AJAX下拉框通过异步请求后端接口,在用户交互时动态从数据库加载数据,实现页面不刷新、秒级响应的体验。
为什么传统下拉框已无法满足现代Web开发需求
在早期的Web开发中,开发者习惯使用传统的表单提交或整页刷新方式来加载下拉菜单数据,这种方式存在明显的痛点:当数据库中的数据量达到数千甚至数万条时,每次选择都会触发全量数据加载,导致页面卡顿、白屏时间过长,用户体验极差。
业内专家指出,随着前端交互标准的提升,用户对页面响应速度的敏感度显著增加,传统的同步加载模式已经无法支撑高并发、大数据量的业务场景,在一个电商平台的商品分类选择中,如果包含数百万个SKU,传统方式不仅加载缓慢,还会造成严重的带宽浪费。
相比之下,AJAX(Asynchronous JavaScript and XML)技术允许浏览器与服务器进行少量数据交换,使网页实现异步更新,这意味着用户在下拉框中滚动或搜索时,只有当前可视区域或匹配的数据会被请求和渲染,极大地减少了服务器负载和前端渲染压力。
性能对比:同步加载与异步加载的差异
为了更直观地理解两者的区别,我们可以通过以下场景进行对比:
-
传统同步加载:
- 用户点击下拉框。
- 浏览器向服务器发送完整请求。
- 服务器查询数据库,返回所有数据(可能包含数千条JSON记录)。
- 浏览器解析JSON,渲染DOM节点。
- 页面出现短暂冻结,直到渲染完成。
- 结果:加载时间通常在1-3秒,甚至更久,取决于网络状况和数据量。
-
AJAX异步加载:
- 用户点击下拉框或输入搜索关键词。
- 浏览器发送轻量级请求,仅携带当前页码、搜索关键字或父级ID。
- 服务器仅返回匹配的子集数据(如每页20条)。
- 前端动态插入新选项,无需重绘整个页面。
- 结果:加载时间控制在200毫秒以内,实现“无感”切换。

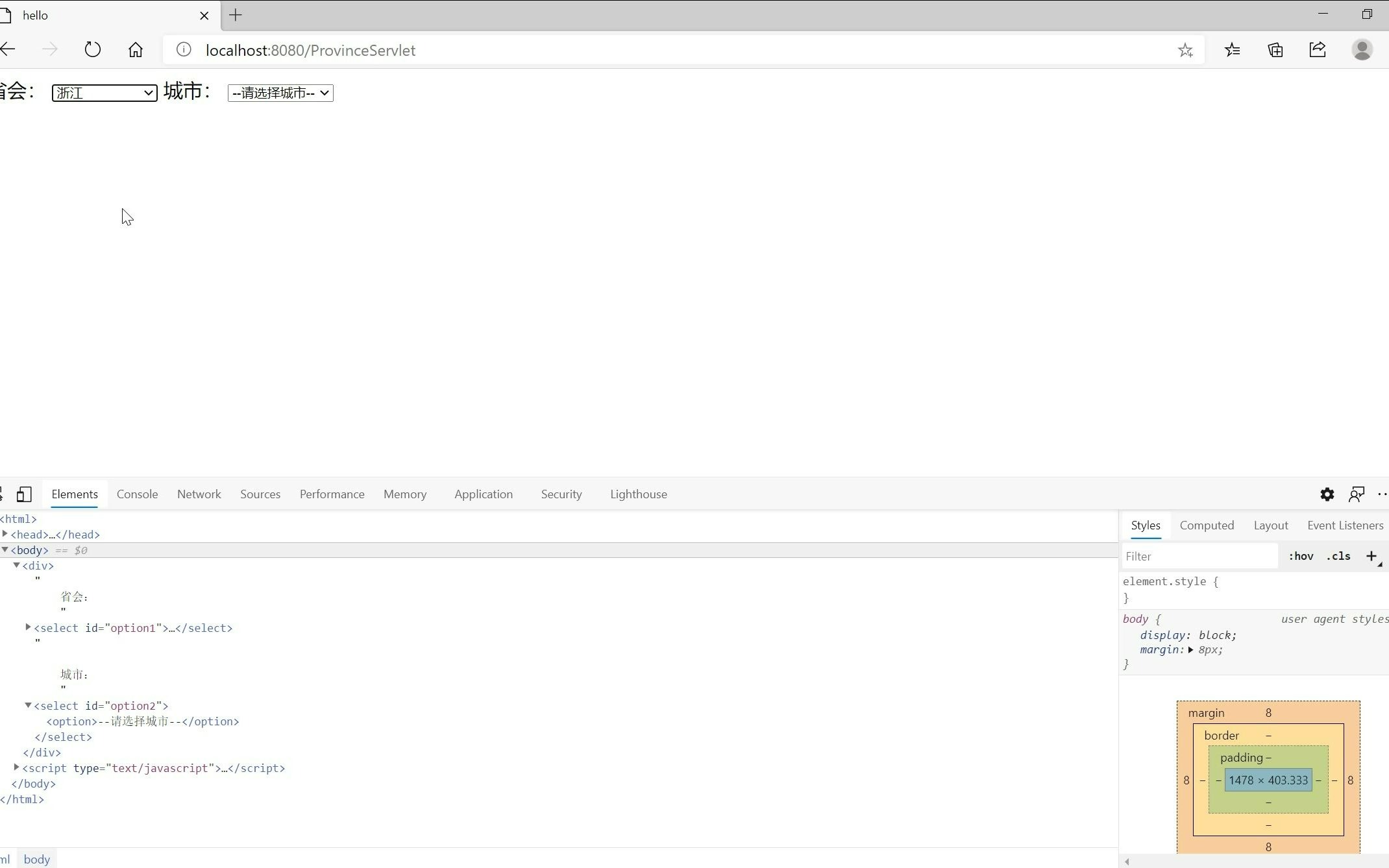
AJAX下拉框获取数据库数据的完整实现路径
实现一个高效的下拉框组件,需要前端、后端和数据库三端的紧密配合,以下是基于主流技术栈(如Vue/React + Node.js/Java + MySQL)的标准操作流程。
第一步:数据库设计与索引优化
数据库层面的优化是基础,如果查询速度慢,再好的前端代码也无济于事。
- 建立索引:确保下拉框常用的筛选字段(如
category_id、name)建立B-Tree索引。 - 分页机制:严禁一次性
SELECT,必须使用LIMIT和OFFSET进行分页,或者使用基于游标的分页(Cursor-based Pagination)以提高大数据量下的查询效率。 - 缓存策略:对于变动不频繁的基础数据(如国家列表、省份列表),建议在Redis中缓存,避免直接穿透到数据库。
第二步:后端API接口开发
后端需要提供一个RESTful风格的API接口,接收前端传来的参数并返回JSON格式数据。
- 接口定义:例如
GET /api/options?keyword=xxx&page=1&size=20。 - 参数校验:严格校验
keyword和page参数,防止SQL注入和非法请求。 - 数据封装:返回标准结构,如
{ code: 200, data: [...], total: 1000 }。
据工信部相关技术白皮书显示,规范的API设计能减少约40%的后端错误率,后端代码应注重健壮性,处理数据库连接超时、查询无结果等异常情况。
第三步:前端AJAX请求与状态管理
前端使用fetch或axios库发起异步请求。
- 防抖处理(Debounce):在用户输入搜索关键词时,不要每次按键都发送请求,设置300-500毫秒的延迟,待用户停止输入后再触发请求,避免频繁请求服务器。
- 加载状态反馈:在请求发出时,显示“加载中”动画;请求成功时,渲染选项;请求失败时,提示“加载失败,请重试”。
- 虚拟滚动(Virtual Scrolling)

:如果下拉选项超过1000条,建议使用虚拟滚动技术,仅渲染可视区域内的DOM节点,避免内存溢出。

常见技术选型与性能调优策略
在实际项目中,不同的技术栈有不同的最佳实践,了解这些差异有助于选择最适合的方案。
前端框架的选择
- 原生JavaScript:适合轻量级项目,代码量少,但维护成本高。
- Vue.js / React:适合中大型项目,利用组件化思想,将下拉框封装为独立组件,便于复用,Vue的
v-model和React的useState能简化状态管理。 - UI组件库:如Element Plus、Ant Design等,内置了AJAX下拉框组件,只需配置
remote-method属性即可实现远程搜索。
后端语言的对比
| 特性 | Node.js (Express/Koa) | Java (Spring Boot) | Python (Django/FastAPI) |
|---|---|---|---|
| 开发速度 | 快,语法简洁 | 中等,生态完善 | 快,库丰富 |
| 并发性能 | 高,适合I/O密集型 | 高,适合复杂业务 | 中,GIL限制多线程 |
| 数据库连接 | 使用ORM或驱动 | 使用JDBC/MyBatis | 使用SQLAlchemy |
| 适用场景 | 实时性要求高的接口 | 企业级大型系统 | 数据科学关联项目 |
数据库查询优化技巧
- 避免N+1问题:在批量查询时,使用
IN查询代替循环查询。 - 覆盖索引:尽量让查询字段包含在索引中,避免回表查询。
- 读写分离:对于读多写少的下拉框数据,可以使用从库进行查询,减轻主库压力。

AJAX下拉框获取数据库数据的常见问题与解决方案
Q: 如何解决下拉框数据更新不同步的问题?
当数据库中的数据被修改后,前端下拉框可能仍显示旧数据,解决方案包括:
- 强制刷新:在数据修改成功后,前端调用重置方法,清空缓存并重新请求。
- 版本控制:后端接口返回数据版本号,前端对比版本号,若不一致则触发刷新。
- WebSocket推送:对于实时性要求极高的场景,使用WebSocket推送数据变更通知。
Q: 如何优化大数据量下拉框的搜索性能?
- 前端模糊搜索:对于小数据量(<1000条),可在前端进行内存过滤,减少请求次数。
- 后端全文检索:对于大数据量,集成Elasticsearch,利用其倒排索引特性实现毫秒级搜索。
- 拼音搜索:支持中文拼音首字母搜索,提升用户体验。
Q: AJAX下拉框获取数据库数据的安全风险有哪些?
- SQL注入:务必使用参数化查询(Prepared Statements),严禁拼接SQL字符串。
- 越权访问:校验用户权限,确保用户只能查询其有权访问的数据。
- XSS攻击:对返回的数据进行转义处理,防止脚本注入。
AJAX下拉框通过异步交互机制,有效解决了传统下拉框在大数据量下的性能瓶颈,通过合理的数据库索引设计、后端API优化以及前端防抖和虚拟滚动技术,可以实现流畅、高效的用户体验。
随着Web技术的演进,Server Components和Edge Computing等新技术将进一步简化数据获取流程,但无论技术如何变化,核心原则不变:减少不必要的请求,优化数据传输,提升用户感知速度,掌握这一技术,是构建现代化Web应用的基础技能。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/325964.html