专业分析与解决方案
核心方法: 在服务器上快速识别消耗内存最多的进程,最常用且高效的方式是在 Linux 终端执行命令:ps aux --sort=-%mem | head -n 11,这条命令会列出所有进程,按内存使用百分比降序排列,并显示前 11 行(通常包含表头)。
")
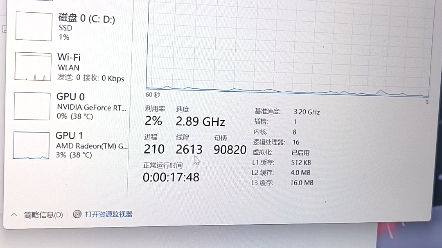
掌握服务器内存使用情况是系统管理的核心,当服务器响应变慢或应用异常时,精准定位内存消耗大户是解决问题的第一步,以下为您提供专业、全面的分析与操作指南。
Linux/Unix 系统:核心工具详解
-
ps命令:精准排序与筛选- 按内存排序:
ps aux --sort=-%mem | head(aux显示所有用户进程,--sort=-%mem按内存百分比降序,head显示前10行)。 - 按实际内存 (RSS) 排序:
ps aux --sort=-rss | head(RSS 表示进程实际占用的物理内存,更直观)。 - 关键输出列解读:
%MEM:进程占用物理内存的百分比。RSS:常驻内存集 (Resident Set Size),单位 KB,表示进程实际使用的物理内存大小。VSZ:虚拟内存大小 (Virtual Memory Size),单位 KB,包含进程可能访问的所有内存(如共享库、分配但未使用的内存)。PID:进程 ID。USER:启动进程的用户。COMMAND:启动进程的命令行。
- 按内存排序:
-
top/htop:实时动态监控top:- 运行后按
Shift + M(大写 M) 立即按内存使用百分比 (%MEM) 降序排列进程。 - 表头
RES对应 RSS (物理内存),SHR是共享内存大小。 - 提供实时刷新的 CPU、内存总量及使用情况概览。
- 运行后按
htop(推荐):top的现代化增强版,支持鼠标操作、色彩高亮、更直观的树状视图。- 默认按 CPU 排序,直接点击
MEM%列标题即可按内存排序。 - 可轻松查看进程树结构(按
F5),识别关联进程组的内存消耗总和。
-
free//proc/meminfo:理解系统整体内存状态")
free -h(-h人类可读格式): 快速查看系统总内存、已用内存、空闲内存、缓存 (buff/cache) 和交换空间 (swap) 使用情况,理解available列是关键,它表示应用程序可用的物理内存估算值(包含可回收的缓存)。cat /proc/meminfo: 提供极其详细的内存统计信息,包括各种内存类型(MemTotal, MemFree, MemAvailable, Buffers, Cached, SwapCached, Active, Inactive, Slab 等),是深入分析内存分配的基础。
-
进阶工具:深入剖析内存构成
pmap -x <PID>: 详细报告指定进程 (<PID>) 的内存映射,显示不同内存段(代码、数据、堆、栈、共享库等)的大小及权限。-x选项显示更详细扩展信息。smem: 提供更符合实际内存消耗的统计,如 Proportional Set Size (PSS) 和 Unique Set Size (USS),能更公平地分摊共享库的内存占用,对识别真实内存消耗大户尤其有用(通常需安装:sudo apt install smem/sudo yum install smem)。/proc/<PID>/smaps: 提供比pmap更细粒度的进程内存映射信息,包含每个映射区域的详细统计(RSS, PSS, Private_Clean, Private_Dirty, Shared_Clean, Shared_Dirty 等),是分析内存泄漏、共享内存使用的利器。
")
Windows 系统:关键工具与方法
-
任务管理器 (Task Manager):
- 按下
Ctrl + Shift + Esc或Ctrl + Alt + Del选择任务管理器。 - 切换到 “详细信息” (Details) 选项卡。
- 点击 “内存” (Memory) 列标题,按内存工作集 (Working Set) 大小降序排列,工作集指进程当前使用的物理内存量。
- 右键点击列标题 -> “选择列” (Select columns),可添加更多内存相关列查看:
- 提交大小 (Commit Size): 进程保留的虚拟内存总量(包括物理内存和页面文件)。
- 工作集 (Working Set): 进程当前使用的物理内存量。
- 共享工作集 (Shared WS): 工作集中与其他进程共享的部分。
- 私有工作集 (Private WS): 工作集中该进程独占的部分(通常更贴近进程“独占”内存)。
- 峰值工作集 (Peak WS): 进程生命周期内工作集达到的最大值。
- 按下
-
资源监视器 (Resource Monitor):
- 在任务管理器的 “性能” (Performance) 选项卡底部点击 “打开资源监视器” (Open Resource Monitor),或在开始菜单搜索
resmon。 - 切换到 “内存” (Memory) 选项卡。
- 列表按 “提交 (KB)” 降序排列(默认),点击 “工作集 (KB)” 列标题可按物理内存使用排序。
- 下方提供更详细的物理内存使用分布图(使用中、已修改、备用、可用)和每个进程的内存构成柱状图(硬错误/分页错误率在此查看也很有价值)。
- 在任务管理器的 “性能” (Performance) 选项卡底部点击 “打开资源监视器” (Open Resource Monitor),或在开始菜单搜索
-
PowerShell 命令:灵活查询
- 按工作集排序:
Get-Process | Sort-Object WS -Descending | Select-Object -First 10 Name, Id, WS, PM - 按私有工作集排序:
Get-Process | Sort-Object PrivateMemorySize -Descending | Select-Object -First 10 Name, Id, PrivateMemorySize - 按提交大小排序:
Get-Process | Sort-Object VirtualMemorySize -Descending | Select-Object -First 10 Name, Id, VirtualMemorySize(PM是WorkingSet的别名,WS是WorkingSet64的别名)。
- 按工作集排序:
")
容器环境 (Docker/Kubernetes) 内存查看
-
Docker:
docker stats: 实时显示所有运行中容器的 CPU、内存、网络 I/O、块 I/O 使用率及容器 ID/名称,内存列显示的是容器进程使用的总物理内存量。docker top <container_name_or_id>: 显示容器内运行的进程列表(类似ps),但不会显示容器的内存限制信息。- 进入容器内部:
docker exec -it <container_name_or_id> /bin/bash(或对应容器的 shell),然后在容器内部使用 Linux 的ps,top,htop等工具分析进程内存(需容器内已安装)。
-
Kubernetes:
kubectl top pods: 显示集群中所有 Pod 的 CPU 和内存使用量(需 Metrics Server 已安装并运行)。kubectl top pod <pod_name> -n <namespace>: 查看特定 Pod 的资源使用。kubectl top node: 查看集群节点的资源使用情况。- 进入 Pod 内容器:
kubectl exec -it <pod_name> -c <container_name> -n <namespace> -- /bin/bash,然后在容器内使用 Linux 工具分析。 kubectl describe pod <pod_name> -n <namespace>: 在输出中查找 “Containers” 部分下的容器状态,会显示容器的当前内存使用量 (Memory) 及其限制 (Limits)。
独立见解:超越基础命令的内存分析
- 警惕“共享内存陷阱”: 单纯看
RSS或工作集可能高估了进程的“独占”内存消耗,因为它包含了共享库的内存。PSS (Proportional Set Size) 是更公平的指标(在smem或/proc/PID/smaps中查看),它将共享内存按共享进程数分摊。 - 理解缓存机制: Linux 会利用空闲内存做文件缓存 (
cached/buffers)。free命令中的available值(或/proc/meminfo的MemAvailable)才是判断内存是否真正紧张的关键指标,而非简单的free,应用程序需要内存时,这部分缓存会被内核自动回收。 - 区分内存泄漏与正常使用: 持续增长且无法回收的私有内存 (
Private Dirtyin smaps,Private WSin Windows) 是内存泄漏的典型信号,使用valgrind(开发测试环境)、pmap/smem定期监控、分析/proc/PID/smaps随时间的变化是定位泄漏源的有效手段。 - 容器内存限制的影响: 容器进程看到的是主机内存,但其内存使用受 cgroup 限制,当容器内进程总内存使用接近或超过容器限制时,即使主机内存充足,该容器也可能因 OOM (Out-Of-Memory) 被内核杀死 (
docker inspect看OOMKilled),务必结合cgroup限制 (docker stats,kubectl describe pod) 和容器内进程内存使用综合分析。 - Swap 使用的辩证看待: 少量 Swap 使用未必是问题,但频繁的 Swap In/Out (可从
vmstat 1的si/so或sar -W观察到) 会显著降低性能,表明物理内存严重不足,需优先解决物理内存瓶颈。
专业解决方案:内存瓶颈排查流程
- 快速定位消耗者: 使用
ps aux --sort=-%mem | head(Linux) 或 任务管理器按内存排序 (Windows) 找出排名靠前的进程。 - 分析进程详情:
- Linux: 用
top/htop观察实时变化,用pmap -x PID或cat /proc/PID/smaps查看内存分布细节,用smem查看 PSS/USS。 - Windows: 在任务管理器或资源监视器查看进程的“私有工作集”、“提交大小”及其内存构成图。
- Linux: 用
- 理解系统全局状态: 运行
free -h(Linux) 或查看资源监视器“内存”概览 (Windows),关注available(Linux) / “可用” (Windows) 内存量及 Swap 使用情况。 - 结合应用上下文: 确认高内存进程是否属于预期服务(如数据库、JVM 应用),检查其配置(如 JVM 堆大小
-Xmx)是否合理。 - 判断问题类型:
- 配置不足: 关键服务内存需求超出预期 -> 增加物理内存或调整服务配置。
- 内存泄漏: 进程内存随时间持续增长不释放 -> 使用
valgrind(开发环境)、分析内存快照差异、检查代码或依赖库。 - 低效使用: 存在大量缓存但未有效利用 -> 优化应用算法或数据结构,减少冗余缓存。
- 外部压力: 突增流量或恶意请求 -> 扩容、限流、优化处理逻辑。
- 容器环境需额外关注: 检查容器内存限制 (
docker inspect,kubectl describe pod) 是否设置过低导致 OOMKill,确保 Metrics Server 正常运行以获取 Pod/Node 资源数据。
您最常遇到哪种类型的内存瓶颈?是某个特定应用(如 Java 服务、数据库)的配置调优,还是棘手的内存泄漏排查?欢迎在评论区分享您的实战经验或遇到的挑战! 下一步我们将深入探讨常见服务(MySQL, Redis, JVM)的内存优化策略与高级工具使用技巧。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/26555.html