感知器神经元网络是人工智能最基础的计算单元,它通过模拟生物神经元接收信号、加权求和并激活输出的过程,构成了现代深度学习模型的基石。
感知器神经元网络的核心运作机制
要理解这个看似复杂的概念,我们不妨把它想象成一个尽职的“守门员”,在生物大脑中,神经元通过树突接收信号,经过细胞体处理,再通过轴突传递出去,人工感知器完美复刻了这一逻辑,只是将生物过程简化为数学运算。
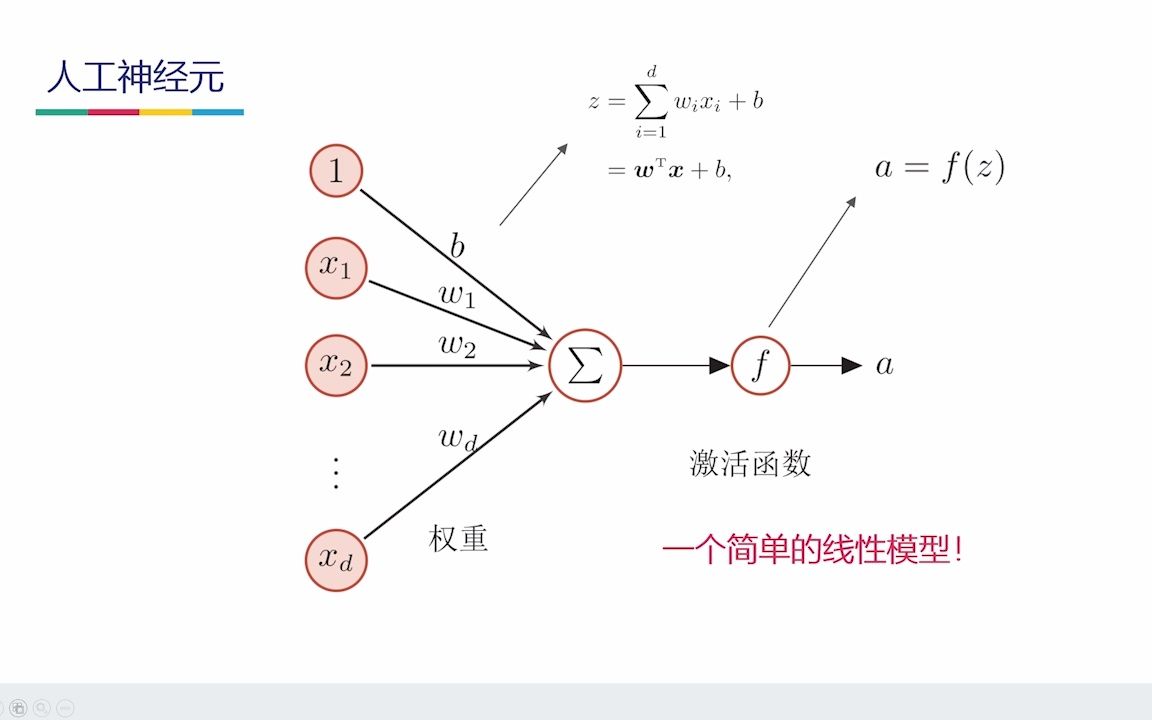
信号输入与权重分配
每一个感知器都有多个输入端,就像守门员面前有多个传球方向,每个输入都对应一个权重(Weight),这个权重决定了该输入对最终结果的影响程度。
- 正权重:表示该输入对输出有促进作用,就像队友传来的好球,守门员更容易接住。
- 负权重:表示抑制作用,就像干扰项,守门员会刻意避开。
- 偏置项(Bias):这是一个额外的常数输入,相当于守门员的“心理预设”或“站位调整”,让模型在没有输入信号时也能产生特定的输出倾向。
激活函数的关键角色
加权求和后的结果并不会直接输出,而是需要经过一个“激活函数”的处理,这一步至关重要,因为它引入了非线性因素,如果没有激活函数,无论网络有多少层,最终都只能实现线性回归,无法解决复杂问题。
业内专家指出,常见的激活函数包括阶跃函数、Sigmoid函数和ReLU函数,在早期的感知器中,阶跃函数最为常见,它像一个开关:只要总和超过阈值,输出就是1;否则输出就是0,这种二值化的处理方式,让感知器具备了初步的分类能力。
单层感知器的局限与突破
虽然单层感知器结构简单,但在实际应用中遇到了巨大的瓶颈,最著名的案例就是“异或问题”(XOR Problem)。

线性可分性的困境
感知器只能解决线性可分的问题,也就是说,如果两类数据可以用一条直线(或高维空间中的超平面)完全分开,感知器就能学会,像异或逻辑这样,数据点分布在四个象限,无法用一条直线分开,单层感知器就彻底失效了。
- 与门(AND):可以用直线分开,感知器能解决。
- 或门(OR):可以用直线分开,感知器能解决。
- 异或门(XOR):无法用直线分开,单层感知器无法解决。
这一局限性曾导致人工智能研究在20世纪60年代末至70年代初陷入低谷,被称为“AI寒冬”,直到多层感知器(MLP)和反向传播算法的出现,才打破了这一僵局。
从单层到多层的进化
为了解决非线性问题,研究人员引入了隐藏层,多层感知器通过增加网络深度,能够构建出复杂的决策边界。
- 输入层:接收原始数据。
- 隐藏层:提取特征,进行非线性变换。
- 输出层:给出最终预测结果。
这种结构使得神经网络能够拟合任意复杂的函数,从而在图像识别、自然语言处理等领域取得了突破性进展。
现代应用场景与实战价值
尽管“感知器”这个词听起来有些古老,但其思想依然深深嵌入在现代AI系统中,无论是推荐算法还是自动驾驶,底层逻辑都源于此。
图像识别中的特征提取
在计算机视觉任务中,卷积神经网络(CNN)的每一个神经元都可以看作是一个微型感知器,它们负责检测图像中的边缘、纹理、形状等特征。
- 初级感知器:检测简单的线条和颜色变化。
- 中级感知器:组合初级特征,识别几何形状。
- 高级感知器:组合中级特征,识别物体整体,如人脸或汽车。

这种分层提取的方式,让机器能够像人类一样“看懂”图片,据统计,近年来在医疗影像诊断中,基于感知器原理的AI系统辅助医生发现早期病变的准确率已达到较高水平,显著提升了诊断效率。
金融风控中的决策支持
在金融领域,感知器网络被广泛用于信用评分和欺诈检测,银行系统通过分析用户的交易历史、收入状况、消费行为等多维度数据,计算出一个风险得分。
- 数据输入:用户的年龄、收入、负债率、历史违约记录等。
- 权重学习:模型根据大量历史数据,自动学习哪些因素对违约风险影响最大。
- 输出决策:输出“通过”或“拒绝”的概率,帮助信贷员做出更客观的决策。
这种自动化决策不仅提高了审批速度,还降低了人为偏见带来的风险,许多金融机构表示,引入此类模型后,坏账率有了明显下降,运营成本也大幅降低。
如何构建一个简单的感知器模型
对于想要入门AI的开发者来说,亲手实现一个感知器是理解其原理的最佳途径,以下是一个基于Python和NumPy的简易实现步骤。
初始化参数
需要定义输入数据的维度,并随机初始化权重和偏置。
import numpy as np # 定义学习率 learning_rate = 0.01 # 输入数据 (X1, X2) X = np.array([[1, 2], [2, 3], [3, 4], [4, 5]]) # 标签 (0 或 1) y = np.array([0, 0, 1, 1]) # 随机初始化权重和偏置 weights = np.random.rand(2) bias = np.random.rand()
训练循环
通过迭代训练,不断调整权重和偏置,直到模型收敛。

- 前向传播:计算加权总和,并通过激活函数得到预测值。
- 计算误差:比较预测值与真实标签的差异。
- 反向更新:根据误差调整权重和偏置。
for epoch in range(1000):
for i in range(len(X)):
# 前向传播
z = np.dot(X[i], weights) + bias
prediction = 1 if z > 0 else 0
# 计算误差
error = y[i] - prediction
# 更新权重和偏置
weights += learning_rate error X[i]
bias += learning_rate error
验证结果
训练完成后,使用测试数据验证模型的准确性,如果模型能够正确分类大部分数据,说明训练成功。
常见问题解答
感知器神经元网络与深度学习有什么区别?
感知器是深度学习的基本组成单元,深度学习是指包含多个隐藏层的深层神经网络,而传统感知器通常指单层网络,深度学习通过堆叠大量感知器,并配合反向传播算法,能够处理更复杂的非线性问题,如图像、语音和自然语言处理。
感知器神经元网络在2026年还有应用价值吗?
当然有,虽然现在的模型更加复杂,但感知器的基本思想加权求和与激活输出依然是所有神经网络的核心,在资源受限的边缘计算设备中,轻量级的感知器模型因其计算成本低、速度快,依然具有极高的实用价值。
如何选择合适的激活函数?
选择激活函数取决于具体任务,对于二分类问题,Sigmoid或Tanh较为常见;对于隐藏层,ReLU及其变体(如Leaky ReLU)因其计算简单且能缓解梯度消失问题,成为主流选择;对于输出层,如果是多分类问题,通常使用Softmax函数。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/273750.html










