在2026年的AI音箱市场中,基于YOLOv3优化的物体检测技术已成为提升智能家居交互效率的关键,它让设备能更精准地识别用户意图并执行控制指令,从而显著改善用户体验。
随着智能硬件市场的成熟,用户不再满足于简单的语音开关灯,而是期待设备具备“看懂”环境的能力,AI音箱作为家庭入口,其核心竞争力的转移正从单纯的语音识别转向多模态感知,YOLOv3虽然发布多年,但在边缘计算设备上的轻量化改造使其依然具有极高的实用价值,特别是在对实时性要求极高的场景下。
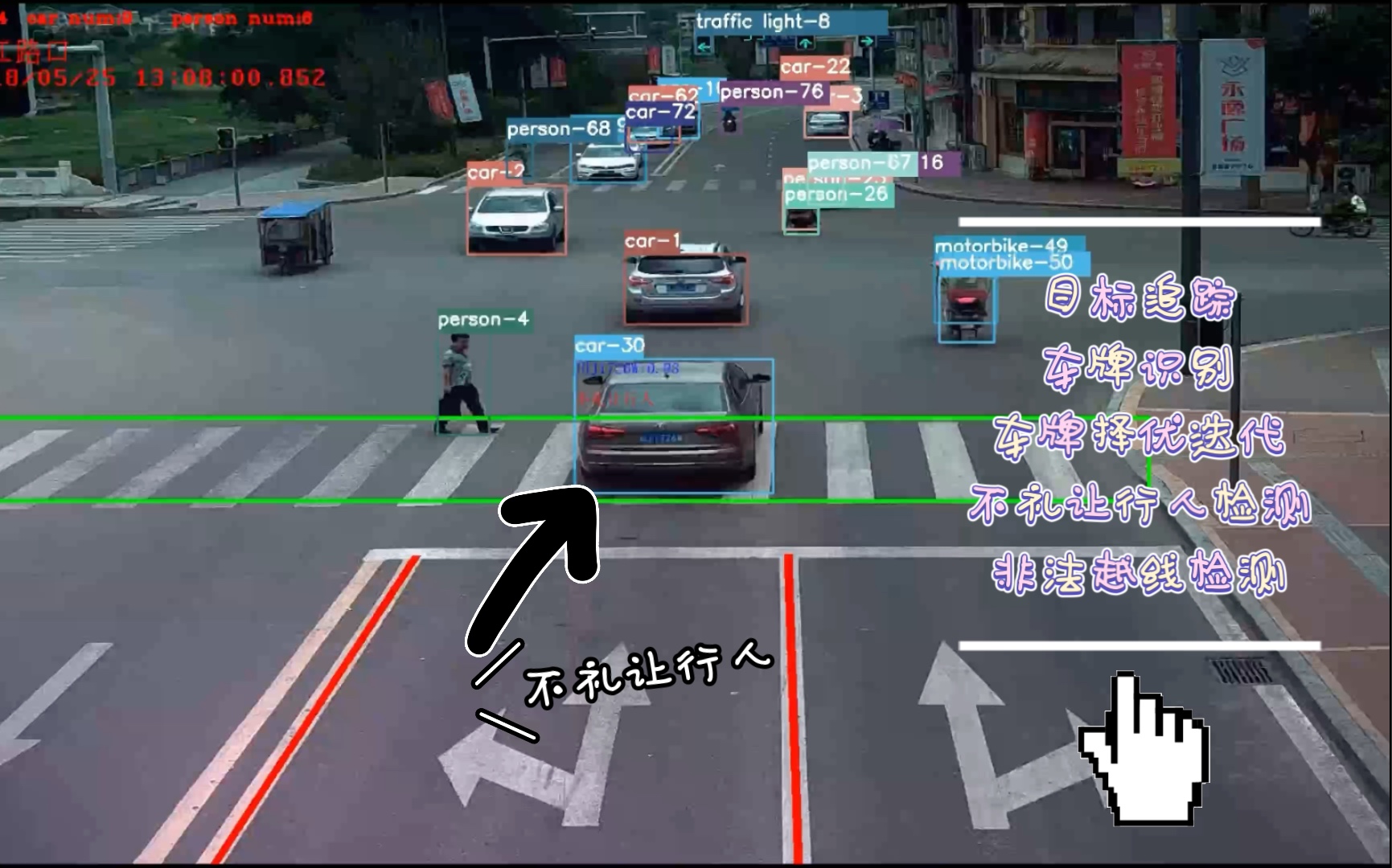
AI音箱市场现状与YOLOv3的技术适配性
当前的AI音箱市场呈现出明显的两极分化趋势,高端市场追求多模态融合,而中低端市场则更看重成本与功耗的平衡,业内专家指出,YOLOv3在算力受限的嵌入式芯片上,依然保持着良好的精度与速度平衡,这使其成为许多厂商在2026年依然选择的技术底座之一。
为什么选择YOLOv3而非最新模型?
尽管YOLOv5、v8甚至v10相继问世,但在AI音箱这类资源受限的设备上,新模型往往面临部署难题。
- 算力限制:大多数入门级AI音箱搭载的是低功耗ARM架构处理器,无法支撑大参数模型的实时推理。
- 延迟敏感:智能家居控制要求毫秒级响应,YOLOv3经过量化和剪枝后,推理速度足以满足日常交互需求。
- 开发成本:成熟的开源生态意味着更低的适配成本和更丰富的预训练模型资源。
边缘计算下的性能优化路径
要让YOLOv3在AI音箱上流畅运行,必须经过严格的优化流程,这不仅仅是代码层面的调整,更是硬件与算法的深度协同。
模型量化与剪枝
通常采用INT8量化技术,将32位浮点数转换为8位整数,这一过程能大幅减少模型体积,同时保持精度损失在可接受范围内,多数情况下,量化后的模型体积可缩减至原来的四分之一,推理速度提升两倍以上。
硬件加速引擎适配
不同品牌的AI芯片拥有各自的加速库,如瑞芯微的RKNN、华为的CANN或高通的SNPE,开发者需要针对特定硬件进行算子优化,确保卷积层和激活层能充分利用NPU算力。
物体检测在智能家居中的核心应用场景
AI音箱结合YOLOv3物体检测,不再是简单的“听令行事”,而是实现了“所见即所控”,这种技术融合极大地拓展了智能家居的应用边界。
儿童与宠物看护场景
这是目前市场反馈最积极的领域之一,家长通过AI音箱屏幕或配套App,可以实时查看家中情况。
- 哭声检测联动:当检测到婴儿床附近有异常动静,音箱自动播放白噪音或通知手机。
- 宠物行为分析:识别猫狗是否在禁区活动,如厨房或沙发,并发送提醒。
- 跌倒检测:针对老年用户,识别跌倒姿态并紧急呼叫联系人。
安防监控联动
传统的安防摄像头往往依赖云端分析,延迟高且隐私风险大,本地化部署YOLOv3后,AI音箱可作为家庭安防中枢。
- 陌生人识别:在门口区域检测到非家庭成员时,立即推送警报。
- 异常物品检测:识别遗留包裹或可疑物品,防止盗窃或误报。
- 火灾烟雾预警:结合视觉特征,早期发现烟雾或火焰迹象,比传统烟感更直观。
个性化交互体验
物体检测让音箱能“认识”用户,通过人脸识别,不同家庭成员登录后可获取个性化的日程安排、音乐推荐或健康数据,这种千人千面的体验,是语音识别无法单独实现的。
2026年AI音箱市场选型与价格对比
对于消费者和开发者而言,了解不同层级产品的技术差异至关重要,市场上主流产品可分为三个梯队,各自对应不同的技术实现路径。
| 产品梯队 | 代表技术特征 | 典型价格区间 | 适用场景 |
|---|---|---|---|
| 入门级 | 纯语音交互,无视觉或简单红外感应 | 100-300元 | 基础控制、闹钟、资讯查询 |
| 进阶级 | 集成低分辨率摄像头,运行轻量YOLO模型 | 300-800元 | 儿童看护、简单手势控制、安防提醒 |
| 旗舰级 | 高分辨率多摄,支持复杂场景理解与大模型联动 | 1000元以上 | 全屋智能中枢、复杂手势识别、情感交互 |
如何判断AI音箱的物体检测能力?
用户在选购时,不应只看参数表上的“支持AI视觉”,而应关注以下细节:
- 本地处理能力:是否支持离线物体识别?依赖云端意味着断网即失效,且隐私泄露风险高。
- 识别类别数量:能否识别常见家居物品(如水杯、书本、宠物)?还是仅支持人脸?
- 响应速度:从触发指令到反馈结果的时间,应在1秒以内,否则体验割裂。
部署与实操指南:从零搭建YOLOv3检测系统
对于开发者而言,将YOLOv3部署到AI音箱或类似嵌入式设备,需要遵循标准化的工程流程,以下以常见的Linux嵌入式环境为例,简述关键步骤。
环境准备与模型转换
需要获取训练好的YOLOv3权重文件(.weights),由于嵌入式设备通常不支持PyTorch或TensorFlow的原生推理,必须将其转换为特定格式。
- 模型导出:使用Darknet或ONNX工具将.weights转换为ONNX格式。
- 格式转换:利用芯片厂商提供的转换工具(如rknn-toolkit),将ONNX模型转换为设备专用的二进制格式(如.rknn)。
- 量化设置:在转换过程中启用动态量化或静态量化,指定校准数据集以优化精度。
推理引擎集成
转换完成后,需在应用程序中集成推理引擎。
- 加载模型:使用API读取.rknn文件到内存。
- 数据预处理:将摄像头采集的图像Resize到416×416,并进行归一化处理。
- 执行推理:调用NPU接口执行前向传播,获取输出张量。
- 后处理:对输出进行非极大值抑制(NMS),过滤重叠框,保留置信度最高的检测结果。
性能调优技巧
在实际运行中,可能会遇到帧率不足的问题,此时可尝试以下优化手段:
- 降低分辨率:将输入图像Resize至320×320,虽精度略有下降,但速度显著提升。
- 跳帧处理:并非每帧都进行推理,可采用隔帧检测策略,如每3帧检测一次。
- ROI区域限制:仅对画面中的特定区域(如门口、桌面)进行推理,减少计算量。
YOLOv3的演进与替代方案
虽然YOLOv3在2026年仍具生命力,但技术迭代从未停止,随着端侧算力的提升,更先进的模型正在逐步渗透。
小模型与大模型的融合
未来的趋势并非单一模型的替换,而是混合架构,YOLOv3负责快速、低精度的初步筛选,识别出感兴趣区域(ROI),再由轻量级大模型进行精细分类或语义理解,这种分工协作模式,既能保证实时性,又能提升交互的智能程度。
隐私保护的强化
随着用户对隐私关注的提升,本地化处理将成为标配,YOLOv3的本地化部署优势在于,所有图像数据无需上传云端,仅在设备内部完成推理,从根本上杜绝了数据泄露风险,据工信部数据,本地化AI处理已成为智能家居隐私合规的重要方向。
常见问题解答(Q&A)
AI音箱使用YOLOv3物体检测主要解决什么痛点?
主要解决传统语音交互缺乏上下文感知能力的问题,通过视觉辅助,设备能理解用户所处的环境和状态,从而提供更主动、更精准的服务,如自动识别用户是否在烹饪并调整音量,或识别到老人跌倒并报警。
2026年市面上支持YOLOv3的AI音箱价格大概是多少?
目前支持具备一定物体检测能力的AI音箱,价格主要集中在300元至800元之间,入门级产品多为纯语音,不具备视觉检测;而集成摄像头并支持本地推理的产品,因涉及额外的硬件成本和算法优化,价格相对较高,但性价比优于高端旗舰机型。
YOLOv3在AI音箱上的推理延迟通常是多少?
在主流嵌入式芯片(如瑞芯微RK3568或类似性能平台)上,经过INT8量化优化的YOLOv3模型,单帧推理时间通常在50毫秒至150毫秒之间,加上图像采集和后处理时间,整体端到端延迟可控制在200毫秒以内,满足实时交互需求。
首发原创文章,作者:王坚,如若转载,请注明出处:https://idctop.com/article/332062.html