群) | 中(依赖云原生服务,自动化程度高) |

隐性收益
除了直接的成本节约,湖仓一体带来的隐性收益更为显著,数据科学家可以直接在湖中访问原始数据,无需等待数据工程师清洗入库,这将模型迭代周期缩短了30%-50%,统一的数据视图减少了数据冲突,提升了跨部门协作效率。
Q&A:关于构建湖仓一体数据仓库的常见疑问
构建湖仓一体数据仓库怎么样,是否适合中小企业?
中小型企业资源有限,传统数仓的运维成本过高,湖仓一体基于云原生架构,无需自建硬件,按需付费,降低了入门门槛,对于数据量在TB级别以上的中小企业,湖仓一体是性价比极高的选择,建议从非核心业务场景入手,逐步迁移。
湖仓一体与传统数据仓库的主要区别是什么?
主要区别在于存储格式和架构灵活性,传统数仓通常使用专有列式存储,数据需经过ETL清洗后入库,结构固化,湖仓一体使用开放格式(如Iceberg),数据以原始形态存储,支持Schema演进和ACID事务,无需频繁搬运数据,实现了存算分离和统一访问。
实施湖仓一体需要多长时间?
实施周期取决于数据规模、复杂度和团队经验,对于数据量较小、结构简单的场景,POC验证可能只需2-4周,全面迁移和治理可能需要3-6个月,建议采用敏捷迭代方式,先打通关键数据链路,再逐步扩展。
构建湖仓一体数据仓库怎么样?答案是肯定的,它是数据架构演进的必然方向,通过统一存储、计算分离和开放格式,企业能够以更低的成本、更高的效率释放数据价值,关键在于选择合适的技术栈,建立完善的数据治理体系,并逐步推进迁移。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/205327.html











