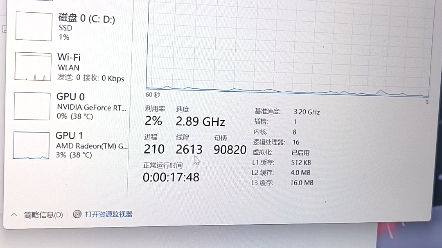
服务器查看内存图
查看服务器内存使用情况并生成直观图表,是系统管理员和运维工程师进行性能监控、故障排查及容量规划的核心任务,关键在于选择合适的工具组合,精准捕捉内存消耗趋势与异常点。

基础命令行工具:快速诊断基石
-
free命令:内存概况快照- 核心用法:
free -h(人类可读格式显示) - 关键指标解读:
Mem: 物理内存总量 (total)、已使用 (used)、空闲 (free)、用于缓存/缓冲区的内存 (buff/cache)、可用内存 (available– 估算新应用可用的量,最实用)。Swap: 交换空间总量 (total)、已使用 (used)、空闲 (free),高Swap使用是物理内存不足的强烈信号。
- 优势:几乎所有 Linux 发行版默认安装,执行迅速。
- 核心用法:
-
top/htop命令:实时进程级洞察- 运行
top后,按M键可按内存使用率对进程排序。htop(需安装) 提供更友好的交互界面和彩色显示。 - 关键列:
VIRT:进程使用的虚拟内存总量。RES:进程实际使用的、未被换出的物理内存大小 (常驻内存),是判断进程真实内存占用的关键。%MEM:进程使用的物理内存 (RES) 占总物理内存的百分比。
- 优势:实时查看哪个进程是内存消耗大户。
- 运行
-
vmstat命令:系统级内存事件统计- 核心用法:
vmstat 1 5(每秒采样一次,共5次) - 关键内存相关列 (
memory部分):swpd:已使用的交换空间大小。free:空闲的物理内存量。buff:用作缓冲区的内存量。cache:用作页缓存的内存里。
- 关键事件列 (
swap和io部分):si(swap in):每秒从磁盘交换区读入到内存的数据量 (kB),持续非零值需警惕。so(swap out):每秒从内存写出到磁盘交换区的数据量 (kB),持续非零值需警惕。
- 优势:揭示内存压力是否导致频繁的交换 (
si/so),这是性能严重下降的根源。
- 核心用法:
图形化监控解决方案:趋势分析与告警

-
Prometheus + Grafana (开源黄金组合)
- 原理:
- Node Exporter:部署在目标服务器上,收集包括内存在内的系统指标 (
node_memory_系列指标)。 - Prometheus:定时拉取 (
scrape) Node Exporter 暴露的指标数据,并存储在时序数据库中。 - Grafana:连接 Prometheus 数据源,通过强大的可视化能力创建丰富的内存监控仪表盘。
- Node Exporter:部署在目标服务器上,收集包括内存在内的系统指标 (
- 核心内存指标 (通过 Prometheus 查询):
- 总内存:
node_memory_MemTotal_bytes - 已使用内存:
node_memory_MemTotal_bytes - node_memory_MemFree_bytes - node_memory_Buffers_bytes - node_memory_Cached_bytes(更准确) 或node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes(更简单,MemAvailable是内核估算值)。 - 可用内存:
node_memory_MemAvailable_bytes - 缓存:
node_memory_Cached_bytes - 缓冲区:
node_memory_Buffers_bytes - 交换总量:
node_memory_SwapTotal_bytes - 已用交换:
node_memory_SwapCached_bytes + (node_memory_SwapTotal_bytes - node_memory_SwapFree_bytes)或直接node_memory_SwapTotal_bytes - node_memory_SwapFree_bytes
- 总内存:
- Grafana 仪表盘优势:
- 趋势图:展示内存使用率、可用内存、Swap 使用率随时间的变化曲线,清晰识别增长趋势、峰值和周期性模式。
- 面板组合:在同一仪表盘中集成内存总量、使用率、Swap、Cache/Buffer 等关键信息面板。
- 阈值告警:在 Grafana 或 Prometheus Alertmanager 中设置规则 (如
可用内存 < 10% 总内存或Swap 使用率 > 5%持续 X 分钟),触发邮件、Slack、钉钉等通知。 - 多服务器视图:在一个视图内监控整个服务器集群的内存状态。
- 部署:这是当前开源领域监控服务器内存(及所有基础设施)的事实标准方案,强烈推荐用于生产环境,社区有大量现成的 Node Exporter 采集配置和 Grafana 仪表盘模板可用。
- 原理:
-
操作系统内置工具
- GNOME System Monitor (Linux Desktop):提供直观的图形界面查看内存和 Swap 使用历史图表。
- Windows 任务管理器/性能监视器 (PerfMon):
- 任务管理器“性能”标签页提供实时内存使用图和详细信息 (使用中/可用/已提交/缓存/分页池/非分页池)。
- 性能监视器 (
perfmon.msc) 可添加计数器 (如Memory -> % Committed Bytes In Use,Memory -> Available MBytes,Paging File -> % Usage),记录数据并生成图表,功能更强大。
-
商业监控平台
- Dynatrace, Datadog, New Relic, Zabbix, SolarWinds 等:提供开箱即用的服务器内存监控仪表盘、智能基线、异常检测、根因分析、与 APM 的关联等功能,优势是集成度高、功能全面、企业级支持,适合大型或复杂环境,但通常需要付费订阅。
专业内存分析进阶
smem工具:提供更精细的进程内存报告 (PSS– Proportional Set Size,USS– Unique Set Size),比top的RES更能反映共享内存的真实占用。slabtop命令:实时显示内核 slab 缓存 (由kmalloc,kmem_cache等分配) 的使用情况,诊断内核级内存消耗或泄露。valgrind(特别是massif工具):主要用于开发阶段,对应用程序进行堆内存分析,生成内存分配峰值和随时间变化的图表,定位代码级内存泄露或低效使用。/proc/meminfo文件:这是free,top等命令的数据来源,直接查看此文件 (cat /proc/meminfo) 获取最原始、最全面的内存统计信息字段。
关键见解与优化方向:

MemAvailable是核心指标:它比free更能反映系统实际可用于启动新应用或缓存新数据的内存,因为它包含了可回收的 Buffer/Cache,监控告警应优先关注MemAvailable过低。- Buffer/Cache 不是“坏东西”:Linux 会积极利用空闲内存做磁盘缓存 (
cache) 和缓冲 (buffer),这是提升 I/O 性能的关键机制,当应用需要内存时,这部分内存会被内核快速回收,看到free很小但available充足是正常且高效的。 - Swap 使用是性能悬崖的信号:即使物理内存未耗尽,早期、轻微的 Swap 活动 (
si/so > 0) 也应引起重视,它表明内存压力开始形成,持续或大量的 Swap 必然导致性能急剧下降,优化目标是尽可能减少或消除 Swap 活动。 - 分析趋势重于单点快照:单次
free或top的结果价值有限,通过 Grafana 等工具绘制历史图表,才能识别内存泄漏 (使用量持续缓慢增长)、周期性高峰 (如每日报表任务)、或配置变更后的影响。 - 根本原因定位:发现内存不足后,结合
top/htop(看RES,%MEM)、smem(看PSS/USS)、ps(如ps aux --sort=-%mem | head) 找出消耗最大的进程,进一步分析该进程自身是否存在内存泄露或配置不当。
掌握服务器内存状态的核心在于分层监控:使用 free, top, vmstat 进行快速现场诊断;部署 Prometheus + Node Exporter + Grafana 实现历史趋势可视化、多机聚合与智能告警(生产环境首选方案);在需要深入分析特定进程或内核内存时,选用 smem, slabtop 或 valgrind,深刻理解 MemAvailable 的意义、Buffer/Cache 的作用机制以及 Swap 的危害性,是进行有效内存性能调优和容量规划的基础,持续监控内存使用趋势图,是预防性能问题和保障服务器稳定运行的必备手段。
你的服务器内存监控方案主要依赖哪些工具?是否遇到过因内存问题导致的棘手故障?欢迎在评论区分享你的实战经验和见解!
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/26124.html