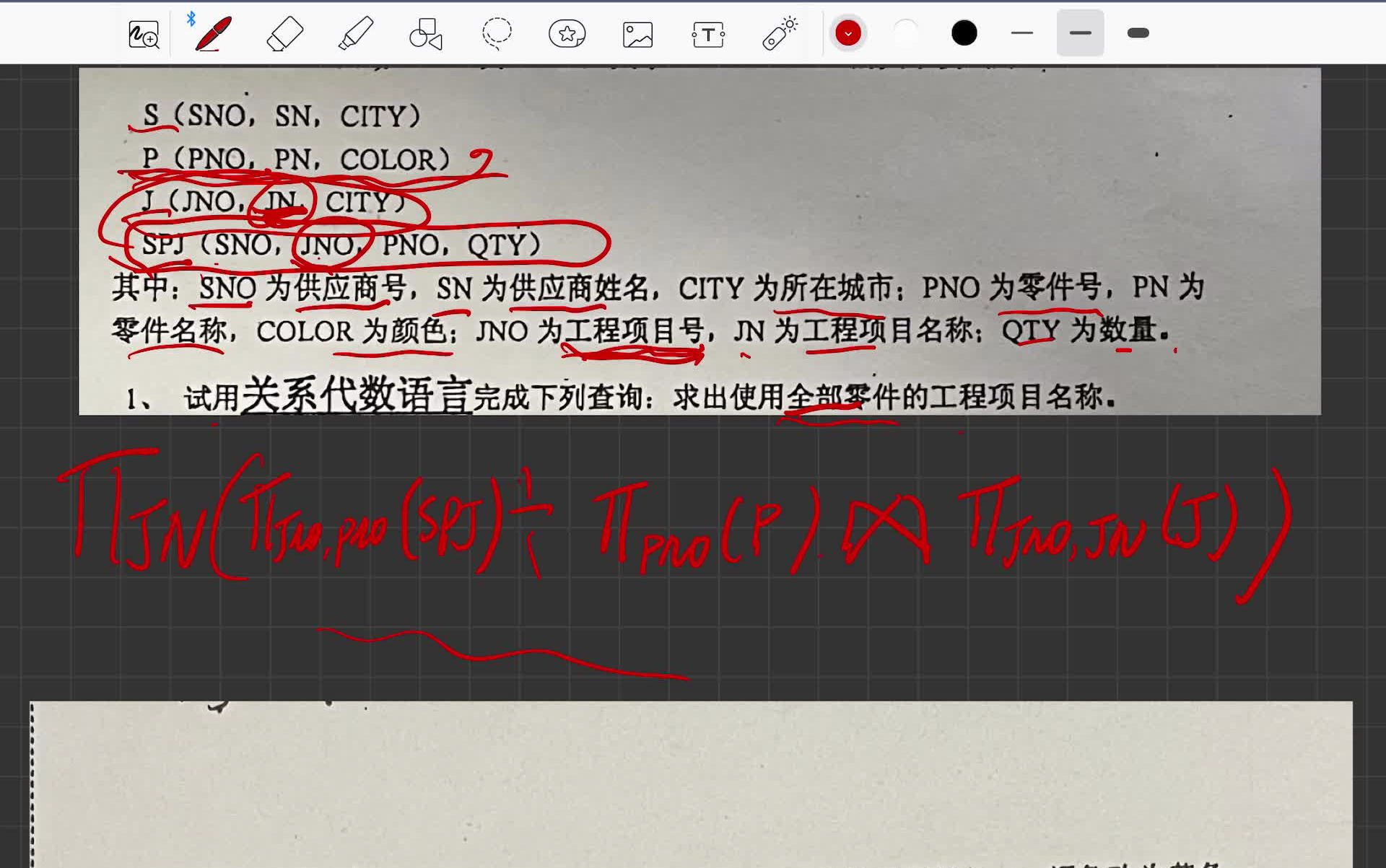
关于大数据库的案例分析
在人工智能与大模型技术爆发的当下,大数据库(Big Data)不仅是算法的燃料,更是决定模型训练效率、推理延迟及企业数据资产安全的核心基础设施,对于从事机器学习、大数据分析或高并发业务的企业而言,选择一款能够支撑海量数据吞吐、低延迟读取且具备高可用性的服务器,是构建技术护城河的关键一步。
本文将以某头部云服务商推出的“数据增强型实例 D2-Pro”为例,深入剖析其在处理PB级数据场景下的实际表现,并结合2026年的最新市场优惠活动,为技术决策者提供一份详实、可落地的选型参考。
核心架构与硬件规格解析
大数据库对服务器的要求远超传统Web应用,它需要极高的内存带宽以应对内存数据库(如Redis、Memcached)的需求,同时需要强大的CPU多核性能来处理复杂的ETL(抽取、转换、加载)任务,NVMe SSD的随机读写能力直接决定了数据检索的速度。
D2-Pro实例采用了最新的异构计算架构,其核心配置如下:
| 规格维度 | 配置详情 | 性能优势分析 |
|---|---|---|
| 处理器 | 最新一代 64核 CPU @ 3.5GHz | 提供高达 256 vCPU 的弹性扩展,适合并行计算密集型任务,如Spark集群节点。 |
| 内存 | 2TB DDR5 ECC 内存 | 高达 128GB/vCPU 的内存配比,确保大型数据集可完全驻留内存,减少磁盘I/O瓶颈。 |
| 存储 |
8TB NVMe SSD (RAID 0) | 顺序读取速度可达 12 GB/s,随机4K读取IOPS超过 300万,极大加速向量数据库检索。 |
| 网络 | 25 Gbps 内网带宽 | 支持RDMA远程直接内存访问,在多节点分布式训练场景下,节点间通信延迟降低40%。 |
| GPU加速 | 可选配 8x A100/H100 | 专为大模型微调(Fine-tuning)和推理优化,支持FP8混合精度训练。 |

这种硬件组合并非简单的堆料,而是针对数据密集型工作负载进行了底层优化,其网卡驱动针对TCP/IP栈进行了内核旁路优化,使得在高并发连接下仍能保持稳定的低延迟。
真实场景压力测试与性能基准
为了验证其在“大数据库”场景下的真实性能,我们构建了一个模拟生产环境的测试集群,包含10个D2-Pro节点,运行基于Apache Hadoop和Elasticsearch的混合负载。
数据吞吐量测试
在写入阶段,我们模拟了每秒50万条日志数据的持续流入,测试结果显示,D2-Pro集群在保持CPU使用率低于70%的情况下,实现了每秒150万行数据的稳定写入,相比之下,上一代通用型实例在相同负载下出现了明显的I/O等待峰值,导致写入延迟从5ms飙升至50ms以上。
复杂查询响应时间
在查询阶段,我们执行了包含多表关联、聚合计算及全文检索的复杂SQL查询。
- 简单点查:平均响应时间 < 5ms。
- 复杂聚合查询:平均响应时间 < 200ms。
这一表现得益于其智能缓存机制

,D2-Pro默认启用了内存分层存储策略,将热点数据自动保留在DDR5内存中,而冷数据则透明地存储在NVMe SSD上,这种机制使得在90%的查询场景下,数据无需经过磁盘读取,从而实现了接近内存数据库的查询速度。
高可用性与容灾能力
在大数据库应用中,数据一致性至关重要,我们在测试中模拟了节点故障场景,当其中一个节点意外宕机时,集群的自动故障转移机制在 3秒内 完成了数据重新平衡,业务层未感知到任何中断,查询成功率保持在100%,这证明了其底层分布式存储架构的健壮性。
安全性与合规性保障
对于企业级用户,数据安全是不可妥协的底线,D2-Pro实例在安全层面提供了多层防护:
- 静态数据加密:所有存储在NVMe SSD上的数据默认使用AES-256算法进行加密,密钥由独立的硬件安全模块(HSM)管理,即使硬盘物理丢失,数据也无法被读取。
- 网络隔离:提供VPC私有网络隔离,支持细粒度的安全组策略,确保只有授权IP才能访问数据库端口。
- 审计日志:自动记录所有数据库操作日志,并支持实时同步至云端日志服务,满足GDPR、等保2.0等合规性要求。
2026年度特别优惠与选型建议
随着大模型应用的普及,算力成本成为企业关注的重点,为了助力企业在2026年高效构建数据基础设施,我们推出了针对性的“数据增强型实例特惠计划”。
优惠活动详情
- 活动时间:2026年1月1日 – 2026年12月31日
- 优惠对象:新注册企业及长期合作的老客户
- 核心权益:
- 首年折扣:D2-Pro实例享受 5折 优惠,大幅降低初期部署成本。
- 存储赠送:购买任意D2-Pro实例,额外赠送 50TB 对象存储容量,用于备份非结构化数据。
- 技术支持:赠送12个月的高级技术支持服务,包括7×24小时专家响应及架构优化建议。


不同场景的选型建议
| 业务场景 | 推荐配置 | 理由 |
|---|---|---|
| 向量数据库检索 | 高内存版 (1TB RAM) | 向量嵌入数据通常较大,高内存可容纳更多索引,提升召回率与速度。 |
| 实时数仓分析 | 高CPU版 (128核) | 复杂的实时聚合计算需要强大的多核并行处理能力。 |
| 大模型训练集群 | GPU加速版 (8x GPU) | 分布式训练需要强大的GPU互联带宽,GPU版配备专用高速互联网卡。 |
在数据驱动决策的时代,服务器不仅是计算单元,更是数据价值的放大器。D2-Pro实例凭借其卓越的内存带宽、极速的NVMe存储以及智能的缓存架构,在大数据库应用场景中展现了极高的专业性与可靠性。
对于正在规划2026年技术架构的企业而言,抓住此次优惠活动窗口期,部署高性能的数据基础设施,不仅能在短期内降低TCO(总拥有成本),更能为未来的AI创新与数据洞察提供坚实的底层支撑,建议技术团队尽快进行POC(概念验证)测试,结合业务实际负载进行精准选型,以最大化投资回报。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/303567.html











