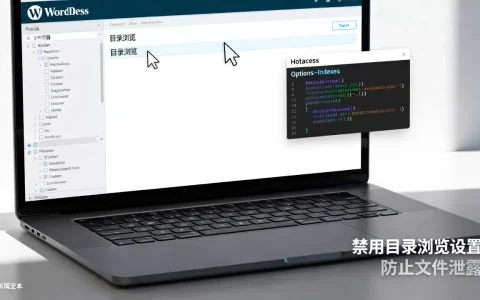
互联网云网络维护的核心在于构建自动化监控体系与标准化应急响应流程,通过“预防优于修复”的策略将故障影响降至最低,确保业务连续性。
云网络不再是简单的物理线路连接,而是由虚拟化软件定义网络(SDN)构成的复杂生态系统,对于企业而言,云网络的稳定性直接决定了业务的生命线,许多团队在初期往往忽视底层架构的韧性,直到流量洪峰或突发攻击导致服务中断,才意识到维护工作的重要性,真正的云网络维护,不是等出了问题去修,而是通过数据驱动的方式,提前发现隐患并自动修复。
云网络维护的核心挑战与认知误区
业内专家指出,当前企业在云网络维护中最大的痛点并非技术匮乏,而是认知偏差,传统运维思维习惯于“救火”,而云原生环境要求的是“防火”,这种思维转变需要从被动响应转向主动治理。
从被动响应到主动治理的转变
过去,网络工程师主要关注物理设备的指示灯状态和端口流量,云环境中的网络拓扑是动态变化的,虚拟机可能在毫秒级内迁移或销毁,如果仍依赖人工巡检,必然会出现监控盲区。
- 动态拓扑感知缺失:传统工具无法实时追踪云实例的生命周期,导致安全策略滞后。
- 配置漂移风险:云资源的弹性伸缩特性使得配置容易在自动化过程中发生非预期变更,引发网络连通性问题。
- 可见性不足:在微服务架构下,服务间调用链路复杂,缺乏全链路追踪能力,难以定位具体的网络瓶颈。
常见维护误区解析
许多团队认为购买了云服务就万事大吉,这种想法极其危险,云服务商负责的是底层基础设施的可用性,而应用层的网络配置、安全组策略、负载均衡规则等,完全属于客户责任共担模型中的客户侧。
- 过度依赖默认配置:云厂商提供的默认网络设置通常偏向开放,缺乏最小权限原则,极易成为攻击入口。
- 忽视日志分析:许多企业开通了云网络日志服务,但从未定期查看,导致故障发生时缺乏关键排查依据。
- 测试环境与实际环境脱节:开发测试环境的网络配置与生产环境差异巨大,导致上线后出现兼容性问题。

构建自动化监控与预警体系
要实现高效的云网络维护,必须建立一套覆盖全链路的监控体系,这不仅仅是监控带宽利用率,更要深入到协议层和应用层的交互细节。
关键性能指标(KPI)的选取
监控指标的选取应遵循“业务相关”原则,单纯的CPU或内存使用率并不能直接反映网络健康度。
- 网络吞吐量与丢包率:这是最基础的指标,但需结合业务峰值进行基线对比,而非设定固定阈值。
- 连接建立时间(TCP Handshake Time):反映网络延迟和服务器响应能力,直接影响用户体验。
- DNS解析成功率与耗时:DNS故障常被忽视,但却是导致服务不可用的常见原因。
- HTTP状态码分布:通过监控5xx错误比例,快速定位后端服务或负载均衡器的异常。
自动化告警策略优化
告警风暴是运维人员的噩梦,过多的无效告警会导致“狼来了”效应,使关键故障被淹没。
- 分级告警机制:将告警分为P0(紧急)、P1(高)、P2(中)、P3(低)四个等级,分别对应电话、短信、邮件和站内信通知。
- 告警收敛与抑制:利用智能算法,将同一根因引发的多条告警合并为一条,避免重复打扰。
- 动态阈值调整:根据历史数据自动调整告警阈值,适应业务季节性波动,减少误报。
标准化应急响应与故障排查流程
当故障发生时,速度就是金钱,建立标准化的应急响应流程(SOP),可以确保在高压环境下依然保持冷静和高效。
故障分级与响应机制
不同级别的故障需要不同层级的响应,明确界定故障等级,有助于合理分配资源。
- P0级故障:核心业务完全中断,影响所有用户,需在15分钟内响应,1小时内恢复或提供临时解决方案。
- P1级故障:核心业务部分功能受损,或大量用户受影响,需在30分钟内响应,4小时内解决。
- P2级故障:非核心业务受影响,或少数用户遇到问题,需在2小时内响应,24小时内解决。
- P3级故障:轻微体验问题或配置错误,需在下一个工作日处理。

实战排查路径示例
面对云网络故障,建议遵循“由外到内、由简到繁”的排查路径。
- 确认故障范围:通过外部探测工具(如Ping、Traceroute)判断是全局性问题还是局部问题。
- 检查云控制台:查看云服务商提供的健康状态报告,确认底层基础设施是否正常。
- 验证安全组与ACL:检查入站和出站规则是否误拦截了正常流量,这是最常见的配置错误。
- 分析负载均衡器:检查后端健康检查状态,确认是否有服务器节点被标记为不健康。
- 深入应用层:使用日志分析工具,查看应用服务器的错误日志,定位具体代码或依赖问题。
云网络维护的成本优化与地域策略
在保障稳定性的同时,控制成本是云运维的另一大核心目标,不同地域的网络延迟和带宽价格差异巨大,合理的架构设计可以显著降低成本。
跨地域容灾与成本平衡
对于高可用性要求极高的业务,跨地域部署是必要选择,但如何平衡成本与可用性,需要精细化的策略。
- 主备模式 vs 双活模式:主备模式成本低,但切换时间长;双活模式成本高,但切换迅速,可根据业务容忍度选择。
- CDN加速与边缘节点:利用CDN将静态内容分发到离用户更近的边缘节点,不仅降低源站压力,还减少了跨区域流量费用。
- 预留实例与竞价实例组合:对于基础网络组件,使用预留实例锁定低价;对于弹性需求大的组件,使用竞价实例降低成本。
地域选择对网络性能的影响
用户分布决定了服务器部署的最佳位置。

| 用户分布区域 | 推荐部署策略 | 预期延迟效果 | 成本影响 |
|---|---|---|---|
| 集中在单一省份 | 本地可用区部署 | < 10ms | 最低 |
| 全国分散 | 多可用区+CDN | 20-50ms | 中等 |
| 全球用户 | 全球加速+多地域节点 | 50-100ms | 较高 |
据工信部数据,近年来云网络流量呈现爆发式增长,跨区域数据传输成本已成为企业云支出的重要组成部分,优化数据流向,减少不必要的跨区流量,是成本控制的关键。
常见问题解答(Q&A)
云网络维护中如何处理突发流量洪峰?
处理突发流量洪峰的核心在于弹性伸缩与流量整形,配置自动伸缩组(Auto Scaling),根据CPU使用率或网络流量阈值自动增加实例数量,启用DDoS防护服务,清洗恶意流量,实施流量整形策略,对非核心业务进行限流,确保核心业务资源充足。
云网络维护的预算如何合理分配?
合理的预算分配应遵循“重预防、轻补救”的原则,建议将40%的预算用于自动化监控工具和安全防护,30%用于定期演练和人员培训,20%用于基础设施升级,剩余10%作为应急备用金,这种分配方式能最大程度降低故障带来的隐性损失。
如何选择适合企业的云网络维护服务商?
选择服务商时,应重点考察其自动化能力、应急响应速度和服务透明度,要求服务商提供详细的SLA(服务等级协议)承诺,并查看其过往的故障处理案例,优先选择具备自有监控平台和自动化工具链的服务商,避免过度依赖人工操作。
首发原创文章,作者:世雄 - 原生数据库架构专家,如若转载,请注明出处:https://idctop.com/article/322409.html