AlexNet是2012年ILSVRC竞赛的冠军模型,它通过引入ReLU激活函数、Dropout正则化及数据增强技术,彻底改变了深度学习在图像识别领域的格局,确立了卷积神经网络(CNN)的主流地位。
提到深度学习,很多人脑海中首先浮现的可能是如今庞大的Transformer架构或复杂的生成式AI,但在2026年的今天,当我们回溯技术演进的脉络,AlexNet依然是一座不可逾越的里程碑,它不仅仅是一个网络结构,更是现代计算机视觉的“原点”,理解它,就是理解AI如何从“只能看”进化到“看懂”的关键一步。
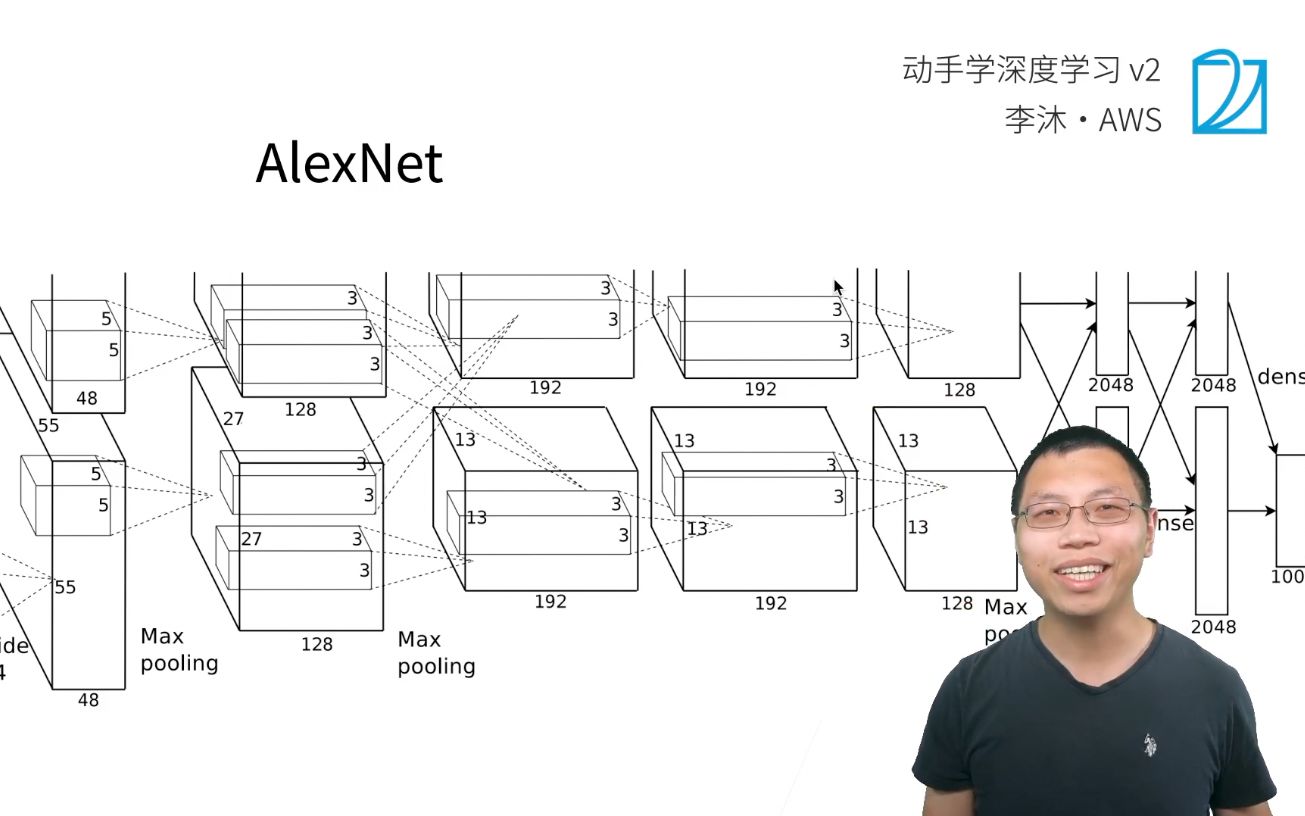
AlexNet网络结构详解:从LeNet到深度卷积的跨越
AlexNet由Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton在2012年提出,在那个GPU算力尚不充裕的年代,他们大胆地设计了一个拥有8层可学习层的深度网络,这种架构设计直接解决了当时浅层网络难以提取高层语义特征的问题。
核心架构拆解:卷积层与全连接层的配合
AlexNet的整体结构可以分为两个主要部分:卷积部分和全连接部分,这种设计思路后来成为了许多经典CNN的标配。
卷积层:特征提取的主力军
卷积层是AlexNet的核心,负责从原始像素中提取特征,它包含5个卷积层,其中前3层后面紧跟最大池化层(Max Pooling),后2层后面直接连接全连接层。
- 第一层卷积:输入图像尺寸为227x227x3,使用96个大小为11×11、步长为4的滤波器,这一层的主要目的是捕捉图像的低级特征,如边缘和纹理,由于步长较大,输出特征图尺寸迅速减小为55x55x96。
- 第二层卷积:输入来自第一层的池化结果,尺寸为27x27x96,使用256个大小为5×5、步长为1的滤波器,这一层开始捕捉更复杂的局部模式。
- 第三、四、五层卷积:这三层紧密相连,滤波器大小均为3×3,步长为1,它们用于提取更高级、更抽象的特征,如物体的部件或整体形状。
业内专家指出,这种“大核浅层+小核深层”的组合,在保证感受野的同时,极大地增加了网络的非线性表达能力。

全连接层:分类决策的大脑
经过5层卷积和3层池化后,特征图被展平为一维向量,输入到3个全连接层中。
- 第六、七层:每个全连接层包含4096个神经元,这两个层的主要作用是将提取到的分布式特征映射到样本标记空间。
- 第八层(输出层):包含1000个神经元,对应ImageNet数据集的1000个类别,使用Softmax函数将输出转化为概率分布,最终预测出图像所属的类别。
AlexNet为何能赢?三大关键技术突破
如果仅仅增加网络深度,AlexNet可能早已被梯度消失问题击垮,它之所以能在2012年的ILSVRC竞赛中以巨大优势夺冠,得益于三个关键的技术创新,这些创新至今仍是训练深度网络的基石。
ReLU激活函数:解决梯度消失的利器
在AlexNet之前,Sigmoid或Tanh是主流的激活函数,当网络变深时,这些函数的梯度在饱和区趋近于零,导致反向传播时梯度消失,网络无法有效训练。
AlexNet引入了ReLU(Rectified Linear Unit)激活函数,其公式为$f(x) = max(0, x)$,ReLU的优势在于:
- 计算简单:只需判断正负,无需复杂的指数运算,大幅加快了训练速度。
- 缓解梯度消失:在正区间梯度恒为1,使得深层网络也能有效更新权重。
- 稀疏激活性:负值输出为0,使网络具有稀疏性,提高了模型的泛化能力。
Dropout正则化:防止过拟合的“杀手锏”
AlexNet拥有超过6000万个参数,极易发生过拟合,为了解决这个问题,作者在两个全连接层之后引入了Dropout技术。
在训练过程中,Dropout以一定的概率(如0.5)随机“丢弃”一部分神经元,即暂时将其输出置零,这意味着每次迭代时,网络都在训练一个不同的“子网络”,到了测试阶段,再恢复所有神经元,并将权重乘以保留概率。

这种做法相当于对多个模型进行集成学习,显著提高了模型的鲁棒性,据行业共识认为,Dropout的引入使得AlexNet能够在数据量有限的情况下,依然保持极高的准确率。
数据增强与GPU并行:工程上的极致优化
AlexNet不仅在算法上创新,在工程实现上也做到了极致。
- 数据增强:通过对训练图像进行随机裁剪、水平翻转、颜色变换等操作,人为扩充了数据集,这不仅增加了数据多样性,还有效防止了模型对特定特征的过度依赖。
- GPU并行训练:受限于当时的硬件,AlexNet将网络拆分到两块GPU上并行训练,这种设计不仅加快了训练速度,还减少了单块GPU显存的占用压力。
AlexNet与后续模型的对比:历史定位与局限性
虽然AlexNet是开创者,但它并非完美,了解它的局限性,有助于我们更好地理解后续VGG、ResNet等模型的发展逻辑。
参数量与计算成本
AlexNet拥有约6000万个参数,其中前两个全连接层就占据了大部分,相比之下,后来的VGGNet虽然结构更规整,但参数量更大;而ResNet通过残差连接,在增加深度的同时控制了参数增长。
在2026年的今天,我们使用轻量级模型如MobileNet或EfficientNet,参数量仅为AlexNet的几分之一,却能实现更高的精度和更快的推理速度。
感受野与局部连接
AlexNet的卷积核大小从11×11逐渐减小到3×3,虽然这有助于提取多尺度特征,但相比于后续模型广泛使用的3×3小卷积核堆叠,AlexNet在局部特征提取的细腻程度上略显不足。
池化策略
AlexNet主要使用最大池化(Max Pooling),它保留了最显著的特征,但丢失了位置信息,后续模型引入了平均池化(Average Pooling)或全局平均池化(Global Average Pooling),在保留更多信息的同时,减少了全连接层的参数数量。
实操指南:如何在现代框架中复现AlexNet

对于开发者而言,复现AlexNet不仅是学习历史,更是理解深度学习底层逻辑的最佳实践,以下是在PyTorch框架中实现AlexNet核心模块的步骤。
环境准备与依赖安装
确保你的开发环境已安装PyTorch和Torchvision,建议使用Python 3.8及以上版本,以获得最佳的性能和兼容性。
代码实现核心逻辑
你可以参考以下代码结构来构建AlexNet的基本骨架:
- 定义卷积块:创建一个包含卷积、Batch Normalization、ReLU和最大池化的模块。
- 构建网络主体:按照AlexNet的结构,依次添加5个卷积块,注意调整卷积核大小、步长和填充。
- 添加全连接层:在卷积部分之后,展平特征图,并添加两个4096维的全连接层,中间插入Dropout层。
- 定义输出层:添加一个1000维的全连接层作为输出,并应用Softmax激活函数。
训练与评估
使用ImageNet数据集进行训练,由于AlexNet较老,建议使用学习率预热和余弦退火策略来优化收敛效果,在评估阶段,注意检查模型的Top-1和Top-5准确率,以全面评估其性能。
Q&A:关于AlexNet的常见疑问
AlexNet网络结构详解中,为什么选择ReLU而不是Sigmoid?
ReLU在正区间的梯度恒为1,有效避免了深层网络中的梯度消失问题,同时计算效率远高于Sigmoid,Sigmoid在饱和区梯度趋近于0,导致深层网络难以训练。
AlexNet与VGGNet的主要区别是什么?
AlexNet使用较大的卷积核(如11×11, 5×5)和较大的步长,结构较为灵活;而VGGNet统一使用3×3的小卷积核和2×2的池化核,结构更规整,参数量更大,但推理速度更慢。
AlexNet在现代应用中还有使用价值吗?
AlexNet本身因参数量大、效率低,已不再直接用于生产环境,但其设计理念,如ReLU、Dropout和数据增强,已成为所有现代深度学习模型的标配,具有极高的教学和参考价值。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/304568.html











