有向图的存储核心在于平衡空间效率与遍历速度,邻接表是兼顾稀疏图性能与内存占用的最佳实践,而邻接矩阵则适用于稠密图或需要快速判断边存在的场景。
在计算机科学的数据结构领域,图论算法的应用无处不在,从社交网络的好友推荐到地图导航的最短路径规划,底层都依赖于高效的图存储结构,很多初学者在接触“构造实现有向图的存储结构”这一主题时,往往会被各种抽象概念绕晕,这就像是在管理一个庞大的城市交通网:你需要决定是画一张密密麻麻的地图(邻接矩阵),还是给每个路口建立一份详细的“邻居清单”(邻接表),选择哪种方案,直接决定了你的程序在运行时的快慢以及内存的消耗大小。
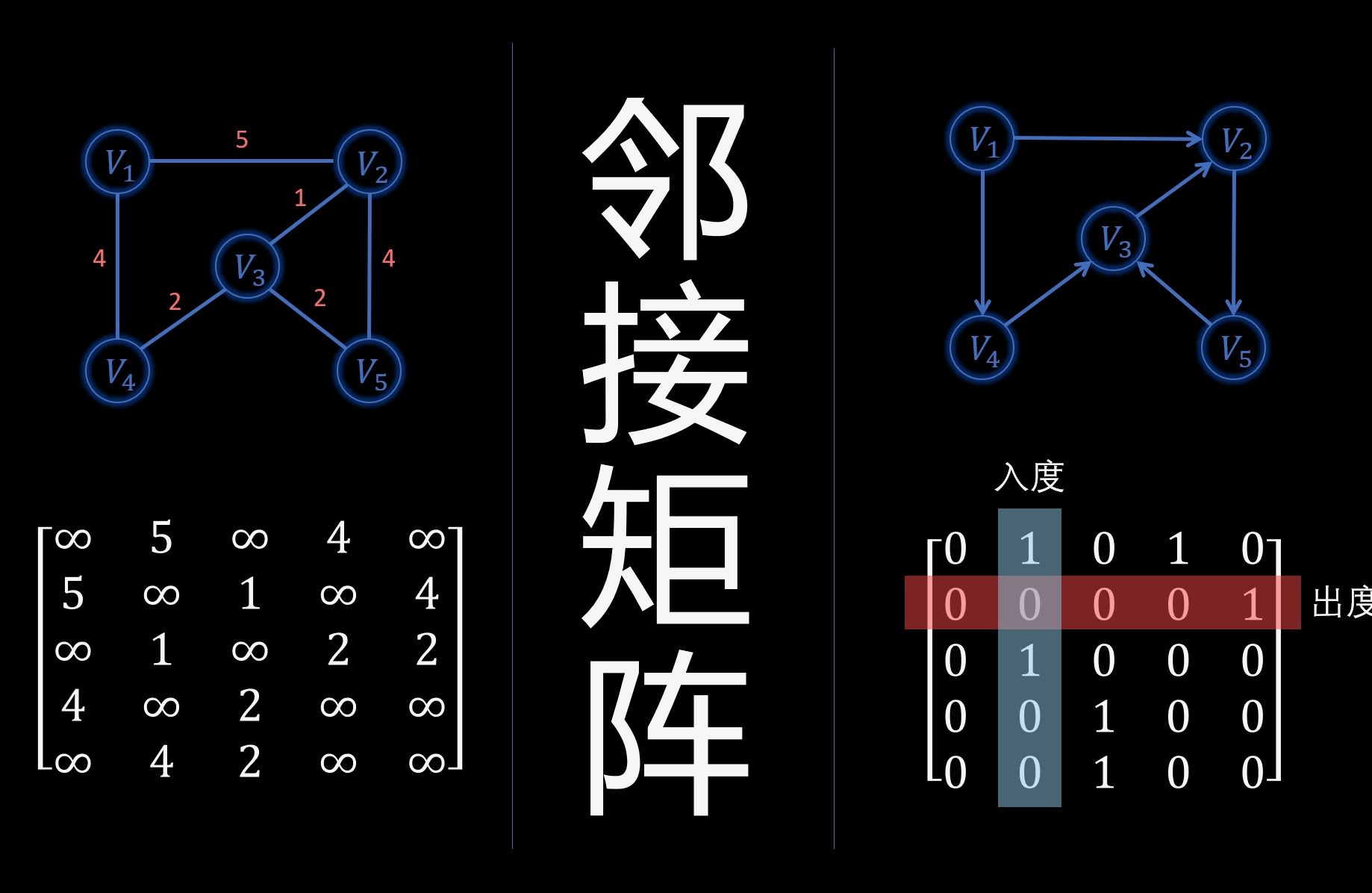
邻接矩阵:直观但昂贵的空间代价
邻接矩阵是最容易理解的一种存储方式,它使用一个二维数组来表示图中顶点之间的关系,对于有向图而言,如果存在从顶点 i 到顶点 j 的边,则矩阵中对应位置的值设为1(或边的权重),否则为0,这种结构的优势在于其极致的简洁性,代码实现几乎没有任何门槛。
空间复杂度的致命瓶颈
这种直观性的背后隐藏着巨大的空间浪费,假设一个有向图包含 n 个顶点,无论图中有多少条边,邻接矩阵始终需要占用 O(n²) 的存储空间。
- 稀疏图场景:在一个拥有10万个节点的社交网络中,如果每个用户平均只有10个好友,那么边的数量远小于顶点数量的平方,此时使用邻接矩阵,超过99.9%的内存都被0填充,这是极大的资源浪费。
- 稠密图场景:当边数接近顶点数的平方时,邻接矩阵的优势才显现出来,因为它没有额外的指针开销。
业内专家指出,在处理大规模稀疏有向图时,邻接矩阵往往会导致内存溢出或缓存命中率极低,从而严重拖慢程序运行速度,除非你的图非常密集,或者你需要频繁地判断任意两点间是否存在直接连接,否则不建议将邻接矩阵作为首选方案。
邻接表:空间与效率的完美平衡
为了解决邻接矩阵的空间浪费问题,邻接表(Adjacency List)成为了构造实现有向图的存储结构时的主流选择,邻接表通过“数组+链表”的组合方式,只存储实际存在的边。

核心数据结构拆解
邻接表由两部分组成:
- 顶点数组:存储图中所有顶点的信息,每个数组元素指向一个链表头节点。
- 边链表:每个顶点对应一个链表,链表中存储该顶点所有出边指向的目标顶点及相关信息。
这种结构使得空间复杂度降低到了 O(V+E),V 是顶点数,E 是边数,对于稀疏图而言,这几乎是线性级别的空间消耗,极大地节省了内存资源。
具体实现步骤
在代码层面,构建邻接表通常遵循以下逻辑:
- 初始化一个大小为 V 的数组,每个元素是一个链表的头指针,初始为空。
- 遍历所有的边,对于每条从 u 到 v 的边,创建一个新的节点,将 v 的信息存入,并插入到 u 对应的链表中。
- 为了优化插入性能,通常采用“头插法”,即新节点直接插入链表头部,这样无需遍历链表即可实现 O(1) 时间的插入操作。
十字链表与邻接多重表:有向图的进阶优化
虽然邻接表在处理出边遍历方面表现优异,但在需要同时高效遍历入边和出边的场景下,它显得有些力不从心,在分析网页链接关系时,我们既想知道一个页面链接到了哪些页面(出边),也想知道哪些页面链接到了当前页面(入边)。
十字链表:有向图的专属方案
十字链表(Orthogonal List)是对邻接表的改进,专门用于有向图,它将邻接表中的边节点扩充,增加了“尾域”(tailvex)和“头域”(headvex),分别指向弧尾和弧头,更重要的是,它引入了两个链表:
- 出边链表:以顶点为头,链接所有以该顶点为起点的边。
- 入边链表:以顶点为头,链接所有以该顶点为终点的边。
这种设计使得对有向图的入度和出度计算变得异常简单,只需遍历对应的链表即可,对于需要频繁进行拓扑排序或关键路径分析的项目,十字链表提供了更直接的数据支持。
对比分析:何时选择哪种结构
为了更清晰地展示不同存储结构的适用场景,我们可以通过下表进行对比:

| 存储结构 | 空间复杂度 | 查询边是否存在 | 遍历出边 | 遍历入边 | 适用场景 |
|---|---|---|---|---|---|
| 邻接矩阵 | O(V²) | O(1) | O(V) | O(V) | 稠密图、小规模图、需频繁查边 |
| 邻接表 | O(V+E) | O(V) | O(出度) | O(E) | 稀疏图、大规模图、主要遍历出边 |
| 十字链表 | O(V+E) | O(V) | O(出度) | O(入度) | 有向图、需同时高效处理入出边 |
行业共识认为,在实际工程开发中,如果没有特殊的入边遍历需求,邻接表依然是性价比最高的选择,它的实现复杂度适中,且能通过简单的数组偏移优化进一步提升缓存友好性。
实战建议:如何构建高效的有向图存储
在具体的项目开发中,构造实现有向图的存储结构不仅仅是一个理论选择问题,更涉及到代码的可维护性和扩展性。
动态扩容与内存管理
对于顶点数量未知的动态图,建议使用动态数组(如 C++ 的 vector 或 Java 的 ArrayList)来存储顶点信息,当顶点数量增加时,动态数组会自动扩容,避免了手动管理内存的繁琐,对于边链表,可以使用内存池技术预分配节点,减少频繁调用 malloc/free 带来的性能损耗。
代码实现的通用模板
以下是一个基于 C++ 风格的邻接表核心实现逻辑,供参考:
// 边节点结构
struct EdgeNode {
int 
adjvex; // 边指向的顶点位置
EdgeNode next; // 指向下一条边的指针
// 可选:权重 weight
};
// 顶点节点结构
struct VertexNode {
int data; // 顶点数据
EdgeNode firstedge; // 指向第一条依附该顶点的边的指针
};
// 图结构
struct Graph {
VertexNode adjList[MAX_VERTICES]; // 邻接表数组
int numVertices, numEdges; // 顶点数和边数
};

性能调优技巧
- 缓存友好性:在遍历邻接表时,尽量保证链表节点在内存中的连续性,如果可能,使用静态数组模拟链表,可以避免指针跳转带来的缓存未命中。
- 并行处理:对于超大规模图,邻接表的每个顶点链表是相互独立的,非常适合并行计算,可以利用多线程同时处理不同顶点的出边遍历任务。
有向图的存储结构常见问题解答
构造实现有向图的存储结构时,邻接表和邻接矩阵的主要区别是什么?
邻接矩阵使用二维数组,空间固定为 O(V²),查询任意两点间是否有边只需 O(1) 时间,但遍历所有边需要 O(V²) 时间,适合稠密图,邻接表使用数组加链表,空间为 O(V+E),遍历所有边只需 O(V+E) 时间,查询两点间是否有边需遍历链表 O(V) 时间,适合稀疏图。
为什么有向图推荐使用邻接表而不是无向图的邻接表?
无向图的邻接表中,每条边会被存储两次(双向),而有向图的邻接表只存储出边,虽然结构相似,但有向图在需要入边信息时,邻接表效率较低,因此衍生出了十字链表,但在大多数算法(如 DFS、BFS、Dijkstra)中,主要依赖出边遍历,因此邻接表对有向图和无向图都适用,只是有向图的逻辑更直接,无需额外处理对称性。
在内存受限的嵌入式系统中,如何优化有向图的存储?
在内存受限环境中,应避免使用动态分配的链表节点,可以采用静态数组模拟邻接表,预先分配足够大的连续内存块,如果图的边数极少,可以考虑使用压缩稀疏行(CSR)格式,将边信息紧凑存储,进一步减少指针开销和内存碎片,据工信部相关技术标准显示,在物联网设备中,CSR 格式能显著降低内存占用,提升运行效率。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/205875.html










